> ## Documentation Index
> Fetch the complete documentation index at: https://docs.comfy.org/llms.txt
> Use this file to discover all available pages before exploring further.
# Luma Text to Video - ComfyUI Native Node Documentation
> A node that converts text descriptions to videos using Luma AI
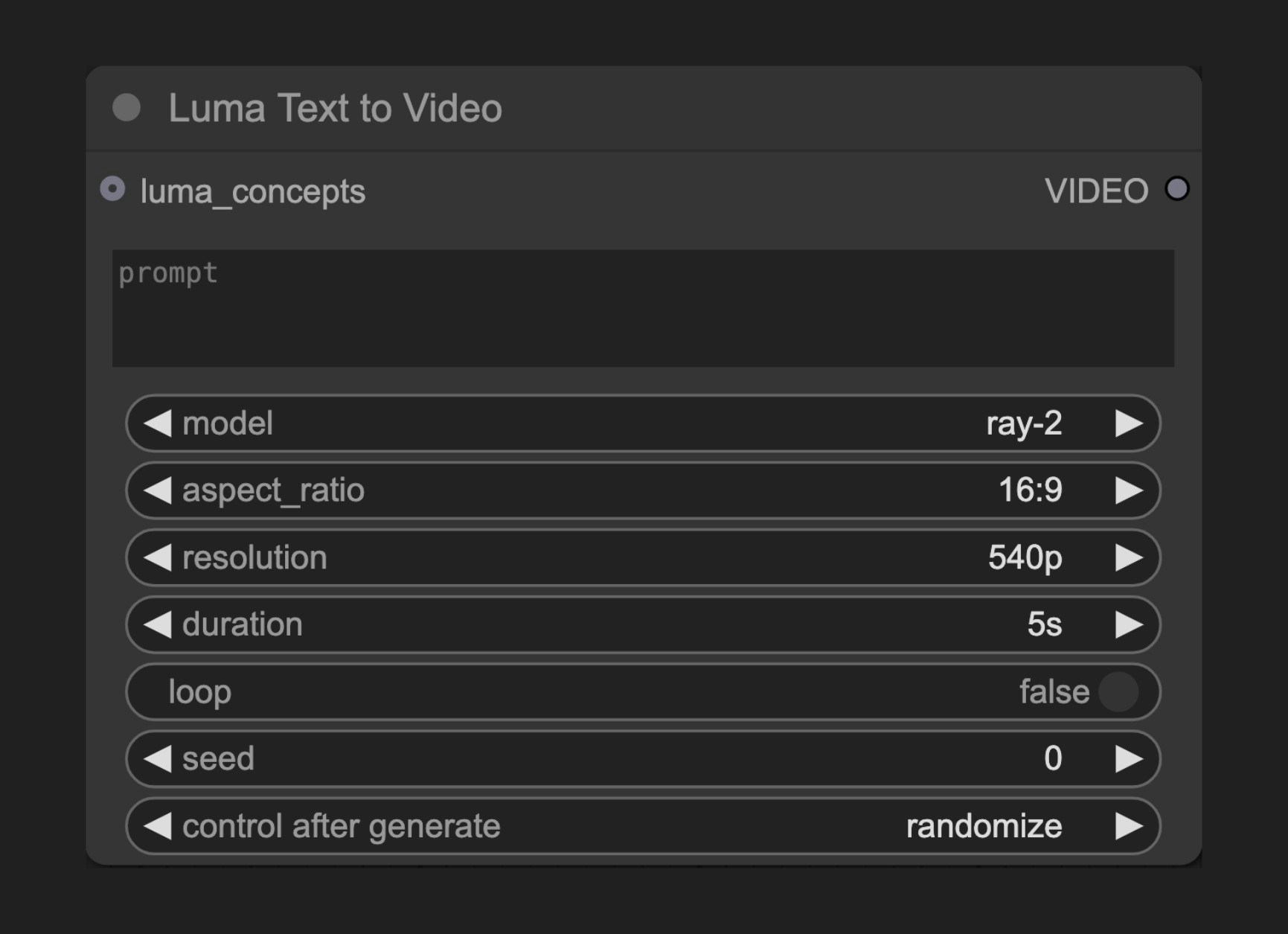 The Luma Text to Video node lets you create high-quality, smooth videos from text descriptions using Luma AI's video generation technology.
## Node Function
This node connects to Luma AI's text-to-video API, allowing users to generate dynamic video content from detailed text prompts.
## Parameters
### Basic Parameters
| Parameter | Type | Default | Description |
| ------------- | ------- | -------------- | ------------------------------------------------------- |
| prompt | string | "" | Text prompt describing the video content to generate |
| model | select | - | Video generation model to use |
| aspect\_ratio | select | "ratio\_16\_9" | Video aspect ratio |
| resolution | select | "res\_540p" | Video resolution |
| duration | select | - | Video length options |
| loop | boolean | False | Whether to loop the video |
| seed | integer | 0 | Seed value for node rerun, results are nondeterministic |
When using Ray 1.6 model, duration and resolution parameters will not take effect.
### Optional Parameters
| Parameter | Type | Description |
| -------------- | -------------- | -------------------------------------------------------- |
| luma\_concepts | LUMA\_CONCEPTS | Camera concepts to control motion via Luma Concepts node |
### Output
| Output | Type | Description |
| ------ | ----- | --------------- |
| VIDEO | video | Generated video |
## Usage Example
Luma Text to Video Workflow Example
## Source Code
\[Node source code (Updated on 2025-05-03)]
```python theme={null}
class LumaTextToVideoGenerationNode(ComfyNodeABC):
"""
Generates videos synchronously based on prompt and output_size.
"""
RETURN_TYPES = (IO.VIDEO,)
DESCRIPTION = cleandoc(__doc__ or "") # Handle potential None value
FUNCTION = "api_call"
API_NODE = True
CATEGORY = "api node/video/Luma"
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"prompt": (
IO.STRING,
{
"multiline": True,
"default": "",
"tooltip": "Prompt for the video generation",
},
),
"model": ([model.value for model in LumaVideoModel],),
"aspect_ratio": (
[ratio.value for ratio in LumaAspectRatio],
{
"default": LumaAspectRatio.ratio_16_9,
},
),
"resolution": (
[resolution.value for resolution in LumaVideoOutputResolution],
{
"default": LumaVideoOutputResolution.res_540p,
},
),
"duration": ([dur.value for dur in LumaVideoModelOutputDuration],),
"loop": (
IO.BOOLEAN,
{
"default": False,
},
),
"seed": (
IO.INT,
{
"default": 0,
"min": 0,
"max": 0xFFFFFFFFFFFFFFFF,
"control_after_generate": True,
"tooltip": "Seed to determine if node should re-run; actual results are nondeterministic regardless of seed.",
},
),
},
"optional": {
"luma_concepts": (
LumaIO.LUMA_CONCEPTS,
{
"tooltip": "Optional Camera Concepts to dictate camera motion via the Luma Concepts node."
},
),
},
"hidden": {
"auth_token": "AUTH_TOKEN_COMFY_ORG",
},
}
def api_call(
self,
prompt: str,
model: str,
aspect_ratio: str,
resolution: str,
duration: str,
loop: bool,
seed,
luma_concepts: LumaConceptChain = None,
auth_token=None,
**kwargs,
):
duration = duration if model != LumaVideoModel.ray_1_6 else None
resolution = resolution if model != LumaVideoModel.ray_1_6 else None
operation = SynchronousOperation(
endpoint=ApiEndpoint(
path="/proxy/luma/generations",
method=HttpMethod.POST,
request_model=LumaGenerationRequest,
response_model=LumaGeneration,
),
request=LumaGenerationRequest(
prompt=prompt,
model=model,
resolution=resolution,
aspect_ratio=aspect_ratio,
duration=duration,
loop=loop,
concepts=luma_concepts.create_api_model() if luma_concepts else None,
),
auth_token=auth_token,
)
response_api: LumaGeneration = operation.execute()
operation = PollingOperation(
poll_endpoint=ApiEndpoint(
path=f"/proxy/luma/generations/{response_api.id}",
method=HttpMethod.GET,
request_model=EmptyRequest,
response_model=LumaGeneration,
),
completed_statuses=[LumaState.completed],
failed_statuses=[LumaState.failed],
status_extractor=lambda x: x.state,
auth_token=auth_token,
)
response_poll = operation.execute()
vid_response = requests.get(response_poll.assets.video)
return (VideoFromFile(BytesIO(vid_response.content)),)
```
The Luma Text to Video node lets you create high-quality, smooth videos from text descriptions using Luma AI's video generation technology.
## Node Function
This node connects to Luma AI's text-to-video API, allowing users to generate dynamic video content from detailed text prompts.
## Parameters
### Basic Parameters
| Parameter | Type | Default | Description |
| ------------- | ------- | -------------- | ------------------------------------------------------- |
| prompt | string | "" | Text prompt describing the video content to generate |
| model | select | - | Video generation model to use |
| aspect\_ratio | select | "ratio\_16\_9" | Video aspect ratio |
| resolution | select | "res\_540p" | Video resolution |
| duration | select | - | Video length options |
| loop | boolean | False | Whether to loop the video |
| seed | integer | 0 | Seed value for node rerun, results are nondeterministic |
When using Ray 1.6 model, duration and resolution parameters will not take effect.
### Optional Parameters
| Parameter | Type | Description |
| -------------- | -------------- | -------------------------------------------------------- |
| luma\_concepts | LUMA\_CONCEPTS | Camera concepts to control motion via Luma Concepts node |
### Output
| Output | Type | Description |
| ------ | ----- | --------------- |
| VIDEO | video | Generated video |
## Usage Example
Luma Text to Video Workflow Example
## Source Code
\[Node source code (Updated on 2025-05-03)]
```python theme={null}
class LumaTextToVideoGenerationNode(ComfyNodeABC):
"""
Generates videos synchronously based on prompt and output_size.
"""
RETURN_TYPES = (IO.VIDEO,)
DESCRIPTION = cleandoc(__doc__ or "") # Handle potential None value
FUNCTION = "api_call"
API_NODE = True
CATEGORY = "api node/video/Luma"
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"prompt": (
IO.STRING,
{
"multiline": True,
"default": "",
"tooltip": "Prompt for the video generation",
},
),
"model": ([model.value for model in LumaVideoModel],),
"aspect_ratio": (
[ratio.value for ratio in LumaAspectRatio],
{
"default": LumaAspectRatio.ratio_16_9,
},
),
"resolution": (
[resolution.value for resolution in LumaVideoOutputResolution],
{
"default": LumaVideoOutputResolution.res_540p,
},
),
"duration": ([dur.value for dur in LumaVideoModelOutputDuration],),
"loop": (
IO.BOOLEAN,
{
"default": False,
},
),
"seed": (
IO.INT,
{
"default": 0,
"min": 0,
"max": 0xFFFFFFFFFFFFFFFF,
"control_after_generate": True,
"tooltip": "Seed to determine if node should re-run; actual results are nondeterministic regardless of seed.",
},
),
},
"optional": {
"luma_concepts": (
LumaIO.LUMA_CONCEPTS,
{
"tooltip": "Optional Camera Concepts to dictate camera motion via the Luma Concepts node."
},
),
},
"hidden": {
"auth_token": "AUTH_TOKEN_COMFY_ORG",
},
}
def api_call(
self,
prompt: str,
model: str,
aspect_ratio: str,
resolution: str,
duration: str,
loop: bool,
seed,
luma_concepts: LumaConceptChain = None,
auth_token=None,
**kwargs,
):
duration = duration if model != LumaVideoModel.ray_1_6 else None
resolution = resolution if model != LumaVideoModel.ray_1_6 else None
operation = SynchronousOperation(
endpoint=ApiEndpoint(
path="/proxy/luma/generations",
method=HttpMethod.POST,
request_model=LumaGenerationRequest,
response_model=LumaGeneration,
),
request=LumaGenerationRequest(
prompt=prompt,
model=model,
resolution=resolution,
aspect_ratio=aspect_ratio,
duration=duration,
loop=loop,
concepts=luma_concepts.create_api_model() if luma_concepts else None,
),
auth_token=auth_token,
)
response_api: LumaGeneration = operation.execute()
operation = PollingOperation(
poll_endpoint=ApiEndpoint(
path=f"/proxy/luma/generations/{response_api.id}",
method=HttpMethod.GET,
request_model=EmptyRequest,
response_model=LumaGeneration,
),
completed_statuses=[LumaState.completed],
failed_statuses=[LumaState.failed],
status_extractor=lambda x: x.state,
auth_token=auth_token,
)
response_poll = operation.execute()
vid_response = requests.get(response_poll.assets.video)
return (VideoFromFile(BytesIO(vid_response.content)),)
```