 ## Wan2.2 TI2V 5B ハイブリッドバージョンワークフロー例
## Wan2.2 TI2V 5B ハイブリッドバージョンワークフロー例
JSON ワークフローファイルをダウンロード
Run on Comfy Cloud
### 2. モデルの手動ダウンロード **Diffusion Model** * [wan2.2\_ti2v\_5B\_fp16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_ti2v_5B_fp16.safetensors) **VAE** * [wan2.2\_vae.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/vae/wan2.2_vae.safetensors) **Text Encoder** * [umt5\_xxl\_fp8\_e4m3fn\_scaled.safetensors](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors) ``` ComfyUI/ ├───📂 models/ │ ├───📂 diffusion_models/ │ │ └───wan2.2_ti2v_5B_fp16.safetensors │ ├───📂 text_encoders/ │ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors │ └───📂 vae/ │ └── wan2.2_vae.safetensors ``` ### 3. 手順に従う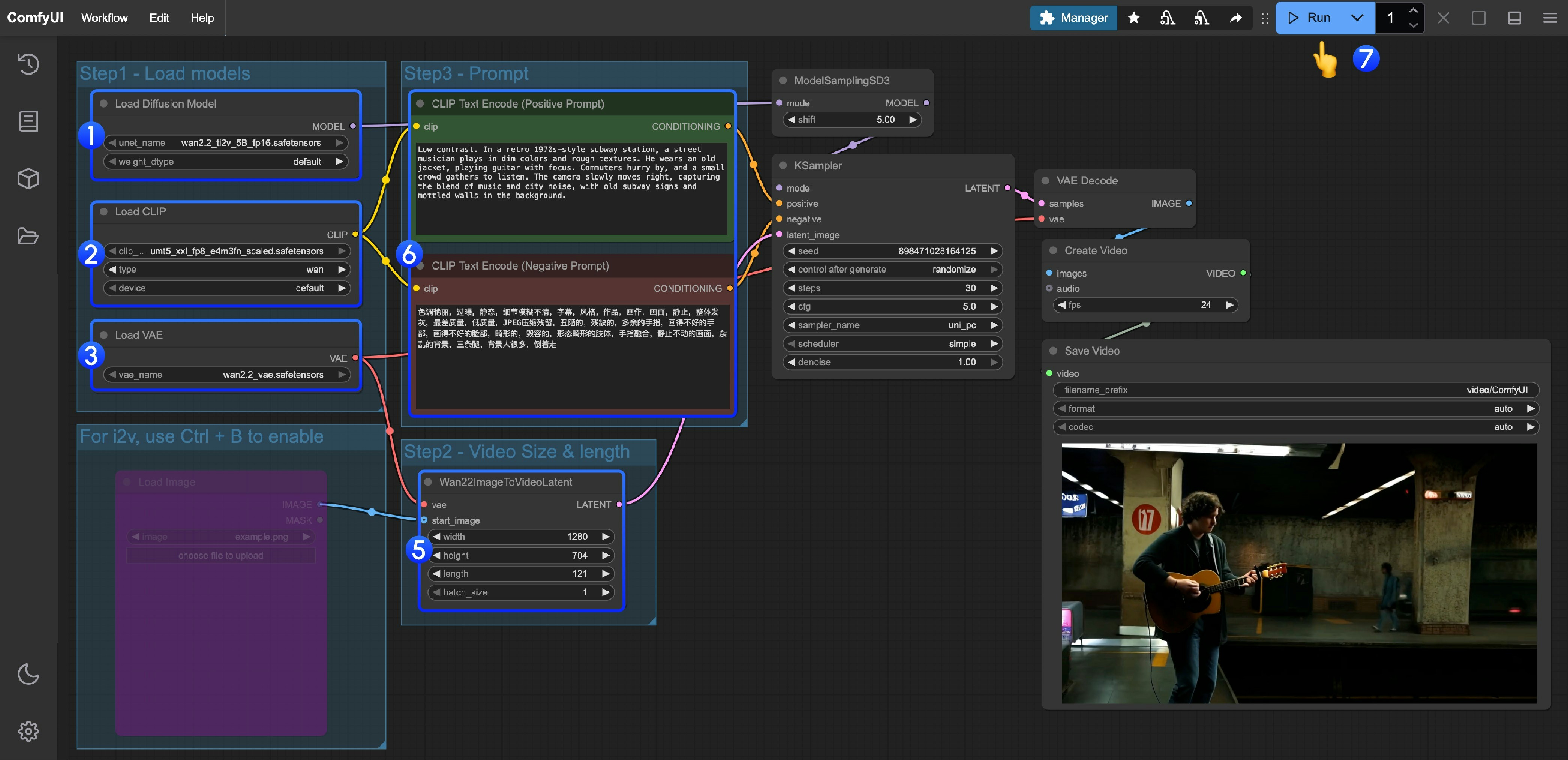 1. `Load Diffusion Model` ノードが `wan2.2_ti2v_5B_fp16.safetensors` モデルを読み込んでいることを確認してください。
2. `Load CLIP` ノードが `umt5_xxl_fp8_e4m3fn_scaled.safetensors` モデルを読み込んでいることを確認してください。
3. `Load VAE` ノードが `wan2.2_vae.safetensors` モデルを読み込んでいることを確認してください。
4. (オプション)画像から動画の生成を行う必要がある場合は、ショートカット Ctrl+B を使用して `Load image` ノードを有効にし、画像をアップロードできます。
5. (オプション)`Wan22ImageToVideoLatent` ノードで、サイズ設定と動画の総フレーム数(`length`)を調整できます。
6. (オプション)プロンプト(ポジティブおよびネガティブ)を変更する必要がある場合は、手順 5 の `CLIP Text Encoder` ノードで変更してください。
7. `Run` ボタンをクリックするか、ショートカット `Ctrl(cmd) + Enter` を使用して動画生成を実行してください。
## Wan2.2 14B T2V テキストから動画ワークフロー例
### 1. ワークフローファイル
ComfyUI を最新バージョンに更新し、メニュー `Workflow` -> `Browse Templates` -> `Video` から「Wan2.2 14B T2V」を見つけてワークフローを読み込んでください。
または、ComfyUI を最新バージョンに更新した後、以下の動画をダウンロードして ComfyUI にドラッグし、ワークフローを読み込んでください。
1. `Load Diffusion Model` ノードが `wan2.2_ti2v_5B_fp16.safetensors` モデルを読み込んでいることを確認してください。
2. `Load CLIP` ノードが `umt5_xxl_fp8_e4m3fn_scaled.safetensors` モデルを読み込んでいることを確認してください。
3. `Load VAE` ノードが `wan2.2_vae.safetensors` モデルを読み込んでいることを確認してください。
4. (オプション)画像から動画の生成を行う必要がある場合は、ショートカット Ctrl+B を使用して `Load image` ノードを有効にし、画像をアップロードできます。
5. (オプション)`Wan22ImageToVideoLatent` ノードで、サイズ設定と動画の総フレーム数(`length`)を調整できます。
6. (オプション)プロンプト(ポジティブおよびネガティブ)を変更する必要がある場合は、手順 5 の `CLIP Text Encoder` ノードで変更してください。
7. `Run` ボタンをクリックするか、ショートカット `Ctrl(cmd) + Enter` を使用して動画生成を実行してください。
## Wan2.2 14B T2V テキストから動画ワークフロー例
### 1. ワークフローファイル
ComfyUI を最新バージョンに更新し、メニュー `Workflow` -> `Browse Templates` -> `Video` から「Wan2.2 14B T2V」を見つけてワークフローを読み込んでください。
または、ComfyUI を最新バージョンに更新した後、以下の動画をダウンロードして ComfyUI にドラッグし、ワークフローを読み込んでください。
JSON ワークフローファイルをダウンロード
Run on Comfy Cloud
### 2. モデルの手動ダウンロード **Diffusion Model** * [wan2.2\_t2v\_high\_noise\_14B\_fp8\_scaled.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors) * [wan2.2\_t2v\_low\_noise\_14B\_fp8\_scaled.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors) **VAE** * [wan\_2.1\_vae.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/vae/wan_2.1_vae.safetensors) **Text Encoder** * [umt5\_xxl\_fp8\_e4m3fn\_scaled.safetensors](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors) ``` ComfyUI/ ├───📂 models/ │ ├───📂 diffusion_models/ │ │ ├─── wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors │ │ └─── wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors │ ├───📂 text_encoders/ │ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors │ └───📂 vae/ │ └── wan_2.1_vae.safetensors ``` ### 3. 手順に従う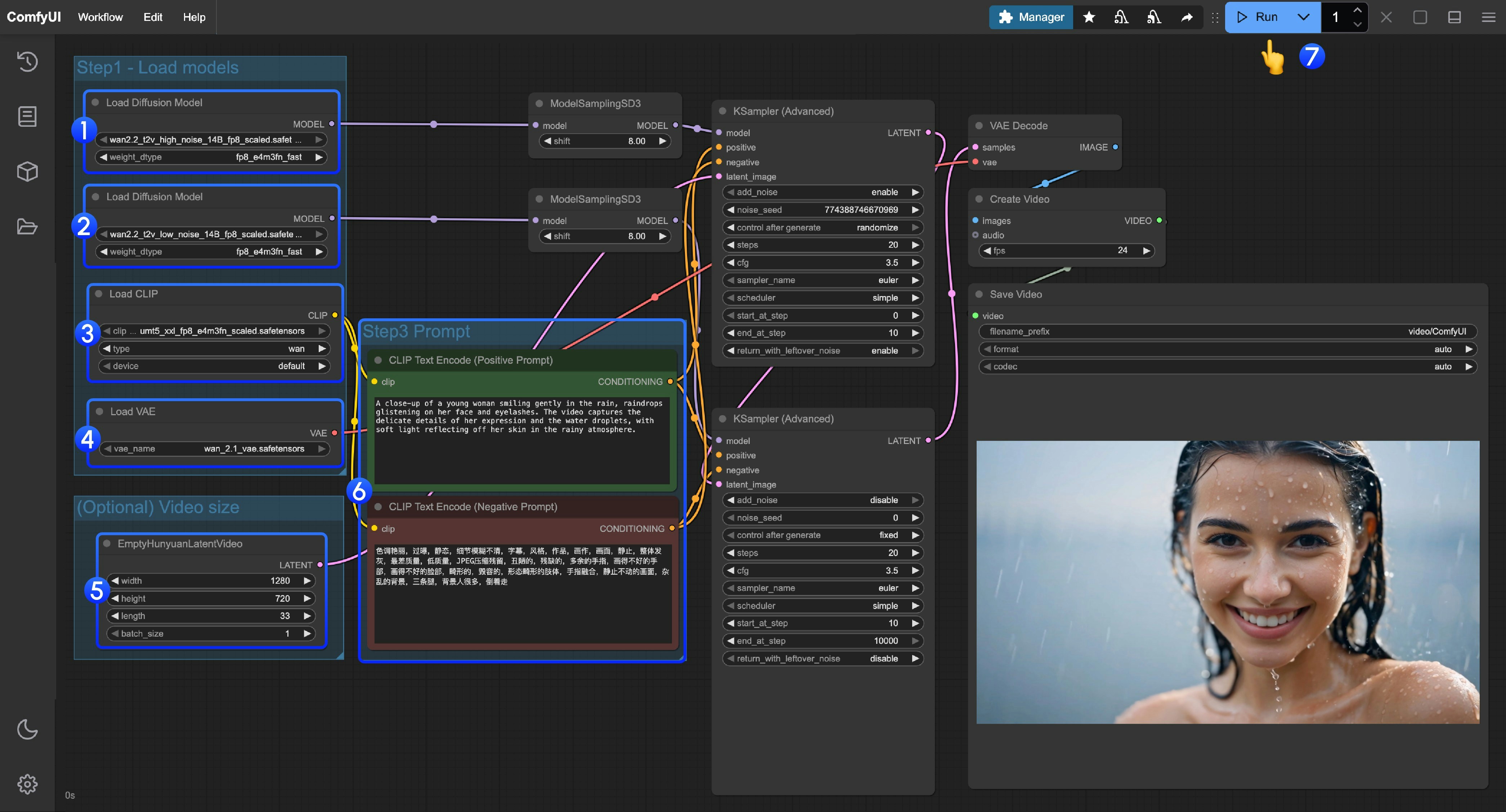 1. 最初の `Load Diffusion Model` ノードが `wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors` モデルを読み込んでいることを確認してください。
2. 2 番目の `Load Diffusion Model` ノードが `wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors` モデルを読み込んでいることを確認してください。
3. `Load CLIP` ノードが `umt5_xxl_fp8_e4m3fn_scaled.safetensors` モデルを読み込んでいることを確認してください。
4. `Load VAE` ノードが `wan_2.1_vae.safetensors` モデルを読み込んでいることを確認してください。
5. (オプション)`EmptyHunyuanLatentVideo` ノードで、サイズ設定と動画の総フレーム数(`length`)を調整できます。
6. (オプション)プロンプト(ポジティブおよびネガティブ)を変更する必要がある場合は、手順 6 の `CLIP Text Encoder` ノードで変更してください。
7. `Run` ボタンをクリックするか、ショートカット `Ctrl(cmd) + Enter` を使用して動画生成を実行してください。
## Wan2.2 14B I2V 画像から動画ワークフロー例
### 1. ワークフローファイル
ComfyUI を最新バージョンに更新し、メニュー `Workflow` -> `Browse Templates` -> `Video` から「Wan2.2 14B I2V」を見つけてワークフローを読み込んでください。
または、ComfyUI を最新バージョンに更新した後、以下の動画をダウンロードして ComfyUI にドラッグし、ワークフローを読み込んでください。
1. 最初の `Load Diffusion Model` ノードが `wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors` モデルを読み込んでいることを確認してください。
2. 2 番目の `Load Diffusion Model` ノードが `wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors` モデルを読み込んでいることを確認してください。
3. `Load CLIP` ノードが `umt5_xxl_fp8_e4m3fn_scaled.safetensors` モデルを読み込んでいることを確認してください。
4. `Load VAE` ノードが `wan_2.1_vae.safetensors` モデルを読み込んでいることを確認してください。
5. (オプション)`EmptyHunyuanLatentVideo` ノードで、サイズ設定と動画の総フレーム数(`length`)を調整できます。
6. (オプション)プロンプト(ポジティブおよびネガティブ)を変更する必要がある場合は、手順 6 の `CLIP Text Encoder` ノードで変更してください。
7. `Run` ボタンをクリックするか、ショートカット `Ctrl(cmd) + Enter` を使用して動画生成を実行してください。
## Wan2.2 14B I2V 画像から動画ワークフロー例
### 1. ワークフローファイル
ComfyUI を最新バージョンに更新し、メニュー `Workflow` -> `Browse Templates` -> `Video` から「Wan2.2 14B I2V」を見つけてワークフローを読み込んでください。
または、ComfyUI を最新バージョンに更新した後、以下の動画をダウンロードして ComfyUI にドラッグし、ワークフローを読み込んでください。
JSON ワークフローファイルをダウンロード
Run on Comfy Cloud
以下の画像を入力として使用できます:  ### 2. モデルの手動ダウンロード **Diffusion Model** * [wan2.2\_i2v\_high\_noise\_14B\_fp16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_i2v_high_noise_14B_fp16.safetensors) * [wan2.2\_i2v\_low\_noise\_14B\_fp16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_i2v_low_noise_14B_fp16.safetensors) **VAE** * [wan\_2.1\_vae.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/vae/wan_2.1_vae.safetensors) **Text Encoder** * [umt5\_xxl\_fp8\_e4m3fn\_scaled.safetensors](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors) ``` ComfyUI/ ├───📂 models/ │ ├───📂 diffusion_models/ │ │ ├─── wan2.2_i2v_low_noise_14B_fp16.safetensors │ │ └─── wan2.2_i2v_high_noise_14B_fp16.safetensors │ ├───📂 text_encoders/ │ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors │ └───📂 vae/ │ └── wan_2.1_vae.safetensors ``` ### 3. 手順に従う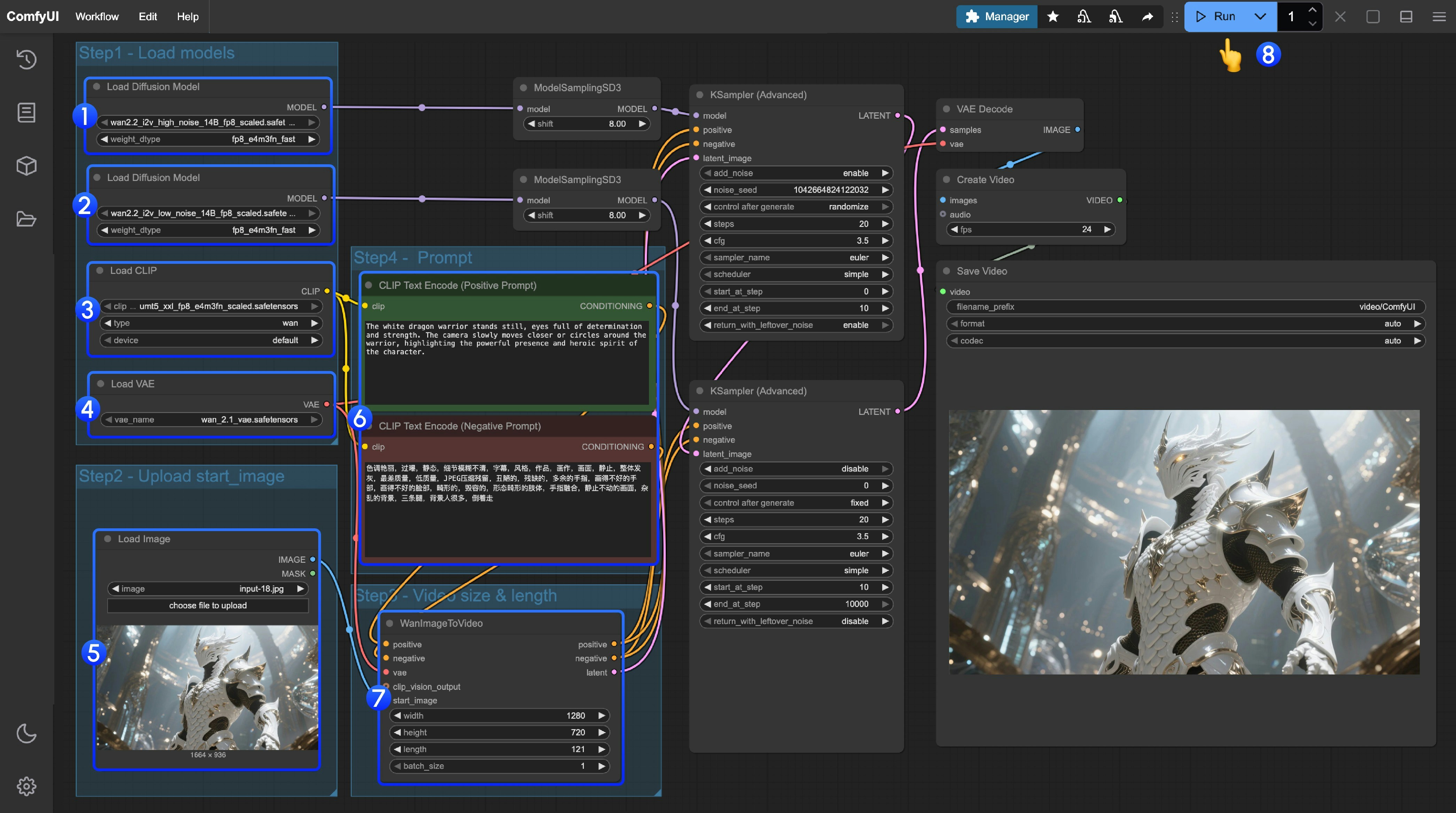 1. 最初の `Load Diffusion Model` ノードが `wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors` モデルを読み込んでいることを確認してください。
2. 2 番目の `Load Diffusion Model` ノードが `wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors` モデルを読み込んでいることを確認してください。
3. `Load CLIP` ノードが `umt5_xxl_fp8_e4m3fn_scaled.safetensors` モデルを読み込んでいることを確認してください。
4. `Load VAE` ノードが `wan_2.1_vae.safetensors` モデルを読み込んでいることを確認してください。
5. `Load Image` ノードで、起始フレームとして使用する画像をアップロードしてください。
6. プロンプト(ポジティブおよびネガティブ)を変更する必要がある場合は、手順 6 の `CLIP Text Encoder` ノードで変更してください。
7. (オプション)`EmptyHunyuanLatentVideo` で、サイズ設定と動画の総フレーム数(`length`)を調整できます。
8. `Run` ボタンをクリックするか、ショートカット `Ctrl(cmd) + Enter` を使用して動画生成を実行してください。
## Wan2.2 14B FLF2V ワークフロー例
最初と最後のフレームのワークフローは、I2V セクションと同じモデル場所を使用します。
### 1. ワークフローと入力素材の準備
以下の動画または JSON ワークフローをダウンロードし、ComfyUI で開いてください。
1. 最初の `Load Diffusion Model` ノードが `wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors` モデルを読み込んでいることを確認してください。
2. 2 番目の `Load Diffusion Model` ノードが `wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors` モデルを読み込んでいることを確認してください。
3. `Load CLIP` ノードが `umt5_xxl_fp8_e4m3fn_scaled.safetensors` モデルを読み込んでいることを確認してください。
4. `Load VAE` ノードが `wan_2.1_vae.safetensors` モデルを読み込んでいることを確認してください。
5. `Load Image` ノードで、起始フレームとして使用する画像をアップロードしてください。
6. プロンプト(ポジティブおよびネガティブ)を変更する必要がある場合は、手順 6 の `CLIP Text Encoder` ノードで変更してください。
7. (オプション)`EmptyHunyuanLatentVideo` で、サイズ設定と動画の総フレーム数(`length`)を調整できます。
8. `Run` ボタンをクリックするか、ショートカット `Ctrl(cmd) + Enter` を使用して動画生成を実行してください。
## Wan2.2 14B FLF2V ワークフロー例
最初と最後のフレームのワークフローは、I2V セクションと同じモデル場所を使用します。
### 1. ワークフローと入力素材の準備
以下の動画または JSON ワークフローをダウンロードし、ComfyUI で開いてください。
JSON ワークフローをダウンロード
Run on Comfy Cloud
以下の画像を入力素材としてダウンロードしてください:   ### 2. 手順に従う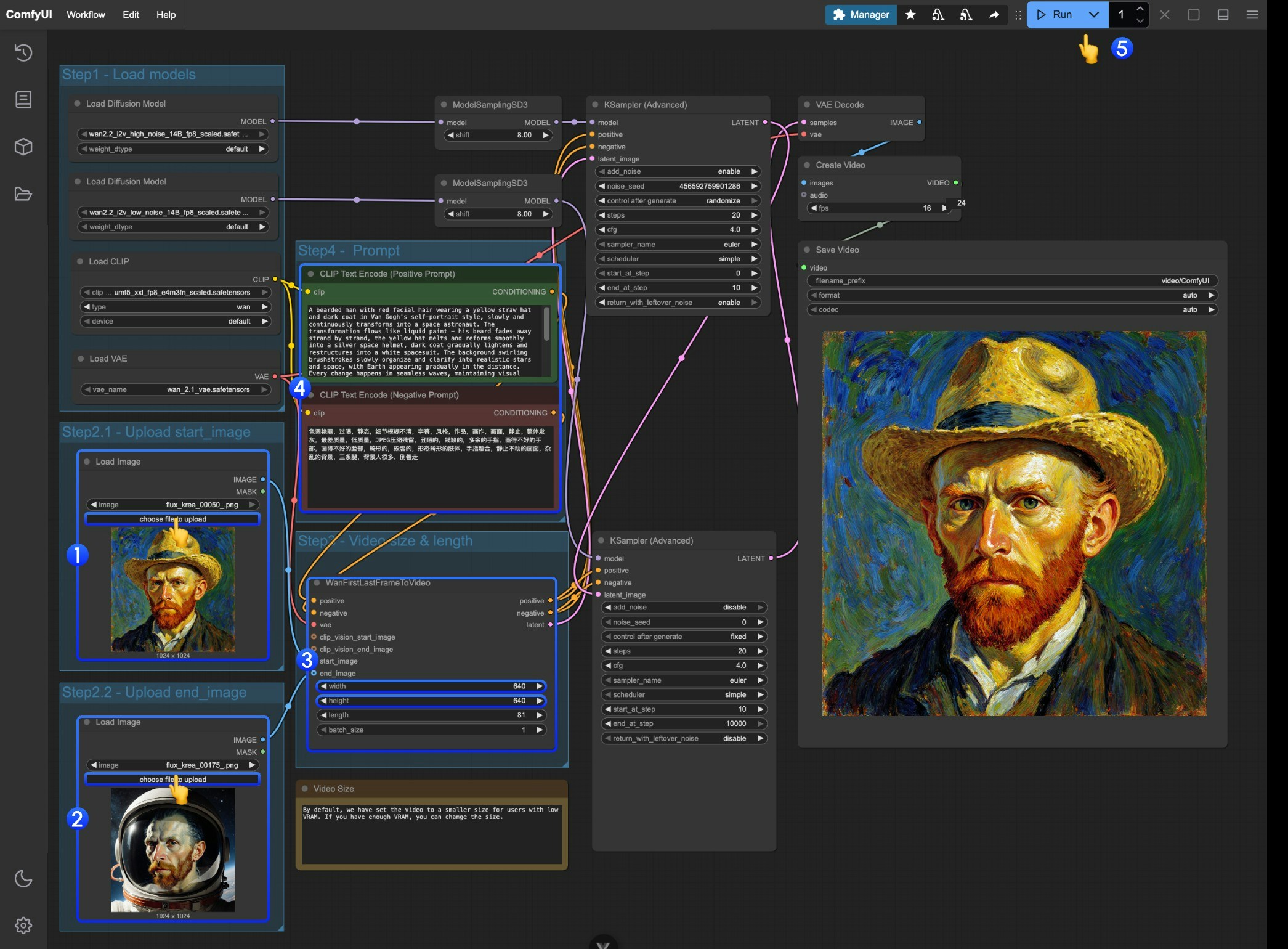 1. 最初の `Load Image` ノードで、起始フレームとして使用する画像をアップロードしてください。
2. 2 番目の `Load Image` ノードで、終了フレームとして使用する画像をアップロードしてください。
3. `WanFirstLastFrameToVideo` ノードでサイズ設定を調整してください。
* デフォルトでは、低 VRAM ユーザーがリソースを使いすぎないように、比較的小さいサイズが設定されています。
* 十分な VRAM がある場合は、720P 程度の解像度を試すことができます。
4. 最初と最後のフレームに応じて、適切なプロンプトを作成してください。
5. `Run` ボタンをクリックするか、ショートカット `Ctrl(cmd) + Enter` を使用して動画生成を実行してください。
## コミュニティリソース
### GGUF バージョン
* [bullerwins/Wan2.2-I2V-A14B-GGUF/](https://huggingface.co/bullerwins/Wan2.2-I2V-A14B-GGUF/)
* [bullerwins/Wan2.2-T2V-A14B-GGUF](https://huggingface.co/bullerwins/Wan2.2-T2V-A14B-GGUF)
* [QuantStack/Wan2.2 GGUFs](https://huggingface.co/collections/QuantStack/wan22-ggufs-6887ec891bdea453a35b95f3)
**カスタムノード**
[City96/ComfyUI-GGUF](https://github.com/city96/ComfyUI-GGUF)
### WanVideoWrapper
[Kijai/ComfyUI-WanVideoWrapper](https://github.com/kijai/ComfyUI-WanVideoWrapper)
**Wan2.2 モデル**
[Kijai/WanVideo\_comfy\_fp8\_scaled](https://hf-mirror.com/Kijai/WanVideo_comfy_fp8_scaled)
**Wan2.1 モデル**
[Kijai/WanVideo\_comfy/Lightx2v](https://huggingface.co/Kijai/WanVideo_comfy/tree/main/Lightx2v)
**Lightx2v 4steps LoRA**
* [Wan2.2-T2V-A14B-4steps-lora-rank64-V1](https://huggingface.co/lightx2v/Wan2.2-Lightning/tree/main/Wan2.2-T2V-A14B-4steps-lora-rank64-V1)
1. 最初の `Load Image` ノードで、起始フレームとして使用する画像をアップロードしてください。
2. 2 番目の `Load Image` ノードで、終了フレームとして使用する画像をアップロードしてください。
3. `WanFirstLastFrameToVideo` ノードでサイズ設定を調整してください。
* デフォルトでは、低 VRAM ユーザーがリソースを使いすぎないように、比較的小さいサイズが設定されています。
* 十分な VRAM がある場合は、720P 程度の解像度を試すことができます。
4. 最初と最後のフレームに応じて、適切なプロンプトを作成してください。
5. `Run` ボタンをクリックするか、ショートカット `Ctrl(cmd) + Enter` を使用して動画生成を実行してください。
## コミュニティリソース
### GGUF バージョン
* [bullerwins/Wan2.2-I2V-A14B-GGUF/](https://huggingface.co/bullerwins/Wan2.2-I2V-A14B-GGUF/)
* [bullerwins/Wan2.2-T2V-A14B-GGUF](https://huggingface.co/bullerwins/Wan2.2-T2V-A14B-GGUF)
* [QuantStack/Wan2.2 GGUFs](https://huggingface.co/collections/QuantStack/wan22-ggufs-6887ec891bdea453a35b95f3)
**カスタムノード**
[City96/ComfyUI-GGUF](https://github.com/city96/ComfyUI-GGUF)
### WanVideoWrapper
[Kijai/ComfyUI-WanVideoWrapper](https://github.com/kijai/ComfyUI-WanVideoWrapper)
**Wan2.2 モデル**
[Kijai/WanVideo\_comfy\_fp8\_scaled](https://hf-mirror.com/Kijai/WanVideo_comfy_fp8_scaled)
**Wan2.1 モデル**
[Kijai/WanVideo\_comfy/Lightx2v](https://huggingface.co/Kijai/WanVideo_comfy/tree/main/Lightx2v)
**Lightx2v 4steps LoRA**
* [Wan2.2-T2V-A14B-4steps-lora-rank64-V1](https://huggingface.co/lightx2v/Wan2.2-Lightning/tree/main/Wan2.2-T2V-A14B-4steps-lora-rank64-V1)