> ## Documentation Index
> Fetch the complete documentation index at: https://docs.comfy.org/llms.txt
> Use this file to discover all available pages before exploring further.
# ComfyUI 포즈 ControlNet 사용 예시
> 이 가이드에서는 포즈 ControlNet의 기본 개념을 소개하고, 두 번의 생성 방식을 활용해 ComfyUI에서 대형 이미지를 생성하는 방법을 보여드립니다.
## OpenPose 소개
[OpenPose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)는 카네기 멜론 대학(CMU)에서 개발한 오픈소스 실시간 다인종 자세 추정 시스템으로, 컴퓨터 비전 분야에서 중요한 돌파구를 마련했습니다. 이 시스템은 이미지 내 여러 사람을 동시에 감지하며 다음을 캡처합니다:
* **신체 골격**: 머리, 어깨, 팔꿈치, 손목, 엉덩이, 무릎, 발목 등 18개의 주요 관절점
* **얼굴 표정**: 미세한 표정과 얼굴 윤곽을 포착하기 위한 70개의 얼굴 관절점
* **손 세부 정보**: 손가락 위치와 제스처를 정밀하게 표현하기 위한 21개의 손 관절점
* **발 자세**: 서 있는 자세와 움직임의 세부사항을 기록하는 6개의 발 관절점
 AI 이미지 생성에서 OpenPose로 생성된 골격 구조 맵은 ControlNet의 조건 입력으로 작용하며, 생성된 캐릭터의 자세, 행동, 표정을 정밀하게 제어할 수 있게 합니다. 이를 통해 원하는 자세와 동작을 갖춘 현실적인 인물 이미지를 생성할 수 있으며, AI 생성 콘텐츠의 제어 가능성과 실용성을 크게 향상시킵니다. 특히 초기 Stable Diffusion 1.5 시리즈 모델의 경우, OpenPose로 생성된 골격 맵은 캐릭터의 동작, 팔다리, 표정 왜곡 문제를 효과적으로 방지할 수 있습니다.
## ComfyUI 2회차 포즈 ControlNet 사용 예시
### 1. 포즈 ControlNet 워크플로우 자산
아래 워크플로우 이미지를 다운로드하여 ComfyUI로 드래그해 워크플로우를 로드해주세요:

워크플로우 JSON이 메타데이터에 포함된 이미지는 ComfyUI로 직접 드래그하거나, 메뉴 `워크플로우` -> `열기 (ctrl+o)`를 이용해 로드할 수 있습니다. 이 이미지에는 해당 모델의 다운로드 링크가 이미 포함되어 있으며, ComfyUI로 드래그하면 자동으로 다운로드가 요청됩니다.
아래 이미지를 다운로드해 입력으로 사용해주세요:
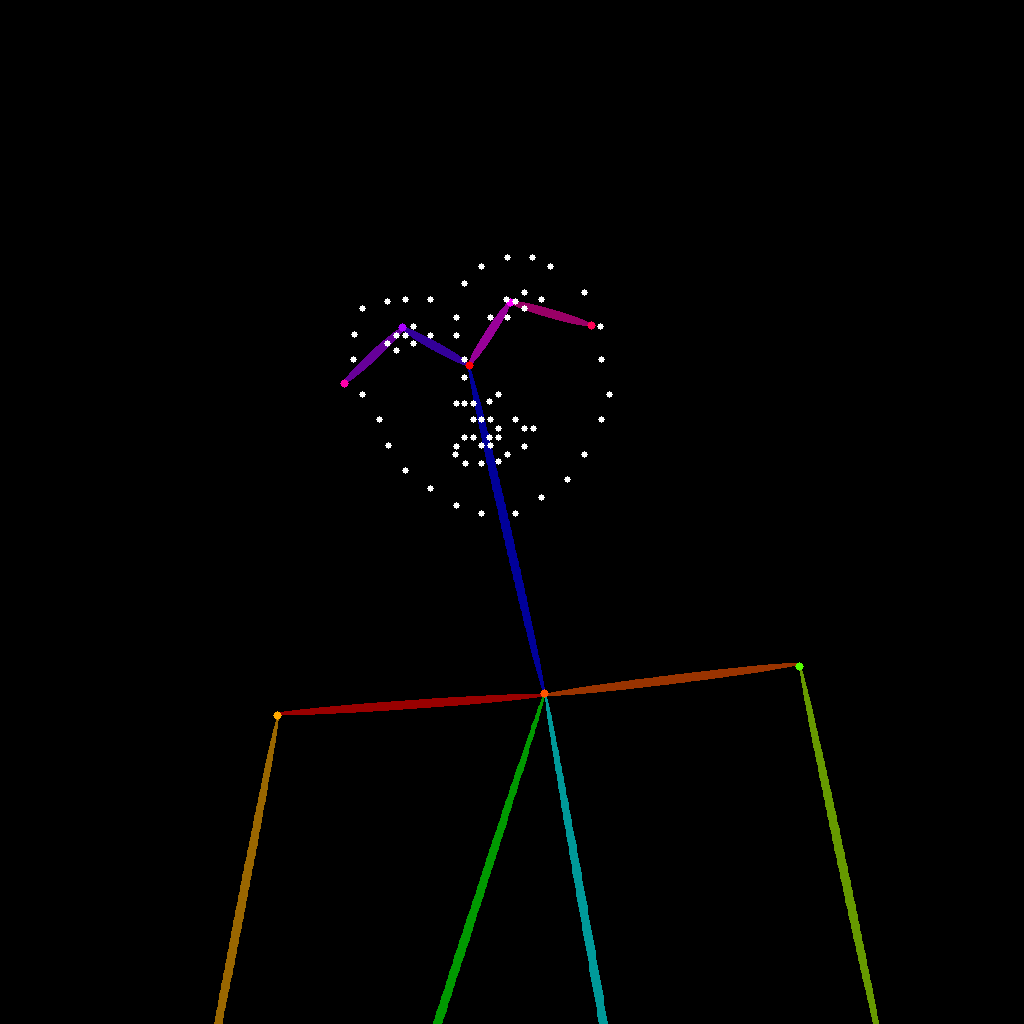
### 2. 수동 모델 설치
네트워크 환경상 해당 모델의 자동 다운로드가 성공적으로 이루어지지 않는다면, 아래 모델을 수동으로 다운로드해 지정된 디렉토리에 배치해주세요:
* [control\_v11p\_sd15\_openpose\_fp16.safetensors](https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/resolve/main/control_v11p_sd15_openpose_fp16.safetensors?download=true)
* [majicmixRealistic\_v7.safetensors](https://civitai.com/api/download/models/176425?type=Model\&format=SafeTensor\&size=pruned\&fp=fp16)
* [japaneseStyleRealistic\_v20.safetensors](https://civitai.com/api/download/models/85426?type=Model\&format=SafeTensor\&size=pruned\&fp=fp16)
* [vae-ft-mse-840000-ema-pruned.safetensors](https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.safetensors?download=true)
```
ComfyUI/
├── models/
│ ├── checkpoints/
│ │ └── majicmixRealistic_v7.safetensors
│ │ └── japaneseStyleRealistic_v20.safetensors
│ ├── vae/
│ │ └── vae-ft-mse-840000-ema-pruned.safetensors
│ └── controlnet/
│ └── control_v11p_sd15_openpose_fp16.safetensors
```
### 3. 단계별 워크플로우 실행
AI 이미지 생성에서 OpenPose로 생성된 골격 구조 맵은 ControlNet의 조건 입력으로 작용하며, 생성된 캐릭터의 자세, 행동, 표정을 정밀하게 제어할 수 있게 합니다. 이를 통해 원하는 자세와 동작을 갖춘 현실적인 인물 이미지를 생성할 수 있으며, AI 생성 콘텐츠의 제어 가능성과 실용성을 크게 향상시킵니다. 특히 초기 Stable Diffusion 1.5 시리즈 모델의 경우, OpenPose로 생성된 골격 맵은 캐릭터의 동작, 팔다리, 표정 왜곡 문제를 효과적으로 방지할 수 있습니다.
## ComfyUI 2회차 포즈 ControlNet 사용 예시
### 1. 포즈 ControlNet 워크플로우 자산
아래 워크플로우 이미지를 다운로드하여 ComfyUI로 드래그해 워크플로우를 로드해주세요:

워크플로우 JSON이 메타데이터에 포함된 이미지는 ComfyUI로 직접 드래그하거나, 메뉴 `워크플로우` -> `열기 (ctrl+o)`를 이용해 로드할 수 있습니다. 이 이미지에는 해당 모델의 다운로드 링크가 이미 포함되어 있으며, ComfyUI로 드래그하면 자동으로 다운로드가 요청됩니다.
아래 이미지를 다운로드해 입력으로 사용해주세요:

### 2. 수동 모델 설치
네트워크 환경상 해당 모델의 자동 다운로드가 성공적으로 이루어지지 않는다면, 아래 모델을 수동으로 다운로드해 지정된 디렉토리에 배치해주세요:
* [control\_v11p\_sd15\_openpose\_fp16.safetensors](https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/resolve/main/control_v11p_sd15_openpose_fp16.safetensors?download=true)
* [majicmixRealistic\_v7.safetensors](https://civitai.com/api/download/models/176425?type=Model\&format=SafeTensor\&size=pruned\&fp=fp16)
* [japaneseStyleRealistic\_v20.safetensors](https://civitai.com/api/download/models/85426?type=Model\&format=SafeTensor\&size=pruned\&fp=fp16)
* [vae-ft-mse-840000-ema-pruned.safetensors](https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.safetensors?download=true)
```
ComfyUI/
├── models/
│ ├── checkpoints/
│ │ └── majicmixRealistic_v7.safetensors
│ │ └── japaneseStyleRealistic_v20.safetensors
│ ├── vae/
│ │ └── vae-ft-mse-840000-ema-pruned.safetensors
│ └── controlnet/
│ └── control_v11p_sd15_openpose_fp16.safetensors
```
### 3. 단계별 워크플로우 실행
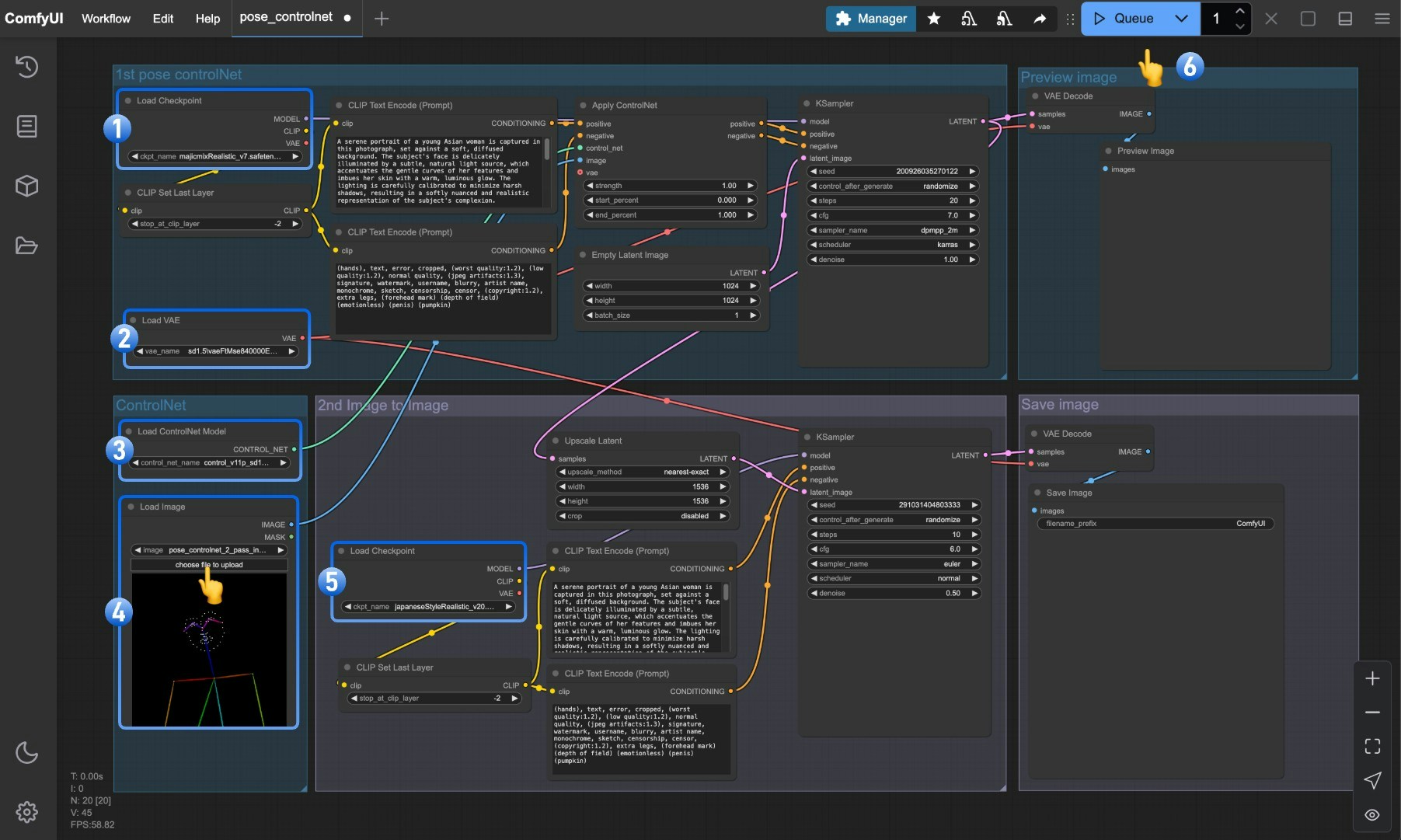 이미지의 숫자 표시에 따라 다음 단계를 따르세요:
1. `Load Checkpoint`가 **majicmixRealistic\_v7.safetensors**를 로드할 수 있도록 확인하세요.
2. `Load VAE`가 **vae-ft-mse-840000-ema-pruned.safetensors**를 로드할 수 있도록 확인하세요.
3. `Load ControlNet Model`이 **control\_v11p\_sd15\_openpose\_fp16.safetensors**를 로드할 수 있도록 확인하세요.
4. `Load Image` 노드의 선택 버튼을 클릭해 앞서 제공한 포즈 입력 이미지를 업로드하거나, 자신만의 OpenPose 골격 맵을 사용하세요.
5. `Load Checkpoint`가 **japaneseStyleRealistic\_v20.safetensors**를 로드할 수 있도록 확인하세요.
6. `Queue` 버튼을 클릭하거나 단축키 `Ctrl(cmd) + Enter`를 사용해 이미지 생성을 실행하세요.
## 포즈 ControlNet 2회차 워크플로우 설명
이 워크플로우는 두 번의 이미지 생성 방식을 사용하며, 이미지 생성 과정을 두 단계로 나눕니다:
### 첫 번째 단계: 기본 자세 이미지 생성
첫 번째 단계에서는 **majicmixRealistic\_v7** 모델과 포즈 ControlNet을 결합해 캐릭터의 기본 자세 이미지를 생성합니다:
1. 먼저 `Load Checkpoint` 노드를 통해 majicmixRealistic\_v7 모델을 로드하세요.
2. `Load ControlNet Model` 노드를 통해 포즈 제어 모델을 로드하세요.
3. 입력된 포즈 이미지를 `Apply ControlNet` 노드에 넣고 긍정 및 부정 프롬프트 조건과 결합하세요.
4. 첫 번째 `KSampler` 노드(보통 20\~30단계 사용)를 통해 기본 캐릭터 자세 이미지를 생성합니다.
5. 첫 번째 단계의 픽셀 공간 이미지는 `VAE Decode`를 통해 얻습니다.
이 단계는 주로 캐릭터의 올바른 자세, 포즈 및 기본 구조에 중점을 두며, 입력된 골격 자세에 맞는 캐릭터를 생성하도록 합니다.
### 두 번째 단계: 스타일 최적화 및 세부사항 강화
두 번째 단계에서는 첫 번째 단계의 출력 이미지를 참고로 하여 **japaneseStyleRealistic\_v20** 모델을 사용해 스타일화와 세부사항 강화를 수행합니다:
1. 첫 번째 단계에서 생성된 이미지는 `Upscale latent` 노드를 통해 더 높은 해상도의 잠재 공간을 생성합니다.
2. 두 번째 `Load Checkpoint`는 세부사항과 스타일에 집중하는 japaneseStyleRealistic\_v20 모델을 로드합니다.
3. 두 번째 `KSampler` 노드는 낮은 `denoise` 강도(보통 0.4\~0.6)를 사용해 첫 번째 단계의 기본 구조를 유지하면서 세부사항을 정교하게 다듬습니다.
4. 마지막으로, 두 번째 `VAE Decode`와 `Save Image` 노드를 통해 더 높은 품질의 고해상도 이미지를 출력합니다.
이 단계는 주로 스타일 일관성과 세부사항의 풍부함, 전체 이미지 품질 향상에 중점을 둡니다.
## 2회차 이미지 생성의 장점
단일 회차 생성과 비교해 2회차 이미지 생성 방식은 다음과 같은 장점을 제공합니다:
1. **더 높은 해상도**: 두 번의 처리를 통해 단일 회차 생성의 한계를 넘어서는 고해상도 이미지를 생성할 수 있습니다.
2. **스타일 혼합**: 서로 다른 모델의 장점을 결합할 수 있어, 첫 번째 단계에서는 사실적인 모델을, 두 번째 단계에서는 스타일리시한 모델을 사용할 수 있습니다.
3. **더 나은 세부사항**: 두 번째 단계에서는 전체 구조를 신경 쓰지 않고 세부사항을 정밀하게 다듬을 수 있습니다.
4. **정밀한 제어**: 첫 번째 단계에서 자세 제어가 완료되면, 두 번째 단계에서는 스타일과 세부사항을 더욱 정교하게 다듬을 수 있습니다.
5. **GPU 부하 경감**: 두 번의 처리를 통해 적은 GPU 리소스로도 고품질의 대형 이미지를 생성할 수 있습니다.
다양한 ControlNet 모델을 혼합하는 기법에 대해 더 자세히 알아보려면 [ControlNet 모델 혼합](/ko/tutorials/controlnet/mixing-controlnets) 튜토리얼을 참조해주세요.
이미지의 숫자 표시에 따라 다음 단계를 따르세요:
1. `Load Checkpoint`가 **majicmixRealistic\_v7.safetensors**를 로드할 수 있도록 확인하세요.
2. `Load VAE`가 **vae-ft-mse-840000-ema-pruned.safetensors**를 로드할 수 있도록 확인하세요.
3. `Load ControlNet Model`이 **control\_v11p\_sd15\_openpose\_fp16.safetensors**를 로드할 수 있도록 확인하세요.
4. `Load Image` 노드의 선택 버튼을 클릭해 앞서 제공한 포즈 입력 이미지를 업로드하거나, 자신만의 OpenPose 골격 맵을 사용하세요.
5. `Load Checkpoint`가 **japaneseStyleRealistic\_v20.safetensors**를 로드할 수 있도록 확인하세요.
6. `Queue` 버튼을 클릭하거나 단축키 `Ctrl(cmd) + Enter`를 사용해 이미지 생성을 실행하세요.
## 포즈 ControlNet 2회차 워크플로우 설명
이 워크플로우는 두 번의 이미지 생성 방식을 사용하며, 이미지 생성 과정을 두 단계로 나눕니다:
### 첫 번째 단계: 기본 자세 이미지 생성
첫 번째 단계에서는 **majicmixRealistic\_v7** 모델과 포즈 ControlNet을 결합해 캐릭터의 기본 자세 이미지를 생성합니다:
1. 먼저 `Load Checkpoint` 노드를 통해 majicmixRealistic\_v7 모델을 로드하세요.
2. `Load ControlNet Model` 노드를 통해 포즈 제어 모델을 로드하세요.
3. 입력된 포즈 이미지를 `Apply ControlNet` 노드에 넣고 긍정 및 부정 프롬프트 조건과 결합하세요.
4. 첫 번째 `KSampler` 노드(보통 20\~30단계 사용)를 통해 기본 캐릭터 자세 이미지를 생성합니다.
5. 첫 번째 단계의 픽셀 공간 이미지는 `VAE Decode`를 통해 얻습니다.
이 단계는 주로 캐릭터의 올바른 자세, 포즈 및 기본 구조에 중점을 두며, 입력된 골격 자세에 맞는 캐릭터를 생성하도록 합니다.
### 두 번째 단계: 스타일 최적화 및 세부사항 강화
두 번째 단계에서는 첫 번째 단계의 출력 이미지를 참고로 하여 **japaneseStyleRealistic\_v20** 모델을 사용해 스타일화와 세부사항 강화를 수행합니다:
1. 첫 번째 단계에서 생성된 이미지는 `Upscale latent` 노드를 통해 더 높은 해상도의 잠재 공간을 생성합니다.
2. 두 번째 `Load Checkpoint`는 세부사항과 스타일에 집중하는 japaneseStyleRealistic\_v20 모델을 로드합니다.
3. 두 번째 `KSampler` 노드는 낮은 `denoise` 강도(보통 0.4\~0.6)를 사용해 첫 번째 단계의 기본 구조를 유지하면서 세부사항을 정교하게 다듬습니다.
4. 마지막으로, 두 번째 `VAE Decode`와 `Save Image` 노드를 통해 더 높은 품질의 고해상도 이미지를 출력합니다.
이 단계는 주로 스타일 일관성과 세부사항의 풍부함, 전체 이미지 품질 향상에 중점을 둡니다.
## 2회차 이미지 생성의 장점
단일 회차 생성과 비교해 2회차 이미지 생성 방식은 다음과 같은 장점을 제공합니다:
1. **더 높은 해상도**: 두 번의 처리를 통해 단일 회차 생성의 한계를 넘어서는 고해상도 이미지를 생성할 수 있습니다.
2. **스타일 혼합**: 서로 다른 모델의 장점을 결합할 수 있어, 첫 번째 단계에서는 사실적인 모델을, 두 번째 단계에서는 스타일리시한 모델을 사용할 수 있습니다.
3. **더 나은 세부사항**: 두 번째 단계에서는 전체 구조를 신경 쓰지 않고 세부사항을 정밀하게 다듬을 수 있습니다.
4. **정밀한 제어**: 첫 번째 단계에서 자세 제어가 완료되면, 두 번째 단계에서는 스타일과 세부사항을 더욱 정교하게 다듬을 수 있습니다.
5. **GPU 부하 경감**: 두 번의 처리를 통해 적은 GPU 리소스로도 고품질의 대형 이미지를 생성할 수 있습니다.
다양한 ControlNet 모델을 혼합하는 기법에 대해 더 자세히 알아보려면 [ControlNet 모델 혼합](/ko/tutorials/controlnet/mixing-controlnets) 튜토리얼을 참조해주세요.