JSON 워크플로우 다운로드
Comfy Cloud에서 실행
다음 이미지와 오디오를 입력으로 다운로드하세요: 입력 오디오 다운로드
### 2. 모델 링크 모델들은 [우리 리포지토리](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged)에서 확인하실 수 있습니다. **diffusion\_models** * [wan2.2\_s2v\_14B\_fp8\_scaled.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_s2v_14B_fp8_scaled.safetensors) * [wan2.2\_s2v\_14B\_bf16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_s2v_14B_bf16.safetensors) **audio\_encoders** * [wav2vec2\_large\_english\_fp16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/audio_encoders/wav2vec2_large_english_fp16.safetensors) **vae** * [wan\_2.1\_vae.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/vae/wan_2.1_vae.safetensors) **text\_encoders** * [umt5\_xxl\_fp8\_e4m3fn\_scaled.safetensors](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors) ``` ComfyUI/ ├───📂 models/ │ ├───📂 diffusion_models/ │ │ ├─── wan2.2_s2v_14B_fp8_scaled.safetensors │ │ └─── wan2.2_s2v_14B_bf16.safetensors │ ├───📂 text_encoders/ │ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors │ ├───📂 audio_encoders/ # 찾을 수 없는 경우 생성 │ │ └─── wav2vec2_large_english_fp16.safetensors │ └───📂 vae/ │ └── wan_2.1_vae.safetensors ``` ### 3. 워크플로우 지침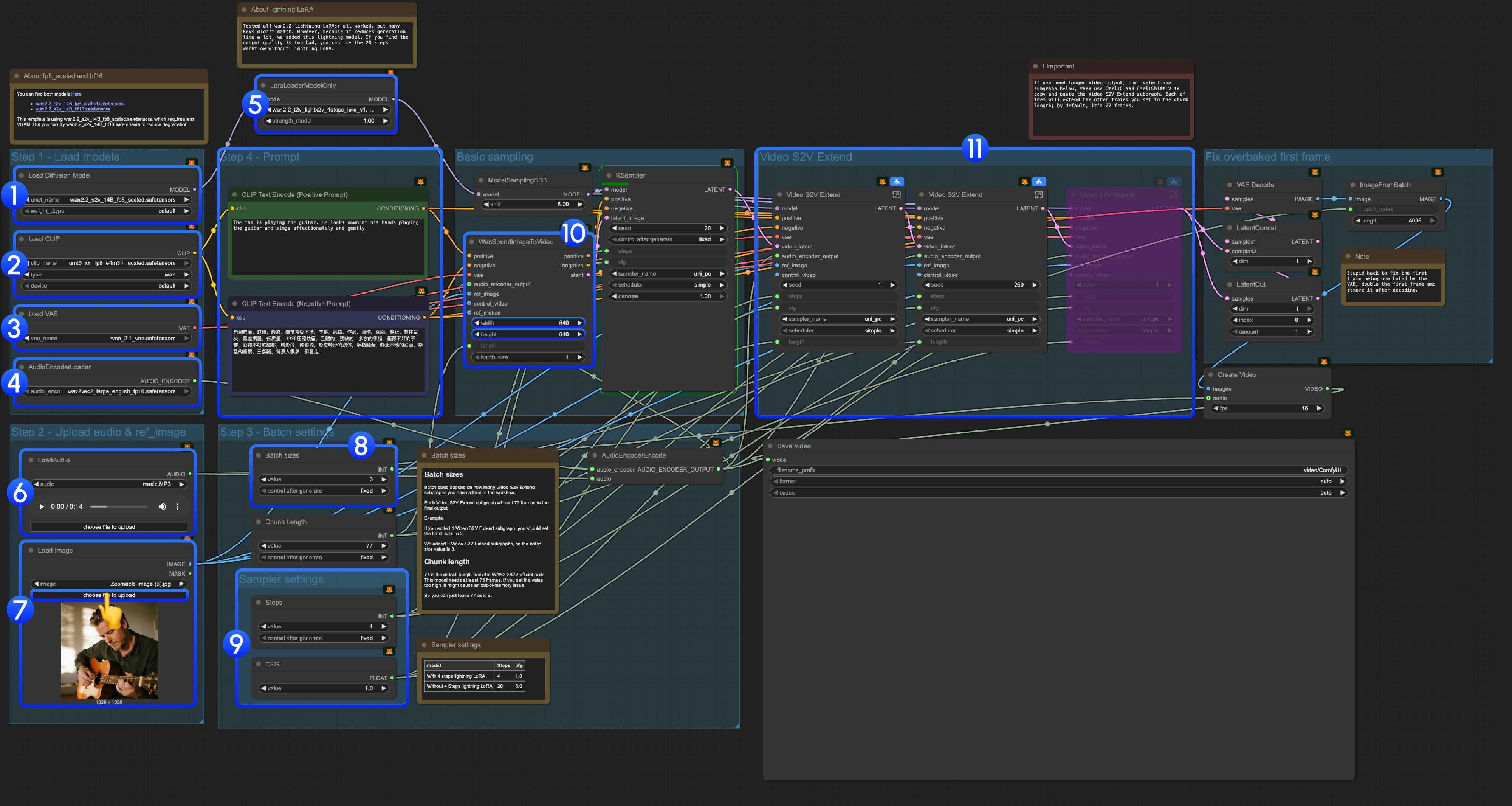 #### 3.1 Lightning LoRA 소개
#### 3.2 fp8\_scaled 및 bf16 모델 소개
두 모델 모두 [여기](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/diffusion_models)에서 확인하실 수 있습니다:
* [wan2.2\_s2v\_14B\_fp8\_scaled.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_s2v_14B_fp8_scaled.safetensors)
* [wan2.2\_s2v\_14B\_bf16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_s2v_14B_bf16.safetensors)
이 템플릿에서는 `wan2.2_s2v_14B_fp8_scaled.safetensors`를 사용하며, 이 모델은 더 적은 VRAM을 필요로 합니다. 하지만 품질 저하를 줄이기 위해 `wan2.2_s2v_14B_bf16.safetensors`를 시도해볼 수도 있습니다.
#### 3.3 단계별 작동 지침
**Step 1: 모델 로드**
1. **Diffusion 모델 로드**: `wan2.2_s2v_14B_fp8_scaled.safetensors` 또는 `wan2.2_s2v_14B_bf16.safetensors` 로드
* 제공된 워크플로우에서는 `wan2.2_s2v_14B_fp8_scaled.safetensors`를 사용하며, 이 모델은 더 적은 VRAM을 필요로 합니다.
* 하지만 품질 저하를 줄이기 위해 `wan2.2_s2v_14B_bf16.safetensors`를 시도해볼 수도 있습니다.
2. **CLIP 로드**: `umt5_xxl_fp8_e4m3fn_scaled.safetensors` 로드
3. **VAE 로드**: `wan_2.1_vae.safetensors` 로드
4. **AudioEncoderLoader**: `wav2vec2_large_english_fp16.safetensors` 로드
5. **LoraLoaderModelOnly**: `wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors` (Lightning LoRA) 로드
* 우리는 모든 wan2.2 lightning LoRA를 테스트했습니다. 이는 Wan2.2 S2V용으로 특별히 훈련된 LoRA가 아니므로 많은 핵심 값이 맞지 않지만, 생성 시간을 크게 줄여주기 때문에 추가했습니다. 앞으로 이 템플릿을 계속 최적화할 예정입니다.
* 이를 사용하면 상당한 동적 및 품질 손실이 발생합니다.
* 출력 품질이 너무 낮다고 느껴진다면 원래 20단계 워크플로우를 시도해볼 수 있습니다.
6. **LoadAudio**: 제공된 오디오 파일이나 직접 업로드한 오디오를 로드하세요.
7. **Load Image**: 참조 이미지를 업로드하세요.
8. **배치 크기**: 추가하는 Video S2V Extend 서브그래프 노드 수에 따라 설정하세요.
* 각 Video S2V Extend 서브그래프는 최종 출력에 77프레임을 추가합니다.
* 예를 들어: Video S2V Extend 서브그래프를 2개 추가했다면 배치 크기는 3이어야 하며, 이는 전체 샘플링 반복 횟수를 의미합니다.
* **Chunk Length**: 기본값인 77을 유지하세요.
9. **샘플러 설정**: Lightning LoRA 사용 여부에 따라 다른 설정을 선택하세요.
* 4단계 Lightning LoRA 사용 시: steps: 4, cfg: 1.0
* 4단계 Lightning LoRA 미사용 시: steps: 20, cfg: 6.0
10. **크기 설정**: 출력 비디오의 크기를 설정하세요.
11. **Video S2V Extend**: 비디오 확장 서브그래프 노드들입니다. 기본 프레임 수가 77이고, 이 모델은 16fps이므로 각 확장은 77 / 16 = 4.8125초의 비디오를 생성합니다.
* 비디오 확장 서브그래프 노드 수를 입력 오디오 길이와 맞추려면 계산이 필요합니다. 예를 들어: 입력 오디오가 14초라면 총 필요한 프레임 수는 14×16=224이며, 각 비디오 확장은 77프레임이므로 224/77 = 2.9, 즉 3개의 비디오 확장 서브그래프 노드가 필요합니다.
12. Ctrl-Enter를 누르거나 실행 버튼을 클릭하여 워크플로우를 실행하세요.
#### 3.1 Lightning LoRA 소개
#### 3.2 fp8\_scaled 및 bf16 모델 소개
두 모델 모두 [여기](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/diffusion_models)에서 확인하실 수 있습니다:
* [wan2.2\_s2v\_14B\_fp8\_scaled.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_s2v_14B_fp8_scaled.safetensors)
* [wan2.2\_s2v\_14B\_bf16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_s2v_14B_bf16.safetensors)
이 템플릿에서는 `wan2.2_s2v_14B_fp8_scaled.safetensors`를 사용하며, 이 모델은 더 적은 VRAM을 필요로 합니다. 하지만 품질 저하를 줄이기 위해 `wan2.2_s2v_14B_bf16.safetensors`를 시도해볼 수도 있습니다.
#### 3.3 단계별 작동 지침
**Step 1: 모델 로드**
1. **Diffusion 모델 로드**: `wan2.2_s2v_14B_fp8_scaled.safetensors` 또는 `wan2.2_s2v_14B_bf16.safetensors` 로드
* 제공된 워크플로우에서는 `wan2.2_s2v_14B_fp8_scaled.safetensors`를 사용하며, 이 모델은 더 적은 VRAM을 필요로 합니다.
* 하지만 품질 저하를 줄이기 위해 `wan2.2_s2v_14B_bf16.safetensors`를 시도해볼 수도 있습니다.
2. **CLIP 로드**: `umt5_xxl_fp8_e4m3fn_scaled.safetensors` 로드
3. **VAE 로드**: `wan_2.1_vae.safetensors` 로드
4. **AudioEncoderLoader**: `wav2vec2_large_english_fp16.safetensors` 로드
5. **LoraLoaderModelOnly**: `wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors` (Lightning LoRA) 로드
* 우리는 모든 wan2.2 lightning LoRA를 테스트했습니다. 이는 Wan2.2 S2V용으로 특별히 훈련된 LoRA가 아니므로 많은 핵심 값이 맞지 않지만, 생성 시간을 크게 줄여주기 때문에 추가했습니다. 앞으로 이 템플릿을 계속 최적화할 예정입니다.
* 이를 사용하면 상당한 동적 및 품질 손실이 발생합니다.
* 출력 품질이 너무 낮다고 느껴진다면 원래 20단계 워크플로우를 시도해볼 수 있습니다.
6. **LoadAudio**: 제공된 오디오 파일이나 직접 업로드한 오디오를 로드하세요.
7. **Load Image**: 참조 이미지를 업로드하세요.
8. **배치 크기**: 추가하는 Video S2V Extend 서브그래프 노드 수에 따라 설정하세요.
* 각 Video S2V Extend 서브그래프는 최종 출력에 77프레임을 추가합니다.
* 예를 들어: Video S2V Extend 서브그래프를 2개 추가했다면 배치 크기는 3이어야 하며, 이는 전체 샘플링 반복 횟수를 의미합니다.
* **Chunk Length**: 기본값인 77을 유지하세요.
9. **샘플러 설정**: Lightning LoRA 사용 여부에 따라 다른 설정을 선택하세요.
* 4단계 Lightning LoRA 사용 시: steps: 4, cfg: 1.0
* 4단계 Lightning LoRA 미사용 시: steps: 20, cfg: 6.0
10. **크기 설정**: 출력 비디오의 크기를 설정하세요.
11. **Video S2V Extend**: 비디오 확장 서브그래프 노드들입니다. 기본 프레임 수가 77이고, 이 모델은 16fps이므로 각 확장은 77 / 16 = 4.8125초의 비디오를 생성합니다.
* 비디오 확장 서브그래프 노드 수를 입력 오디오 길이와 맞추려면 계산이 필요합니다. 예를 들어: 입력 오디오가 14초라면 총 필요한 프레임 수는 14×16=224이며, 각 비디오 확장은 77프레임이므로 224/77 = 2.9, 즉 3개의 비디오 확장 서브그래프 노드가 필요합니다.
12. Ctrl-Enter를 누르거나 실행 버튼을 클릭하여 워크플로우를 실행하세요.