> ## Documentation Index
> Fetch the complete documentation index at: https://docs.comfy.org/llms.txt
> Use this file to discover all available pages before exploring further.
# ComfyUI Wan2.1 Video 示例
> 本文介绍了如何在 ComfyUI 中完成 Wan2.1 Video 视频首尾帧视频生成示例
Wan2.1 Video 系列为阿里巴巴于 2025年2月开源的视频生成模型,其开源协议为 [Apache 2.0](https://github.com/Wan-Video/Wan2.1?tab=Apache-2.0-1-ov-file),提供 14B(140亿参数)和 1.3B(13亿参数)两个版本,覆盖文生视频(T2V)、图生视频(I2V)等多项任务。
该模型不仅在性能上超越现有开源模型,更重要的是其轻量级版本仅需 8GB 显存即可运行,大大降低了使用门槛。
* [Wan2.1 代码仓库](https://github.com/Wan-Video/Wan2.1)
* [Wan2.1 相关模型仓库](https://huggingface.co/Wan-AI)
## Wan2.1 ComfyUI 原生(native)工作流示例
请确保你的 ComfyUI 已经更新。
* [ComfyUI 下载](https://www.comfy.org/download)
* [ComfyUI 更新教程](/zh/installation/update_comfyui)
本指南里的工作流可以在 ComfyUI 的[工作流模板](/zh/interface/features/template)中找到。如果找不到,可能是 ComfyUI 没有更新。
如果加载工作流时有节点缺失,可能原因有:
1. 你用的不是最新开发版(nightly)。
2. 你用的是稳定版或桌面版(没有包含最新的更新)。
3. 启动时有些节点导入失败。
* 桌面版是基于 ComfyUI 稳定版本构建的,它会在有新的桌面稳定版本发布时自动更新。
* [Cloud](https://cloud.comfy.org) 会在 ComfyUI 稳定版本发布后更新,我们会同步更新 Cloud。
所以,如果你发现本教程中有任何核心节点缺失,那是因为对应的节点支持还在开发中没有发布正式的稳定版,请等待下一个稳定版本发布。
## 模型安装
本篇指南涉及的所有模型你都可以在[这里](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files)找到, 下面是本篇示例中将会使用到的共用的模型,你可以提前进行下载:
从**Text encoders** 选择一个版本进行下载,
* [umt5\_xxl\_fp16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/text_encoders/umt5_xxl_fp16.safetensors?download=true)
* [umt5\_xxl\_fp8\_e4m3fn\_scaled.safetensors](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors?download=true)
**VAE**
* [wan\_2.1\_vae.safetensors](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/vae/wan_2.1_vae.safetensors?download=true)
**CLIP Vision**
* [clip\_vision\_h.safetensors](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/clip_vision/clip_vision_h.safetensors?download=true)
文件保存位置
```
ComfyUI/
├── models/
│ ├── diffusion_models/
│ ├── ... # 我们在对应的工作流中进行补充说明
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └── vae/
│ │ └── wan_2.1_vae.safetensors
│ └── clip_vision/
│ └── clip_vision_h.safetensors
```
对于 diffusion 模型,我们在本篇示例中将使用 fp16 精度的模型,因为我们发现相对于 bf16 的版本 fp16 版本的效果更好,如果你需要其它精度的版本,请访问[这里](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/diffusion_models)进行下载
## Wan2.1 文生视频工作流
在开始工作流前请下载 [wan2.1\_t2v\_1.3B\_fp16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/diffusion_models/wan2.1_t2v_1.3B_fp16.safetensors?download=true),并保存到 `ComfyUI/models/diffusion_models/` 目录下。
> 如果你需要其它的 t2v 精度版本,请访问[这里](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/diffusion_models)进行下载
### 1. 工作流文件下载
下载下面的文件,并拖入 ComfyUI 以加载对应的工作流

### 2. 按流程完成工作流运行
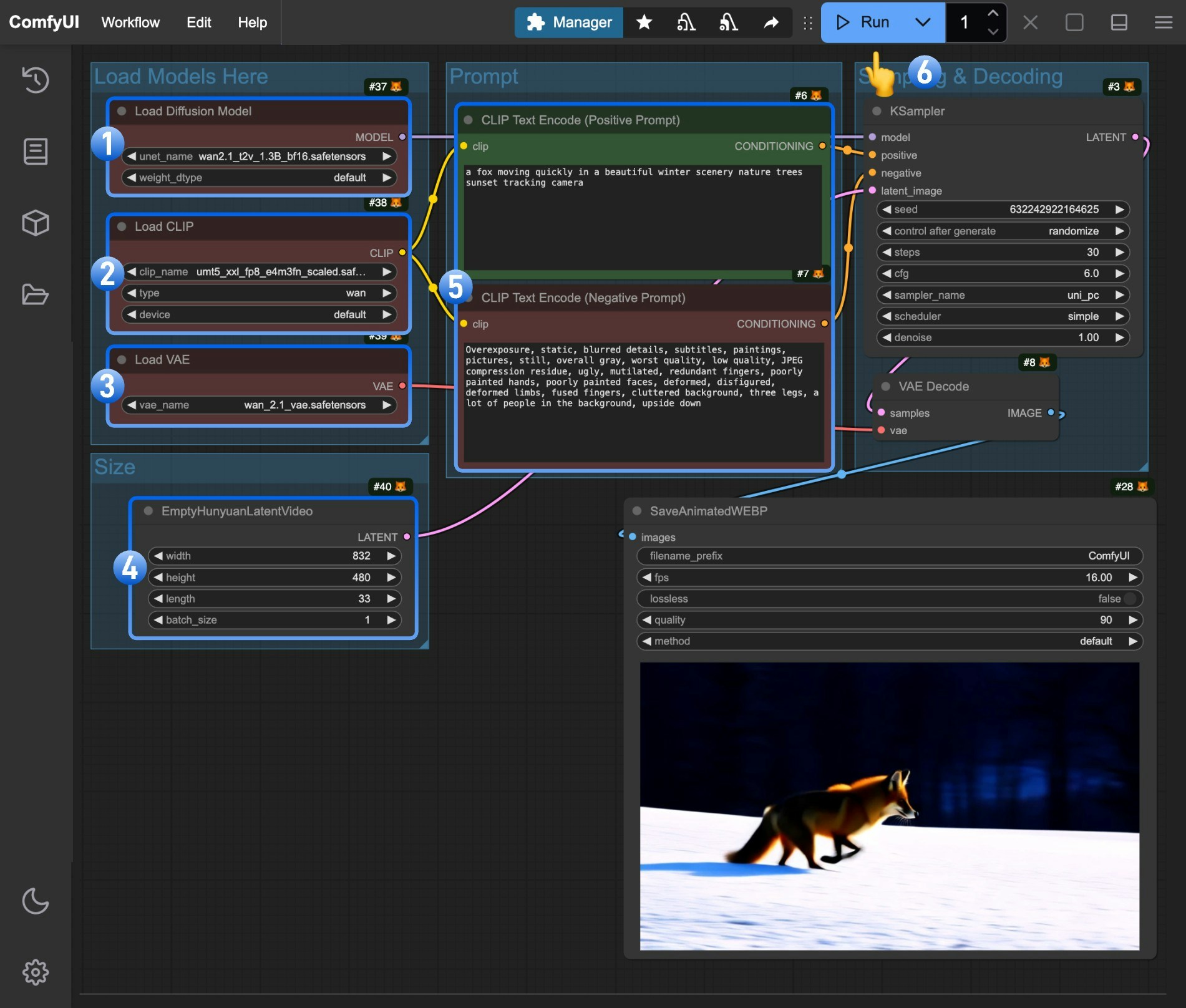 1. 确保`Load Diffusion Model`节点加载了 `wan2.1_t2v_1.3B_fp16.safetensors` 模型
2. 确保`Load CLIP`节点加载了 `umt5_xxl_fp8_e4m3fn_scaled.safetensors` 模型
3. 确保`Load VAE`节点加载了 `wan_2.1_vae.safetensors` 模型
4. (可选)可以在`EmptyHunyuanLatentVideo` 节点设置了视频的尺寸,如果有需要你可以修改
5. (可选)如果你需要修改提示词(正向及负向)请在序号`5` 的 `CLIP Text Encoder` 节点中进行修改
6. 点击 `Run` 按钮,或者使用快捷键 `Ctrl(cmd) + Enter(回车)` 来执行视频生成
## Wan2.1 图生视频工作流
**由于 Wan Video 将 480P 和 720P 的模型分开** ,所以在本篇中我们将需要分别对两中清晰度的视频做出示例,除了对应模型不同之外,他们还有些许的参数差异
### 480P 版本
#### 1. 工作流及输入图片
下载下面的图片,并拖入 ComfyUI 中来加载对应的工作流

我们将使用下面的图片作为输入:

#### 2. 模型下载
请下载[wan2.1\_i2v\_480p\_14B\_fp16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/diffusion_models/wan2.1_i2v_480p_14B_fp16.safetensors?download=true),并保存到 `ComfyUI/models/diffusion_models/` 目录下
#### 3. 按步骤完成工作流的运行
1. 确保`Load Diffusion Model`节点加载了 `wan2.1_t2v_1.3B_fp16.safetensors` 模型
2. 确保`Load CLIP`节点加载了 `umt5_xxl_fp8_e4m3fn_scaled.safetensors` 模型
3. 确保`Load VAE`节点加载了 `wan_2.1_vae.safetensors` 模型
4. (可选)可以在`EmptyHunyuanLatentVideo` 节点设置了视频的尺寸,如果有需要你可以修改
5. (可选)如果你需要修改提示词(正向及负向)请在序号`5` 的 `CLIP Text Encoder` 节点中进行修改
6. 点击 `Run` 按钮,或者使用快捷键 `Ctrl(cmd) + Enter(回车)` 来执行视频生成
## Wan2.1 图生视频工作流
**由于 Wan Video 将 480P 和 720P 的模型分开** ,所以在本篇中我们将需要分别对两中清晰度的视频做出示例,除了对应模型不同之外,他们还有些许的参数差异
### 480P 版本
#### 1. 工作流及输入图片
下载下面的图片,并拖入 ComfyUI 中来加载对应的工作流

我们将使用下面的图片作为输入:

#### 2. 模型下载
请下载[wan2.1\_i2v\_480p\_14B\_fp16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/diffusion_models/wan2.1_i2v_480p_14B_fp16.safetensors?download=true),并保存到 `ComfyUI/models/diffusion_models/` 目录下
#### 3. 按步骤完成工作流的运行
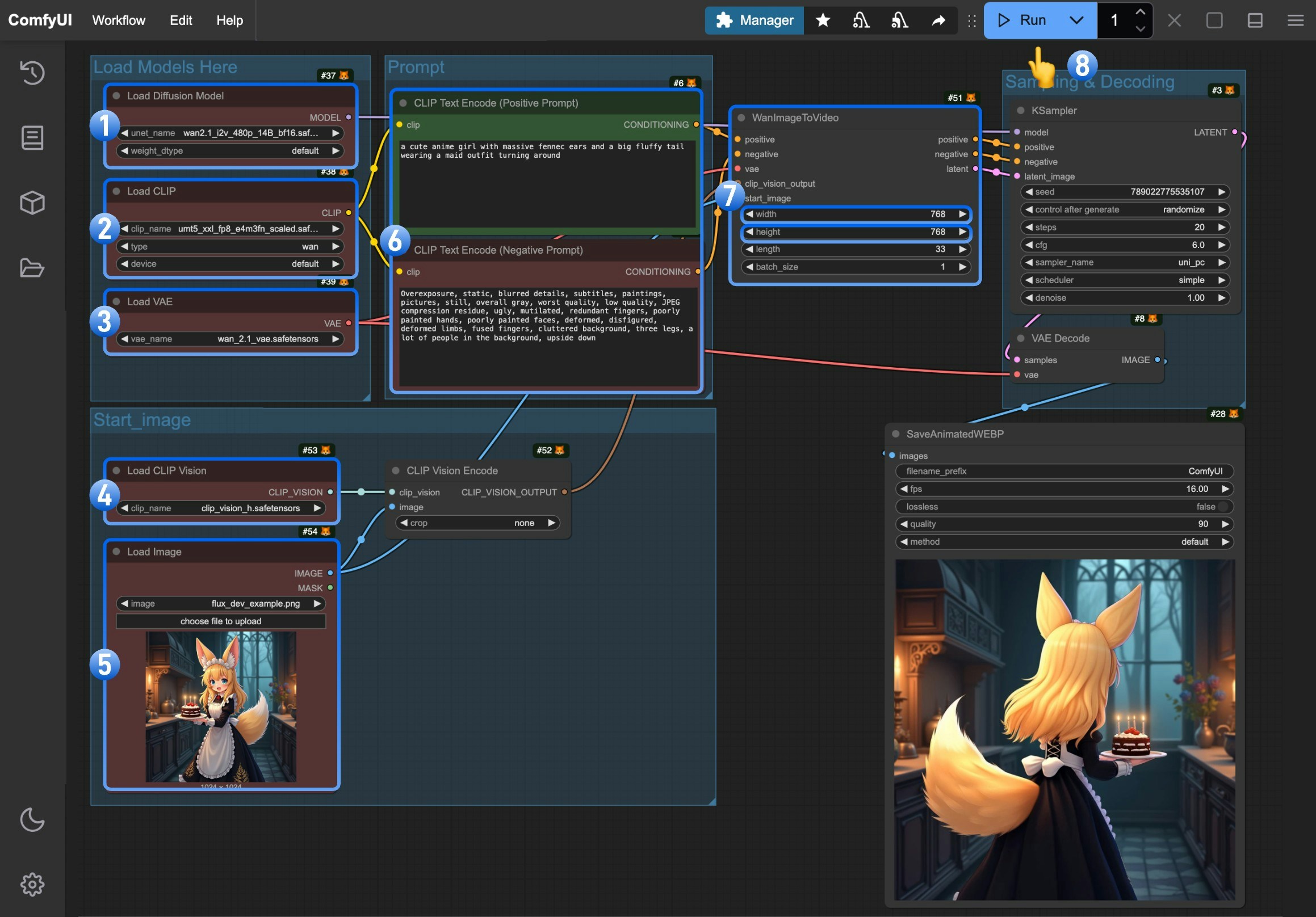 1. 确保`Load Diffusion Model`节点加载了 `wan2.1_i2v_480p_14B_fp16.safetensors` 模型
2. 确保`Load CLIP`节点加载了 `umt5_xxl_fp8_e4m3fn_scaled.safetensors` 模型
3. 确保`Load VAE`节点加载了 `wan_2.1_vae.safetensors` 模型
4. 确保`Load CLIP Vision`节点加载了 `clip_vision_h.safetensors` 模型
5. 在`Load Image`节点中上传我们提供的输入图片
6. (可选)在`CLIP Text Encoder`节点中输入你想要生成的视频描述内容,
7. (可选)在`WanImageToVideo` 节点中设置了视频的尺寸,如果有需要你可以修改
8. 点击 `Run` 按钮,或者使用快捷键 `Ctrl(cmd) + Enter(回车)` 来执行视频生成
### 720P 版本
#### 1. 工作流及输入图片
下载下面的图片,并拖入 ComfyUI 中来加载对应的工作流

我们将使用下面的图片作为输入:

#### 2. 模型下载
请下载[wan2.1\_i2v\_720p\_14B\_fp16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/diffusion_models/wan2.1_i2v_720p_14B_fp16.safetensors?download=true),并保存到 `ComfyUI/models/diffusion_models/` 目录下
#### 3. 按步骤完成工作流的运行
1. 确保`Load Diffusion Model`节点加载了 `wan2.1_i2v_480p_14B_fp16.safetensors` 模型
2. 确保`Load CLIP`节点加载了 `umt5_xxl_fp8_e4m3fn_scaled.safetensors` 模型
3. 确保`Load VAE`节点加载了 `wan_2.1_vae.safetensors` 模型
4. 确保`Load CLIP Vision`节点加载了 `clip_vision_h.safetensors` 模型
5. 在`Load Image`节点中上传我们提供的输入图片
6. (可选)在`CLIP Text Encoder`节点中输入你想要生成的视频描述内容,
7. (可选)在`WanImageToVideo` 节点中设置了视频的尺寸,如果有需要你可以修改
8. 点击 `Run` 按钮,或者使用快捷键 `Ctrl(cmd) + Enter(回车)` 来执行视频生成
### 720P 版本
#### 1. 工作流及输入图片
下载下面的图片,并拖入 ComfyUI 中来加载对应的工作流

我们将使用下面的图片作为输入:

#### 2. 模型下载
请下载[wan2.1\_i2v\_720p\_14B\_fp16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/diffusion_models/wan2.1_i2v_720p_14B_fp16.safetensors?download=true),并保存到 `ComfyUI/models/diffusion_models/` 目录下
#### 3. 按步骤完成工作流的运行
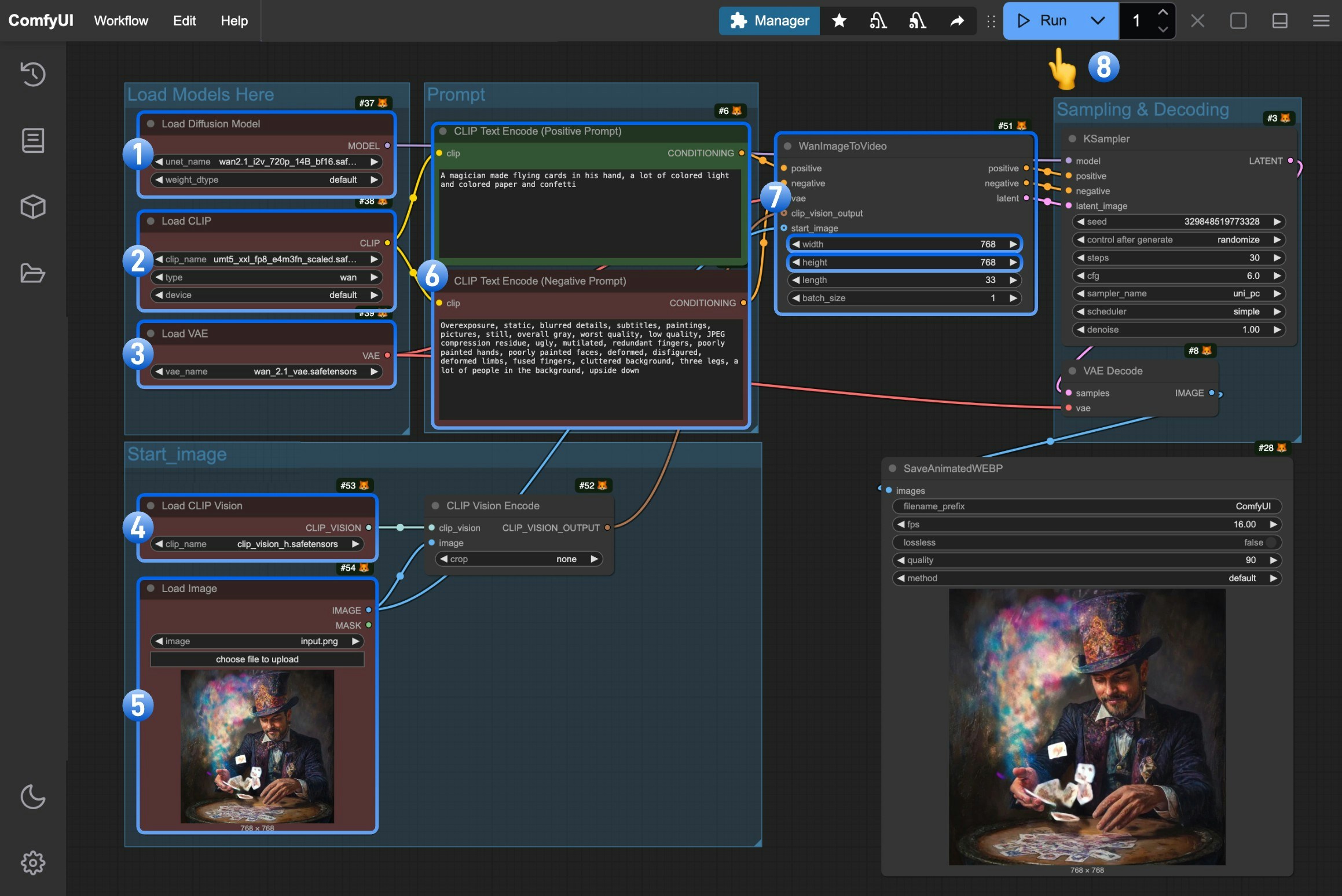 1. 确保`Load Diffusion Model`节点加载了 `wan2.1_i2v_720p_14B_fp16.safetensors` 模型
2. 确保`Load CLIP`节点加载了 `umt5_xxl_fp8_e4m3fn_scaled.safetensors` 模型
3. 确保`Load VAE`节点加载了 `wan_2.1_vae.safetensors` 模型
4. 确保`Load CLIP Vision`节点加载了 `clip_vision_h.safetensors` 模型
5. 在`Load Image`节点中上传我们提供的输入图片
6. (可选)在`CLIP Text Encoder`节点中输入你想要生成的视频描述内容,
7. (可选)在`WanImageToVideo` 节点中设置了视频的尺寸,如果有需要你可以修改
8. 点击 `Run` 按钮,或者使用快捷键 `Ctrl(cmd) + Enter(回车)` 来执行视频生成
1. 确保`Load Diffusion Model`节点加载了 `wan2.1_i2v_720p_14B_fp16.safetensors` 模型
2. 确保`Load CLIP`节点加载了 `umt5_xxl_fp8_e4m3fn_scaled.safetensors` 模型
3. 确保`Load VAE`节点加载了 `wan_2.1_vae.safetensors` 模型
4. 确保`Load CLIP Vision`节点加载了 `clip_vision_h.safetensors` 模型
5. 在`Load Image`节点中上传我们提供的输入图片
6. (可选)在`CLIP Text Encoder`节点中输入你想要生成的视频描述内容,
7. (可选)在`WanImageToVideo` 节点中设置了视频的尺寸,如果有需要你可以修改
8. 点击 `Run` 按钮,或者使用快捷键 `Ctrl(cmd) + Enter(回车)` 来执行视频生成