关于 OmniGen2
OmniGen2 是一个强大且高效的统一多模态生成模型,总参数量约 7B(3B 文本模型 + 4B 图像生成模型)。与 OmniGen v1 不同,OmniGen2 采用创新的双路径 Transformer 架构,具有完全独立的文本自回归模型和图像扩散模型,实现参数解耦和专门优化。模型亮点
- 视觉理解:继承了 Qwen-VL-2.5 基础模型强大的图像内容解释和分析能力
- 文生图生成:从文本提示创建高保真度和美观的图像
- 指令引导的图像编辑:执行复杂的、基于指令的图像修改,在开源模型中达到最先进的性能
- 上下文生成:多功能的能力,可以处理和灵活结合多样化的输入(包括人物、参考对象和场景),产生新颖且连贯的视觉输出
技术特性
- 双路径架构:基于 Qwen 2.5 VL(3B)文本编码器 + 独立扩散 Transformer(4B)
- Omni-RoPE 位置编码:支持多图像空间定位和身份区分
- 参数解耦设计:避免文本生成对图像质量的负面影响
- 支持复杂的文本理解和图像理解
- 可控的图像生成和编辑
- 优秀的细节保持能力
- 统一架构支持多种图像生成任务
- 文字生成能力:可以在图像中生成清晰的文字内容
OmniGen2 模型下载
由于本文涉及不同工作流,对应的模型文件及安装位置如下,对应工作流中也已包含了模型文件下载信息: Diffusion Models) VAE Text Encoders) 文件保存位置:ComfyUI OmniGen2 文生图工作流
1. 工作流文件下载
在 Comfy Cloud 上运行

2. 按步骤完成工作流运行
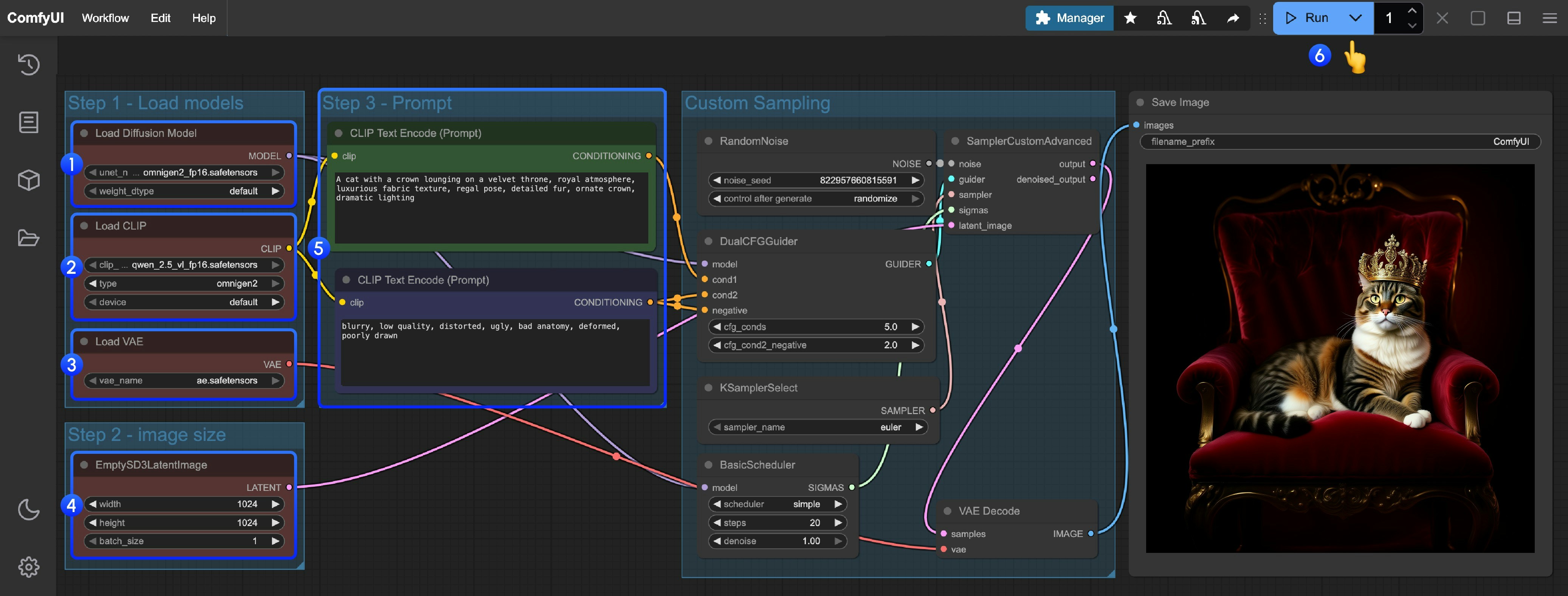
- 加载主模型:确保
Load Diffusion Model节点加载了omnigen2_fp16.safetensors - 加载文本编码器:确保
Load CLIP节点加载了qwen_2.5_vl_fp16.safetensors - 加载 VAE:确保
Load VAE节点加载了ae.safetensors - 设置图像尺寸:在
EmptySD3LatentImage节点设置生成图片的尺寸(推荐 1024x1024) - 输入提示词:
- 在第一个
CLipTextEncode节点中输入正向提示词(想要出现在图像中的内容) - 在第二个
CLipTextEncode节点中输入负向提示词(不想要出现在图像中的内容)
- 在第一个
- 开始生成:点击
Queue Prompt按钮,或使用快捷键Ctrl(cmd) + Enter(回车)来执行文生图 - 查看结果:生成完成后对应的图片会自动保存到
ComfyUI/output/目录下,你也可以在SaveImage节点中预览
ComfyUI OmniGen2 图片编辑工作流
OmniGen2 有丰富的图像编辑能力,并且支持为图像添加文本1. 工作流文件下载
在 Comfy Cloud 上运行
 下载下面的图片,我们将使用它作为输入图片。
下载下面的图片,我们将使用它作为输入图片。

2. 按步骤完成工作流运行
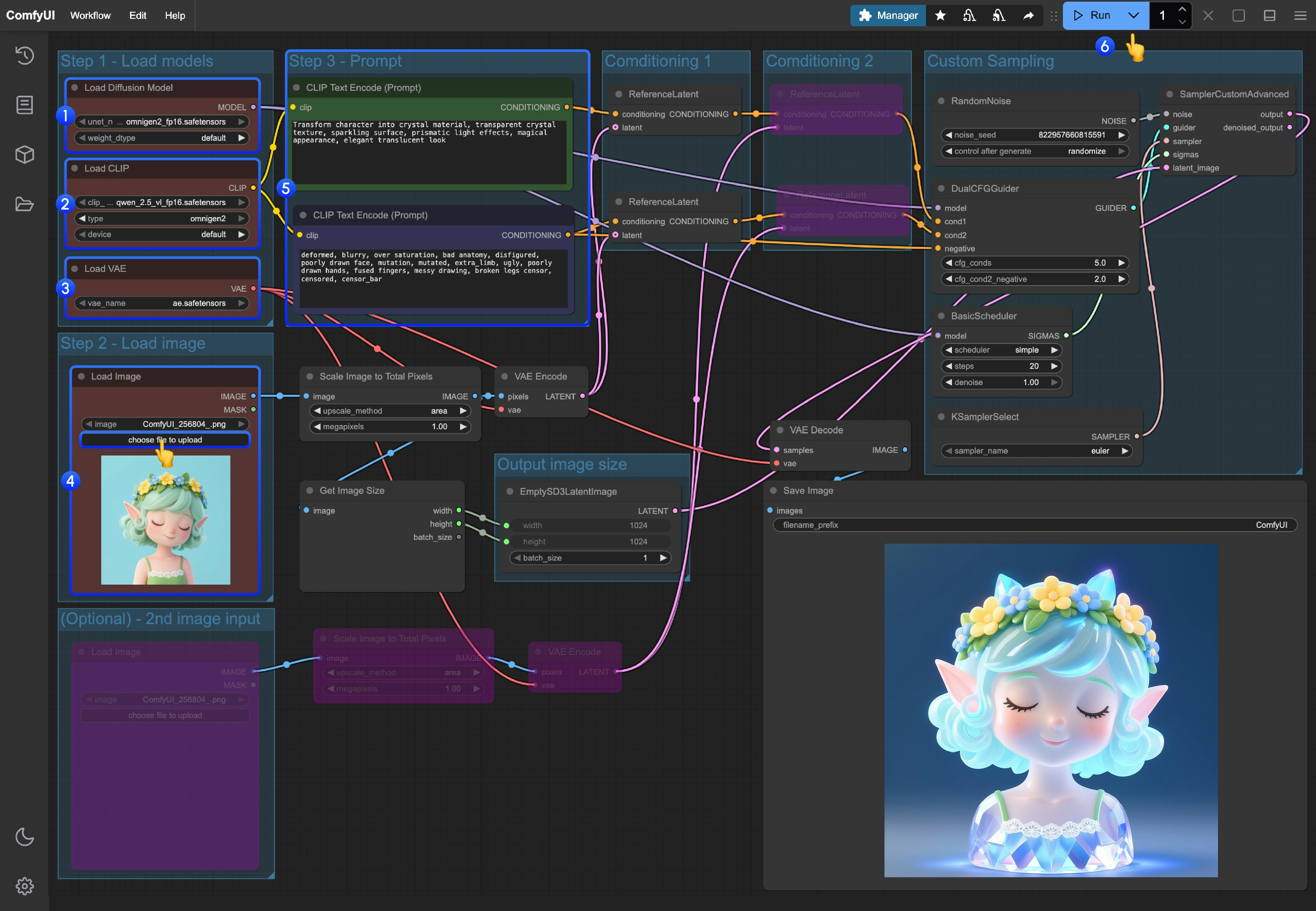
- 加载主模型:确保
Load Diffusion Model节点加载了omnigen2_fp16.safetensors - 加载文本编码器:确保
Load CLIP节点加载了qwen_2.5_vl_fp16.safetensors - 加载 VAE:确保
Load VAE节点加载了ae.safetensors - 上传图像:在
Load Image节点中上传提供的图片 - 输入提示词:
- 在第一个
CLipTextEncode节点中输入正向提示词(想要出现在图像中的内容) - 在第二个
CLipTextEncode节点中输入负向提示词(不想要出现在图像中的内容)
- 在第一个
- 开始生成:点击
Queue Prompt按钮,或使用快捷键Ctrl(cmd) + Enter(回车)来执行文生图 - 查看结果:生成完成后对应的图片会自动保存到
ComfyUI/output/目录下,你也可以在SaveImage节点中预览
3. 工作流补充说明
- 如果你想要启用第二张图像输入 ,你可以将工作流中状态为粉紫色的节点使用快捷键 Ctrl + B 来启用对应的节点输入
- 如果你想要自定义尺寸 ,可以删除链接
EmptySD3LatentImage节点的Get image size节点,并输入自定义尺寸