- Complete a text-to-image workflow
- Gain a basic understanding of diffusion model principles
- Learn about the functions and roles of workflow nodes
- Get an initial understanding of the SD1.5 model
About Text to Image
Text to Image is a fundamental process in AI art generation that creates images from text descriptions, with diffusion models at its core. The text-to-image process requires the following elements:- Artist: The image generation model
- Canvas: The latent space
- Image Requirements (Prompts): Including positive prompts (elements you want in the image) and negative prompts (elements you don’t want)
ComfyUI Text to Image Workflow Example Guide
1. Preparation
Ensure you have at least one SD1.5 model file in yourComfyUI/models/checkpoints folder, such as v1-5-pruned-emaonly-fp16.safetensors
If you haven’t installed it yet, please refer to the model installation section in Getting Started with ComfyUI AI Art Generation.
2. Loading the Text to Image Workflow
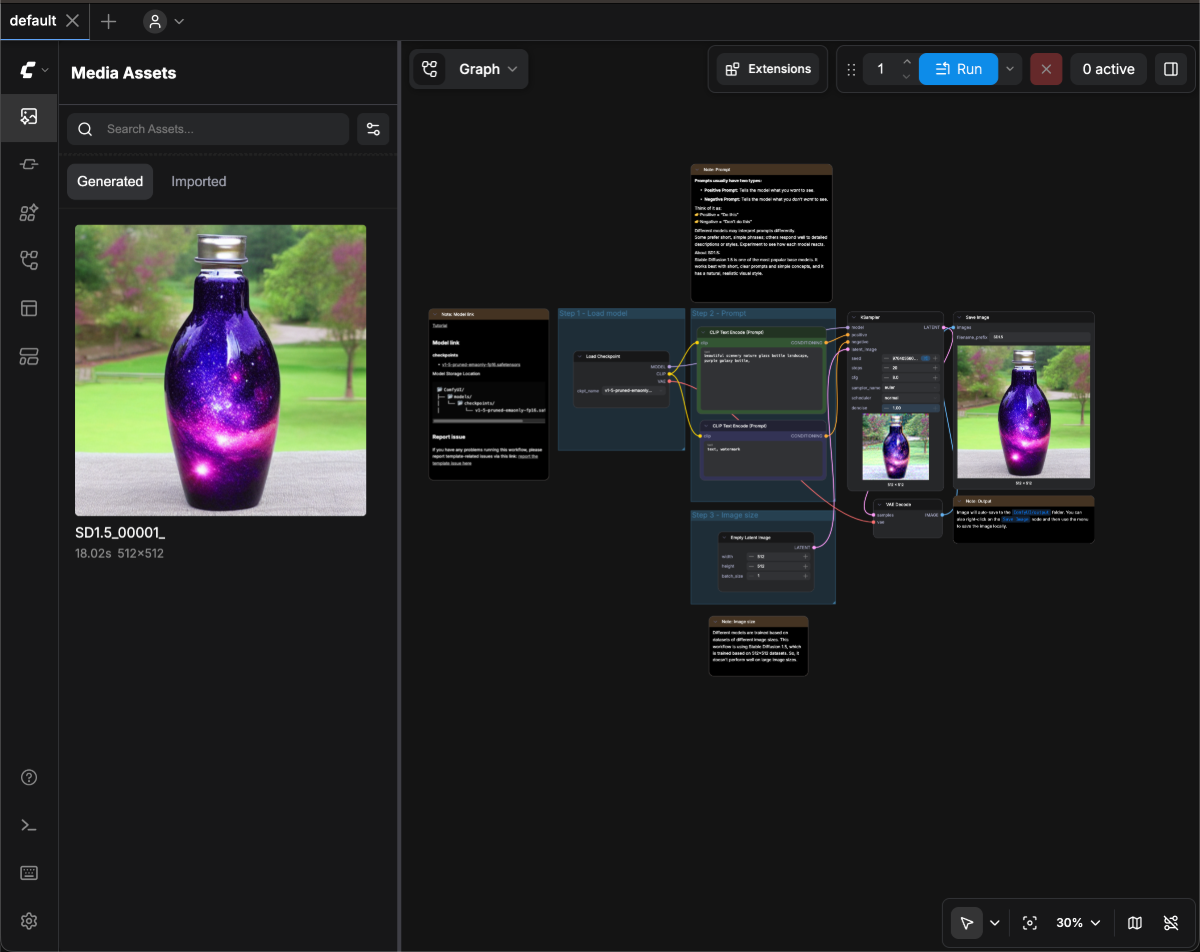
Download the image below and drag it into ComfyUI to load the workflow:
3. Loading the Model and Generating Your First Image
After installing the image model, follow the steps in the image below to load the model and generate your first image Follow these steps according to the image numbers:
Follow these steps according to the image numbers:
- In the Load Checkpoint node, use the arrows or click the text area to ensure v1-5-pruned-emaonly-fp16.safetensors is selected, and the left/right arrows don’t show null text
- Click the
Queuebutton or use the shortcutCtrl + Enterto execute image generation
4. Start Experimenting
Try modifying the text in the CLIP Text Encoder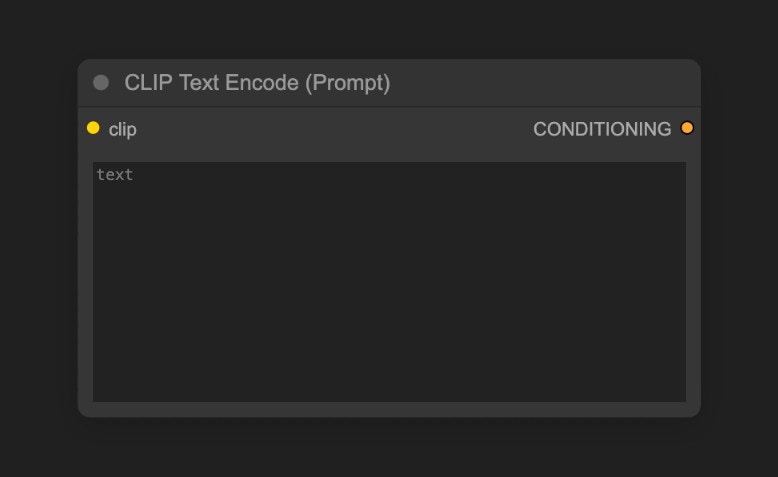
Positive connection to the KSampler node represents positive prompts, while the Negative connection represents negative prompts
Here are some basic prompting principles for the SD1.5 model:
- Use English whenever possible
- Separate prompts with English commas
, - Use phrases rather than long sentences
- Use specific descriptions
- Use expressions like
(golden hour:1.2)to increase the weight of specific keywords, making them more likely to appear in the image.1.2is the weight,golden houris the keyword - Use keywords like
masterpiece, best quality, 4kto improve generation quality
Text to Image Working Principles
The entire text-to-image process can be understood as a reverse diffusion process. The v1-5-pruned-emaonly-fp16.safetensors we downloaded is a pre-trained model that can generate target images from pure Gaussian noise. We only need to input our prompts, and it can generate target images through denoising random noise. We need to understand two concepts:- Latent Space: Latent Space is an abstract data representation method in diffusion models. Converting images from pixel space to latent space reduces storage space and makes it easier to train diffusion models and reduce denoising complexity. It’s like architects using blueprints (latent space) for design rather than designing directly on the building (pixel space), maintaining structural features while significantly reducing modification costs
- Pixel Space: Pixel Space is the storage space for images, which is the final image we see, used to store pixel values.
- Denoising Diffusion Probabilistic Models (DDPM)
- Denoising Diffusion Implicit Models (DDIM)
- High-Resolution Image Synthesis with Latent Diffusion Models
ComfyUI Text to Image Workflow Node Explanation
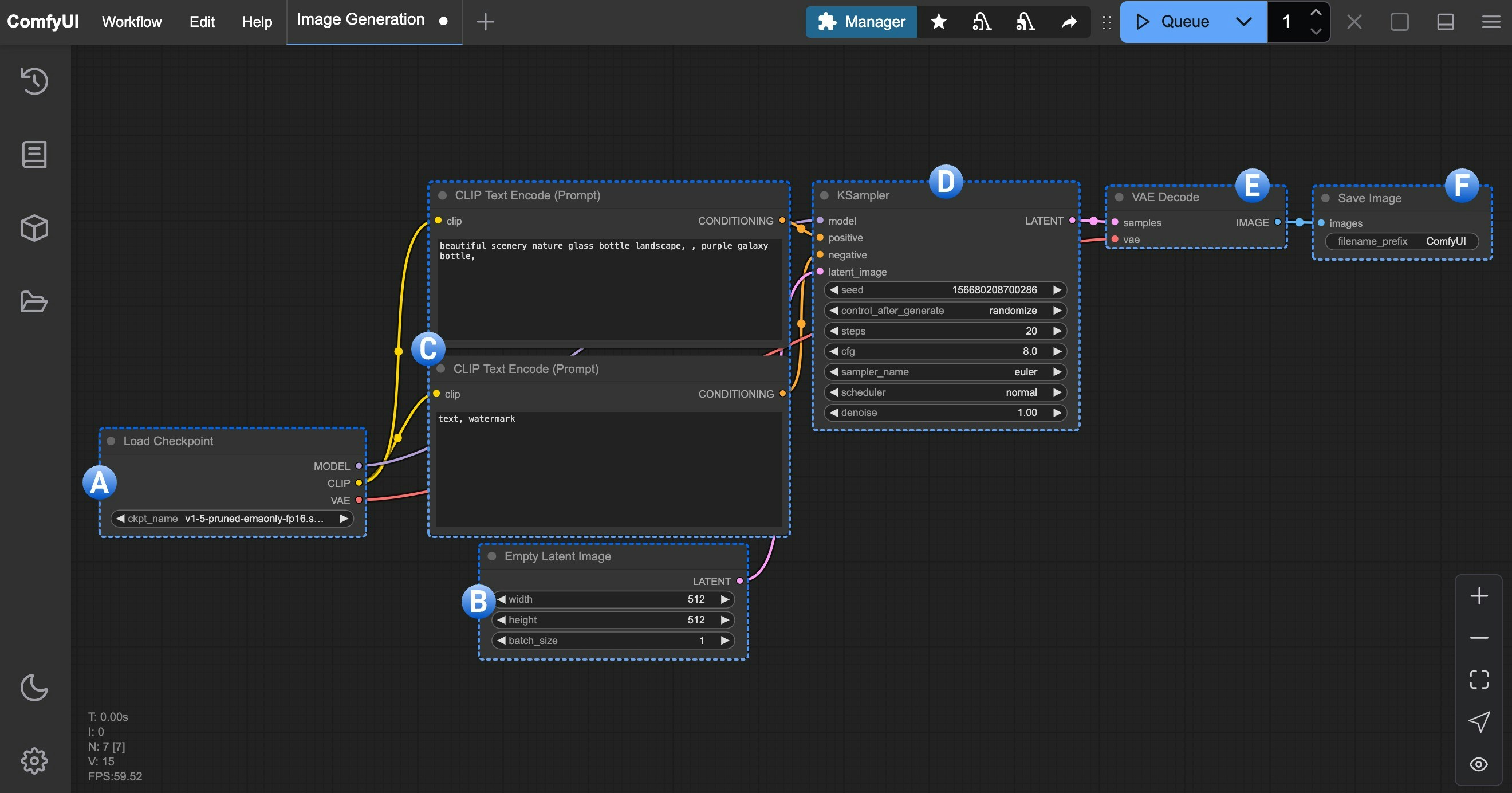
A. Load Checkpoint Node
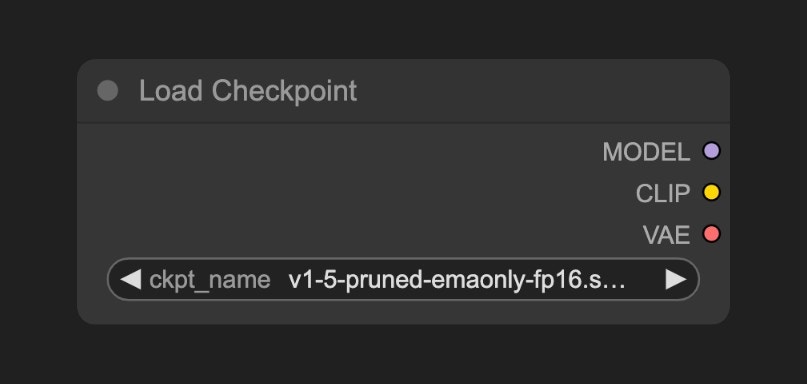
checkpoint usually contains three components: MODEL (UNet), CLIP, and VAE
MODEL (UNet): The UNet model responsible for noise prediction and image generation during the diffusion processCLIP: The text encoder that converts our text prompts into vectors that the model can understand, as the model cannot directly understand text promptsVAE: The Variational AutoEncoder that converts images between pixel space and latent space, as diffusion models work in latent space while our images are in pixel space
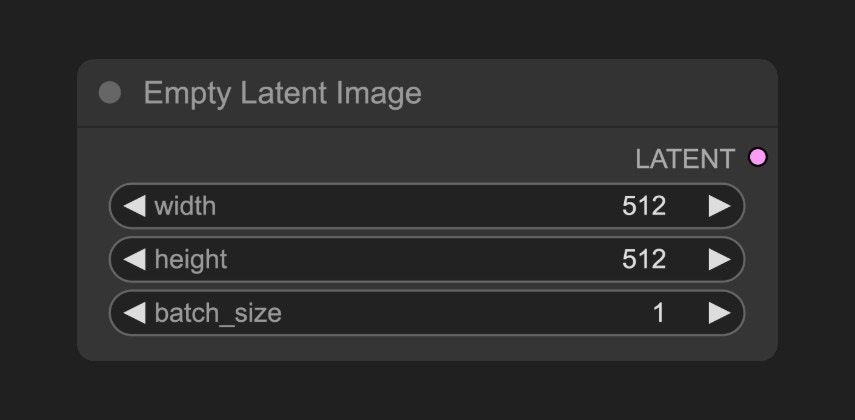
B. Empty Latent Image Node
C. CLIP Text Encoder Node
- The
Positivecondition input connected to the KSampler node represents positive prompts (elements you want in the image) - The
Negativecondition input connected to the KSampler node represents negative prompts (elements you don’t want in the image)
CLIP component from the Load Checkpoint node and output as conditions to the KSampler node
D. KSampler Node
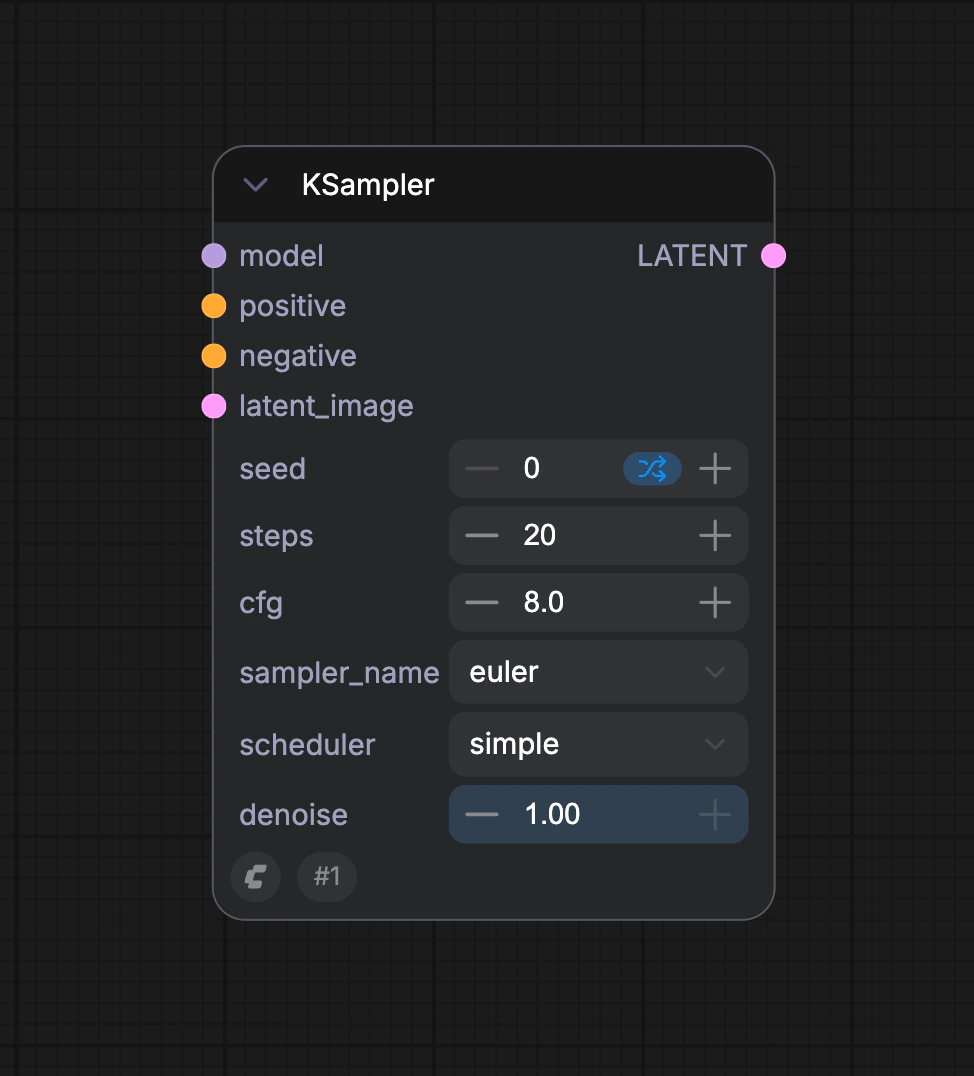
In the KSampler node, the latent space uses
seed as an initialization parameter to construct random noise, and semantic vectors Positive and Negative are input as conditions to the diffusion model
Then, based on the number of denoising steps specified by the steps parameter, denoising is performed. Each denoising step uses the denoising strength coefficient specified by the denoise parameter to denoise the latent space and generate a new latent space image
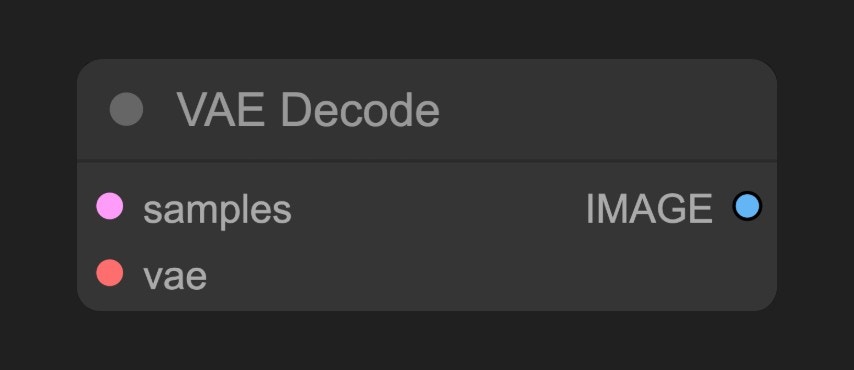
E. VAE Decode Node
F. Save Image Node
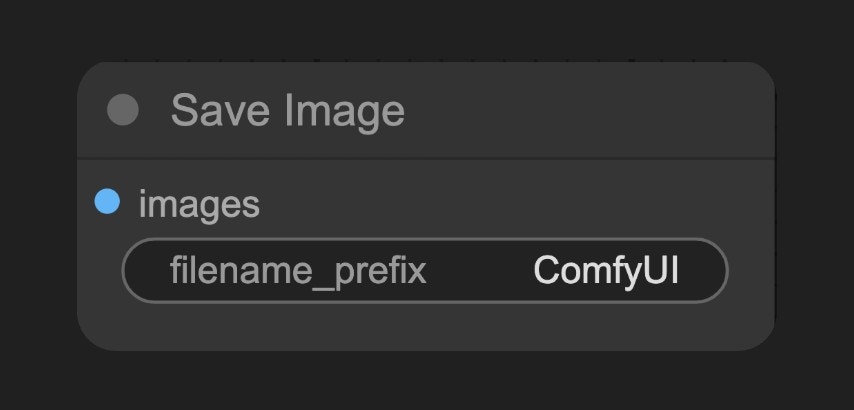
ComfyUI/output folder
Introduction to SD1.5 Model
SD1.5 (Stable Diffusion 1.5) is an AI image generation model developed by Stability AI. It’s the foundational version of the Stable Diffusion series, trained on 512×512 resolution images, making it particularly good at generating images at this resolution. With a size of about 4GB, it runs smoothly on consumer-grade GPUs (e.g., 6GB VRAM). Currently, SD1.5 has a rich ecosystem, supporting various plugins (like ControlNet, LoRA) and optimization tools. As a milestone model in AI art generation, SD1.5 remains the best entry-level choice thanks to its open-source nature, lightweight architecture, and rich ecosystem. Although newer versions like SDXL/SD3 have been released, its value for consumer-grade hardware remains unmatched.Basic Information
- Release Date: October 2022
- Core Architecture: Based on Latent Diffusion Model (LDM)
- Training Data: LAION-Aesthetics v2.5 dataset (approximately 590M training steps)
- Open Source Features: Fully open-source model/code/training data
Advantages and Limitations
Model Advantages:- Lightweight: Small size, only about 4GB, runs smoothly on consumer GPUs
- Low Entry Barrier: Supports a wide range of plugins and optimization tools
- Mature Ecosystem: Extensive plugin and tool support
- Fast Generation: Smooth operation on consumer GPUs
- Detail Handling: Hands/complex lighting prone to distortion
- Resolution Limits: Quality degrades for direct 1024x1024 generation
- Prompt Dependency: Requires precise English descriptions for control