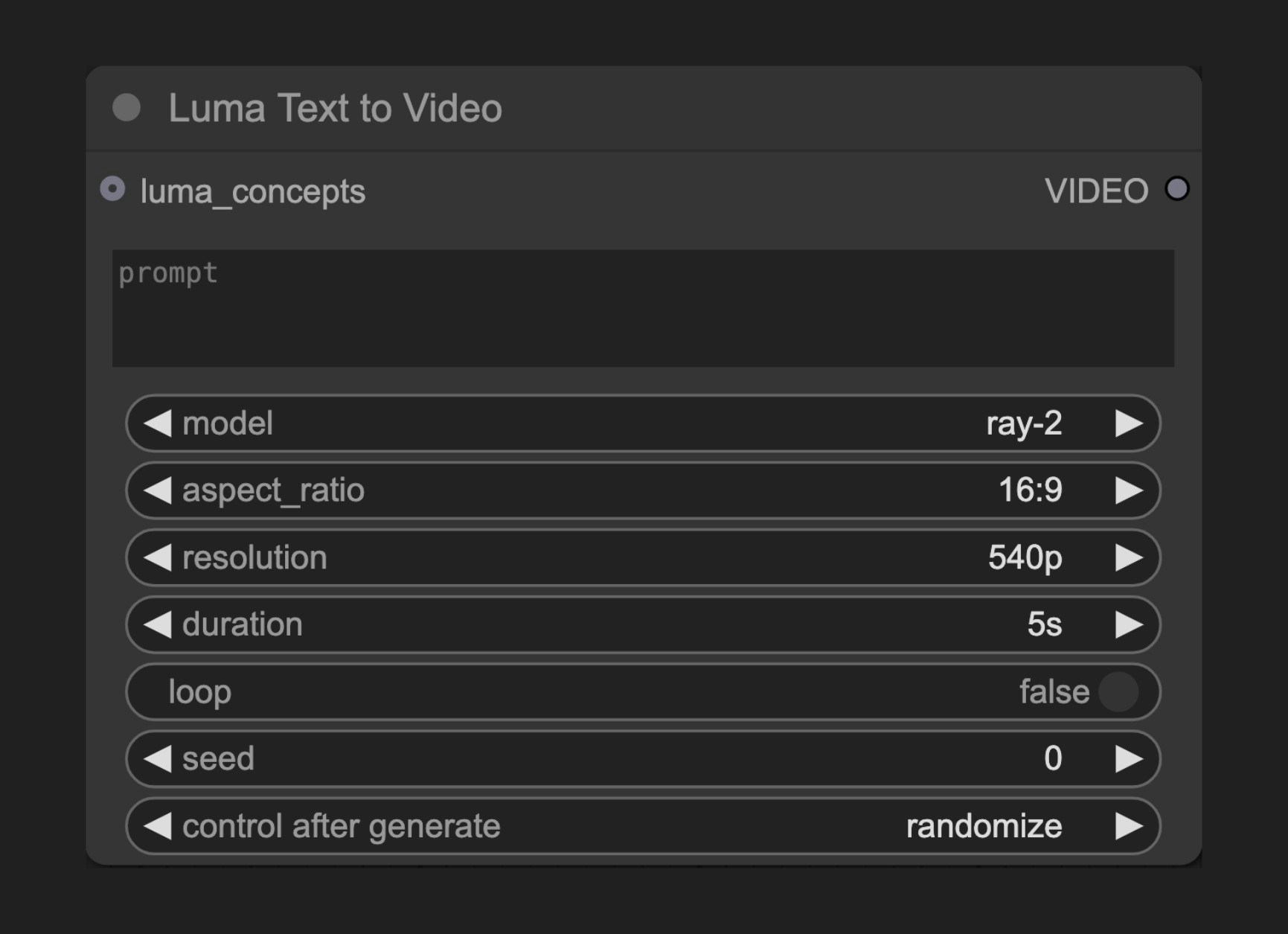
节点功能
此节点连接到Luma AI的文本到视频API,让用户能够通过详细的文本提示词生成动态视频内容。参数说明
基本参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| prompt | 字符串 | "" | 描述要生成视频内容的文本提示词 |
| model | 选择项 | - | 使用的视频生成模型 |
| aspect_ratio | 选择项 | ”ratio_16_9” | 视频宽高比 |
| resolution | 选择项 | ”res_540p” | 视频分辨率 |
| duration | 选择项 | - | 视频时长选项 |
| loop | 布尔值 | False | 是否循环播放视频 |
| seed | 整数 | 0 | 随机种子,用于决定节点是否需要重新运行;实际结果与种子无关 |
当使用 Ray 1.6 模型时,duration 和 resolution 参数将不会生效。
可选参数
| 参数 | 类型 | 说明 |
|---|---|---|
| luma_concepts | LUMA_CONCEPTS | 可选的摄像机概念,通过Luma Concepts节点控制摄像机运动 |
输出
| 输出 | 类型 | 说明 |
|---|---|---|
| VIDEO | 视频 | 生成的视频结果 |
使用示例
Luma Text to Video 工作流示例
Luma Text to Video 工作流示例
源码参考
[节点源码 (更新于2025-05-03)]Copy
Ask AI
class LumaTextToVideoGenerationNode(ComfyNodeABC):
"""
Generates videos synchronously based on prompt and output_size.
"""
RETURN_TYPES = (IO.VIDEO,)
DESCRIPTION = cleandoc(__doc__ or "") # Handle potential None value
FUNCTION = "api_call"
API_NODE = True
CATEGORY = "api node/video/Luma"
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"prompt": (
IO.STRING,
{
"multiline": True,
"default": "",
"tooltip": "Prompt for the video generation",
},
),
"model": ([model.value for model in LumaVideoModel],),
"aspect_ratio": (
[ratio.value for ratio in LumaAspectRatio],
{
"default": LumaAspectRatio.ratio_16_9,
},
),
"resolution": (
[resolution.value for resolution in LumaVideoOutputResolution],
{
"default": LumaVideoOutputResolution.res_540p,
},
),
"duration": ([dur.value for dur in LumaVideoModelOutputDuration],),
"loop": (
IO.BOOLEAN,
{
"default": False,
},
),
"seed": (
IO.INT,
{
"default": 0,
"min": 0,
"max": 0xFFFFFFFFFFFFFFFF,
"control_after_generate": True,
"tooltip": "Seed to determine if node should re-run; actual results are nondeterministic regardless of seed.",
},
),
},
"optional": {
"luma_concepts": (
LumaIO.LUMA_CONCEPTS,
{
"tooltip": "Optional Camera Concepts to dictate camera motion via the Luma Concepts node."
},
),
},
"hidden": {
"auth_token": "AUTH_TOKEN_COMFY_ORG",
},
}
def api_call(
self,
prompt: str,
model: str,
aspect_ratio: str,
resolution: str,
duration: str,
loop: bool,
seed,
luma_concepts: LumaConceptChain = None,
auth_token=None,
**kwargs,
):
duration = duration if model != LumaVideoModel.ray_1_6 else None
resolution = resolution if model != LumaVideoModel.ray_1_6 else None
operation = SynchronousOperation(
endpoint=ApiEndpoint(
path="/proxy/luma/generations",
method=HttpMethod.POST,
request_model=LumaGenerationRequest,
response_model=LumaGeneration,
),
request=LumaGenerationRequest(
prompt=prompt,
model=model,
resolution=resolution,
aspect_ratio=aspect_ratio,
duration=duration,
loop=loop,
concepts=luma_concepts.create_api_model() if luma_concepts else None,
),
auth_token=auth_token,
)
response_api: LumaGeneration = operation.execute()
operation = PollingOperation(
poll_endpoint=ApiEndpoint(
path=f"/proxy/luma/generations/{response_api.id}",
method=HttpMethod.GET,
request_model=EmptyRequest,
response_model=LumaGeneration,
),
completed_statuses=[LumaState.completed],
failed_statuses=[LumaState.failed],
status_extractor=lambda x: x.state,
auth_token=auth_token,
)
response_poll = operation.execute()
vid_response = requests.get(response_poll.assets.video)
return (VideoFromFile(BytesIO(vid_response.content)),)