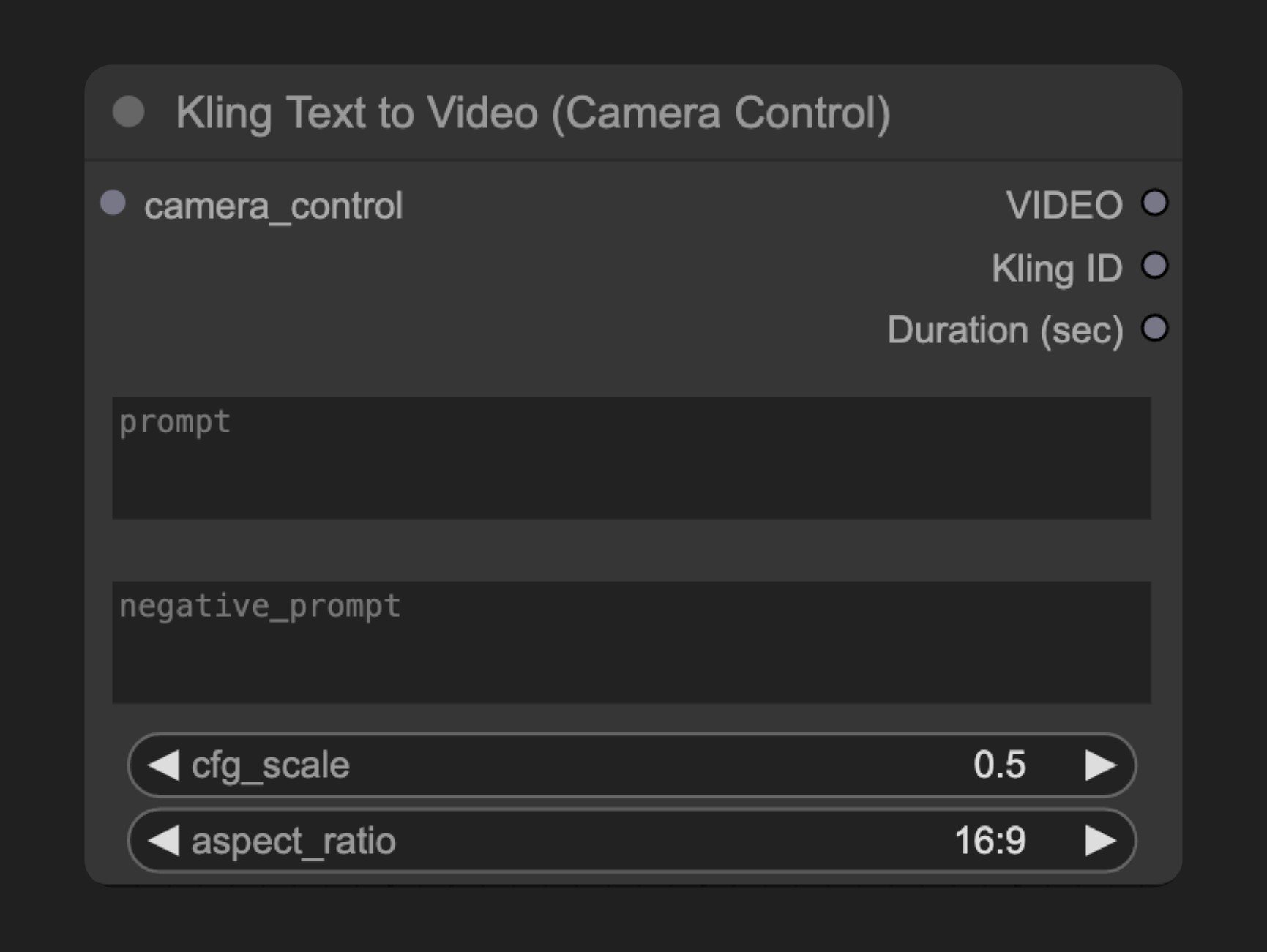
パラメータ
基本パラメータ
| パラメータ | 型 | デフォルト値 | 説明 |
|---|---|---|---|
| prompt | 文字列 | "" | 動画の内容を記述するテキストプロンプト |
| negative_prompt | 文字列 | "" | 動画に含めたくない要素 |
| cfg_scale | 浮動小数点数 | 7.0 | プロンプトへの従い具合を制御する値 |
| aspect_ratio | 選択項目 | ”16:9” | 出力動画のアスペクト比 |
| camera_control | CAMERA_CONTROL | - | Kling カメラ制御ノードから取得したカメラ設定 |
固定パラメータ
※以下のパラメータは固定されており、変更できません:- モデル:kling-v1-5
- モード:pro
- 再生時間:5秒
出力
| 出力 | 型 | 説明 |
|---|---|---|
| VIDEO | 動画 | 生成された動画 |
ソースコード
[ノードソースコード(2025-05-03 更新)]
class KlingCameraControlT2VNode(KlingTextToVideoNode):
"""
Kling Text to Video Camera Control Node. This node is a text to video node, but it supports controlling the camera.
Duration, mode, and model_name request fields are hard-coded because camera control is only supported in pro mode with the kling-v1-5 model at 5s duration as of 2025-05-02.
"""
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"prompt": model_field_to_node_input(
IO.STRING, KlingText2VideoRequest, "prompt", multiline=True
),
"negative_prompt": model_field_to_node_input(
IO.STRING,
KlingText2VideoRequest,
"negative_prompt",
multiline=True,
),
"cfg_scale": model_field_to_node_input(
IO.FLOAT, KlingText2VideoRequest, "cfg_scale"
),
"aspect_ratio": model_field_to_node_input(
IO.COMBO,
KlingText2VideoRequest,
"aspect_ratio",
enum_type=AspectRatio,
),
"camera_control": (
"CAMERA_CONTROL",
{
"tooltip": "Can be created using the Kling Camera Controls node. Controls the camera movement and motion during the video generation.",
},
),
},
"hidden": {"auth_token": "AUTH_TOKEN_COMFY_ORG"},
}
DESCRIPTION = "実世界の映像撮影技術を模倣したプロフェッショナルなカメラ動作を用いて、テキストを映画的な動画に変換します。ズーム、回転、パン、チルト、ファーストパーソンビューなどの仮想カメラ操作を制御しながら、元のテキスト内容への焦点を維持します。"
def api_call(
self,
prompt: str,
negative_prompt: str,
cfg_scale: float,
aspect_ratio: str,
camera_control: Optional[CameraControl] = None,
auth_token: Optional[str] = None,
):
return super().api_call(
model_name="kling-v1-5",
cfg_scale=cfg_scale,
mode="pro",
aspect_ratio=aspect_ratio,
duration="5",
prompt=prompt,
negative_prompt=negative_prompt,
camera_control=camera_control,
auth_token=auth_token,
)