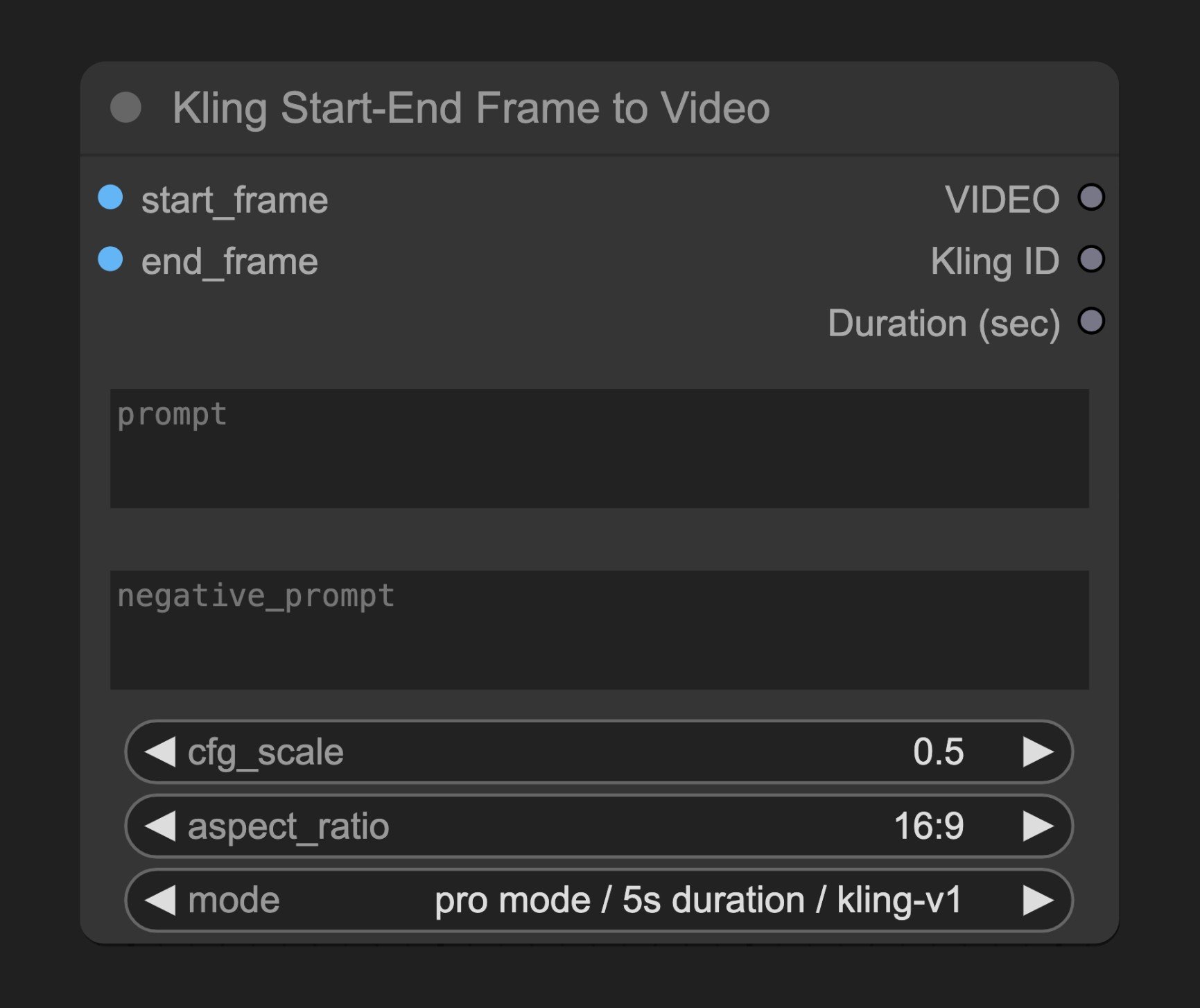
パラメーター
必須パラメーター
mode オプション
利用可能なモードの組み合わせ:- standard mode / 5s duration / kling-v1
- standard mode / 5s duration / kling-v1-5
- pro mode / 5s duration / kling-v1
- pro mode / 5s duration / kling-v1-5
- pro mode / 5s duration / kling-v1-6
- pro mode / 10s duration / kling-v1-5
- pro mode / 10s duration / kling-v1-6