- テキストから画像へ生成するワークフローの実行
- 拡散モデルの基本原理に関する概要的理解
- ワークフロー内の各ノードの機能と役割についての理解
- SD1.5モデルの基礎知識
テキストから画像へ(Text to Image)とは
テキストから画像へ(Text to Image) は、AIアート生成における基本的なプロセスであり、テキストによる説明文から対応する画像を生成します。その中心となるのは 拡散モデル(diffusion model) です。 テキストから画像へ生成するプロセスには、以下の要素が必要です:- アーティスト(画家): 画像生成モデル
- キャンバス(画布): 潜在空間(latent space)
- 画像の要件(プロンプト): 正のプロンプト(画像に含めたい要素)および負のプロンプト(画像に含めたくない要素)
ComfyUI テキストから画像へワークフローの実例ガイド
1. 準備
ComfyUI/models/checkpoints フォルダ内に、少なくとも1つのSD1.5モデルファイル(例:v1-5-pruned-emaonly-fp16.safetensors)が存在することを確認してください。
まだインストールしていない場合は、ComfyUIによるAIアート生成の始め方 の「モデルのインストール」セクションをご参照ください。
2. テキストから画像へワークフローの読み込み
下記の画像をダウンロードし、ComfyUIの画面にドラッグ&ドロップすることで、ワークフローを読み込みます:
3. モデルの読み込みと最初の画像生成
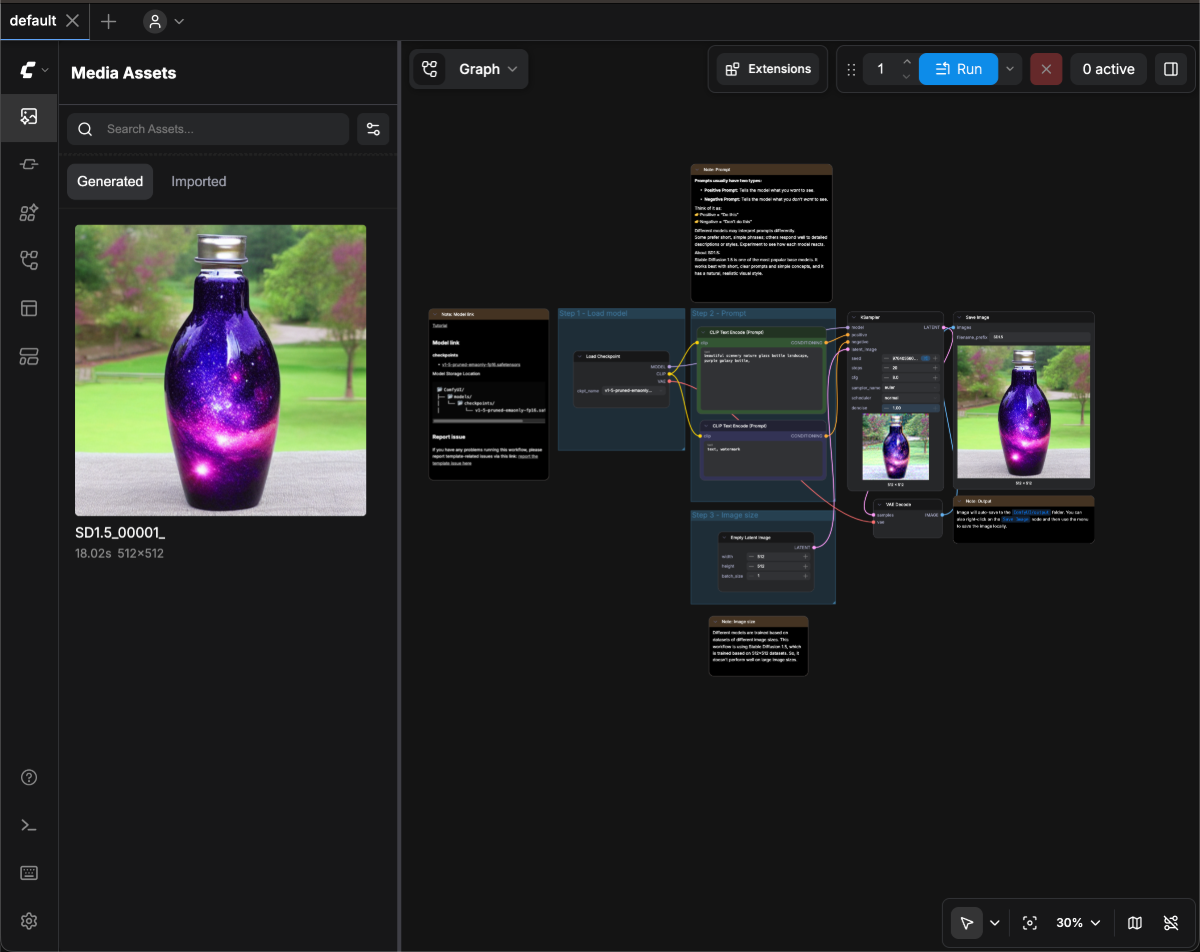
画像生成モデルのインストールが完了したら、下図の手順に従ってモデルを読み込み、最初の画像を生成してください。 図中の番号に従って、以下の手順を実行してください:
図中の番号に従って、以下の手順を実行してください:
- Load Checkpoint ノードで、矢印キーを使用するかテキスト領域をクリックして、v1-5-pruned-emaonly-fp16.safetensors が選択されていることを確認してください。左右の切り替え矢印に null と表示されていないことも確認してください。
Queueボタンをクリックするか、ショートカットCtrl + Enterを使用して画像生成を実行してください。
4. 実験を始める
CLIP Text Encoder のテキストを編集してみましょう。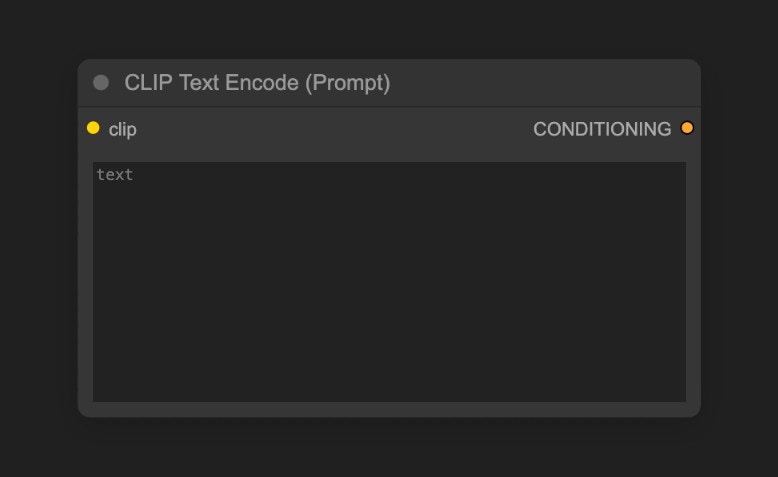
Positive は正のプロンプト(画像に含めたい要素)、Negative は負のプロンプト(画像に含めたくない要素)を表します。
SD1.5モデル向けの基本的なプロンプト作成の原則は以下の通りです:
- 可能な限り英語を使用する
- プロンプトは英語のカンマ
,で区切る - 長文ではなく、短いフレーズを使用する
- より具体的な記述を使用する
(golden hour:1.2)のように、特定のキーワードの重みを高める表現を使い、画像への出現確率を上げることができます。ここで1.2は重み、golden hourはキーワードですmasterpiece, best quality, 4kのようなキーワードを用いて、生成品質を向上させることができます
テキストから画像へ生成の動作原理
テキストから画像へ生成する全体のプロセスは、逆拡散プロセス(reverse diffusion process) と理解できます。私たちがダウンロードした v1-5-pruned-emaonly-fp16.safetensors は、事前に学習済みのモデルであり、純粋なガウスノイズから目的の画像を生成することができます。私たちは単にプロンプトを入力するだけで、ランダムノイズのデノイズを通じて目的の画像を生成できます。 以下の2つの概念を理解しておく必要があります:- 潜在空間(Latent Space): 潜在空間は、拡散モデルにおける抽象的なデータ表現方法です。画像をピクセル空間から潜在空間へ変換することで、ストレージ容量を削減し、拡散モデルの学習やデノイズの複雑さを軽減できます。これは、建築家が建物(ピクセル空間)に直接設計するのではなく、設計図(潜在空間)を使って設計するのと同様で、構造的特徴を維持しつつ、大幅に修正コストを低減できます。
- ピクセル空間(Pixel Space): ピクセル空間は、画像の保存領域であり、私たちが最終的に目にする画像で、ピクセル値を格納するために使用されます。
- Denoising Diffusion Probabilistic Models (DDPM)
- Denoising Diffusion Implicit Models (DDIM)
- High-Resolution Image Synthesis with Latent Diffusion Models
ComfyUI テキストから画像へワークフローのノード解説
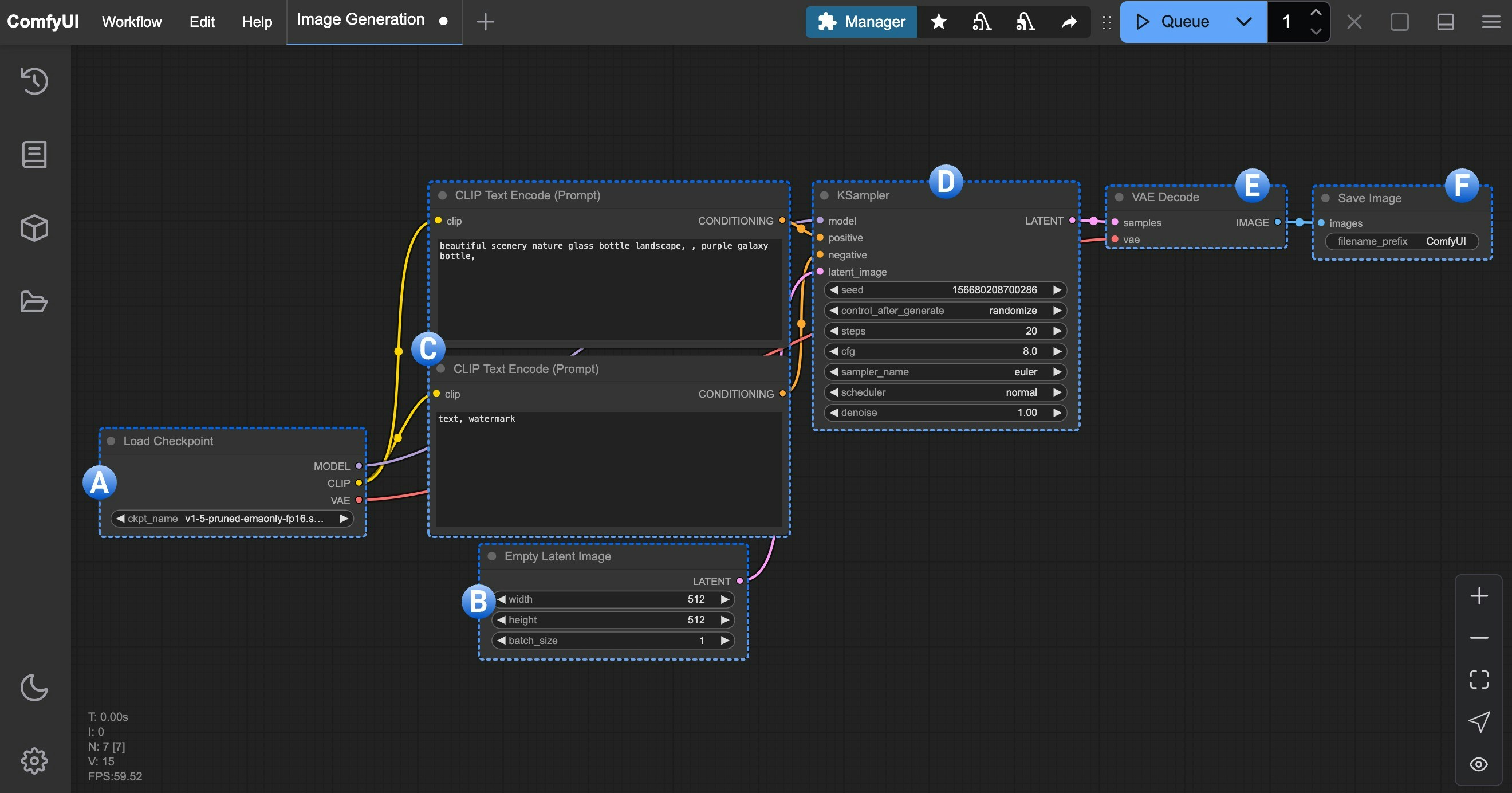
A. Load Checkpoint ノード
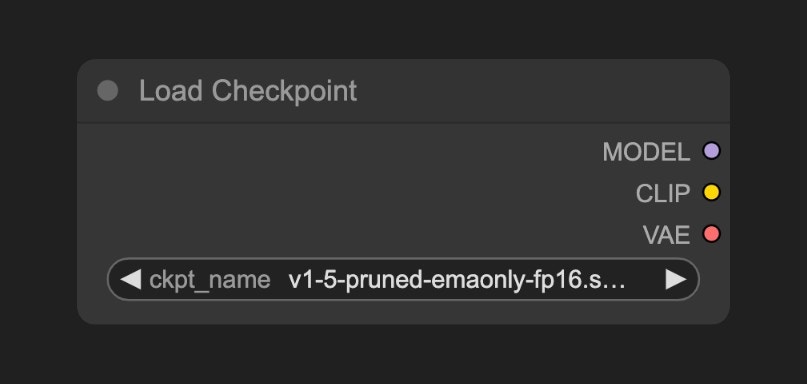
checkpoint には通常、MODEL (UNet)、CLIP、VAE の3つのコンポーネントが含まれます。
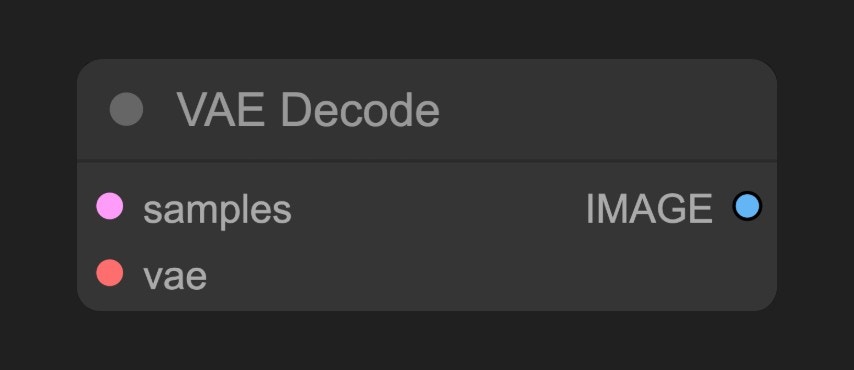
MODEL (UNet):拡散プロセス中のノイズ予測および画像生成を担当するUNetモデルCLIP:テキストプロンプトをモデルが理解可能なベクトルに変換するテキストエンコーダ。モデルはテキストプロンプトを直接理解できないため、この変換が必要ですVAE:画像をピクセル空間と潜在空間の間で相互変換する変分オートエンコーダ(Variational AutoEncoder)。拡散モデルは潜在空間で動作しますが、私たちの画像はピクセル空間にあるため、この変換が必要です
B. Empty Latent Image ノード
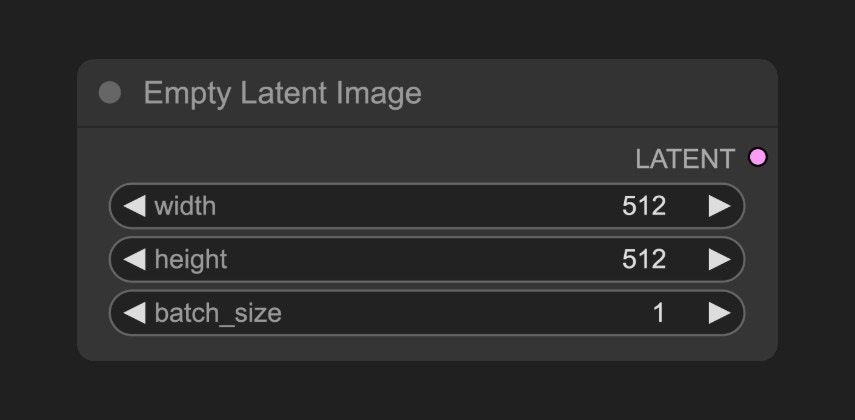
C. CLIP Text Encoder ノード
- KSamplerノードに接続されている
Positive条件入力は、正のプロンプト(画像に含めたい要素)を表します - KSamplerノードに接続されている
Negative条件入力は、負のプロンプト(画像に含めたくない要素)を表します
Load Checkpoint ノードから提供される CLIP コンポーネントによって意味ベクトルにエンコードされ、KSamplerノードへ条件として出力されます。
D. KSampler ノード
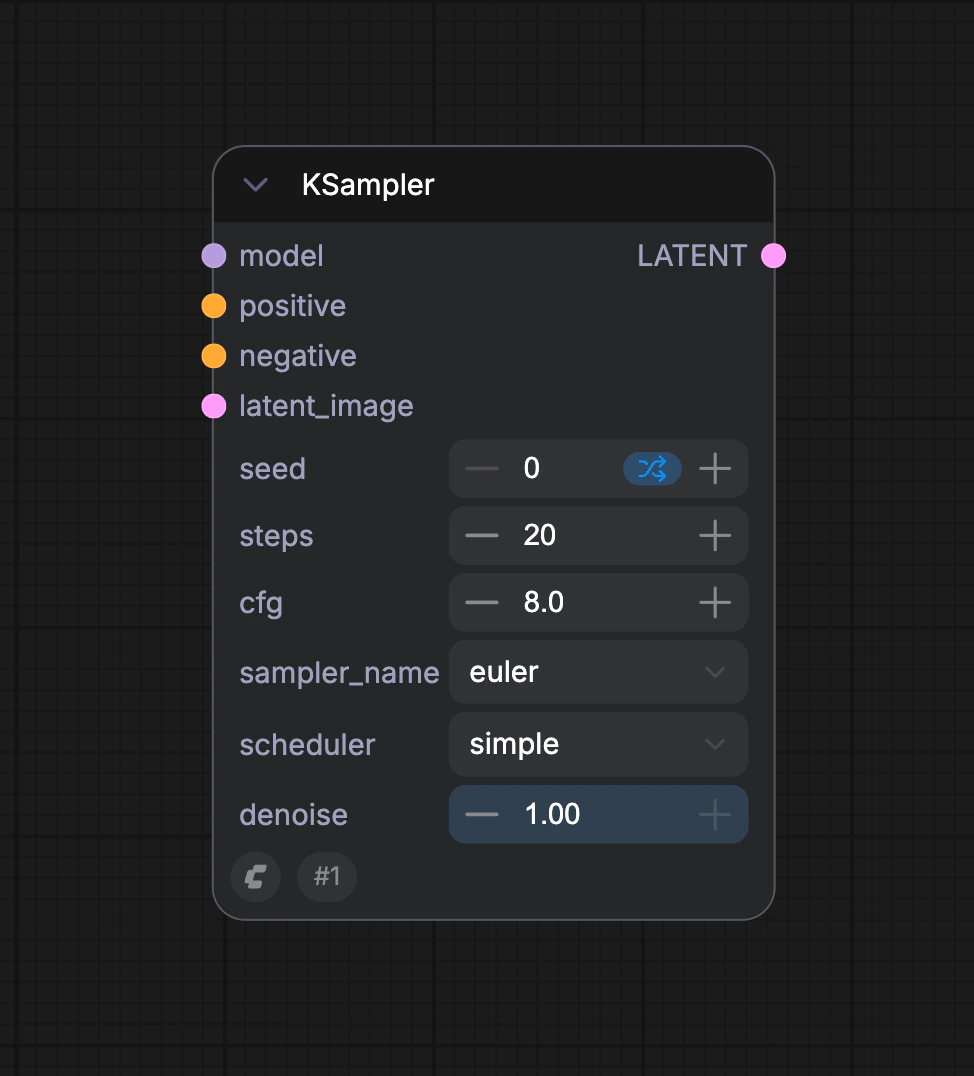
KSamplerノードでは、潜在空間が
seed を初期化パラメータとしてランダムノイズを構築し、意味ベクトル Positive および Negative が拡散モデルへの条件として入力されます。
その後、steps パラメータで指定されたデノイズステップ数に従ってデノイズが実行されます。各デノイズステップでは、denoise パラメータで指定されたデノイズ強度係数を用いて潜在空間のデノイズが行われ、新しい潜在空間画像が生成されます。
E. VAE Decode ノード
F. Save Image ノード
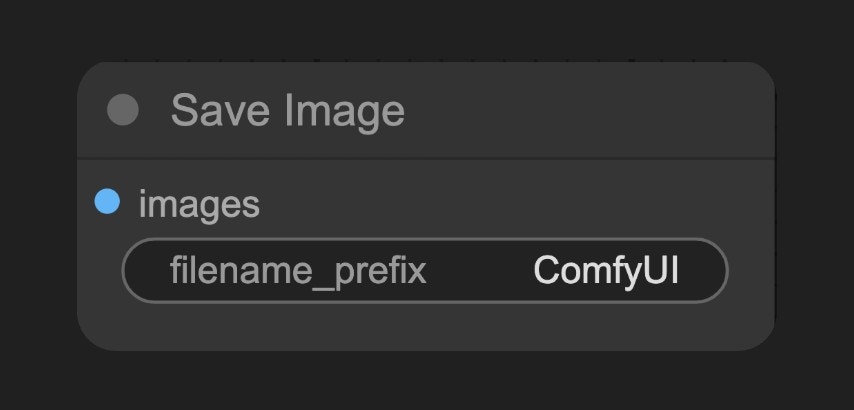
ComfyUI/output フォルダに保存します。
SD1.5モデルの紹介
SD1.5(Stable Diffusion 1.5) は、Stability AI が開発したAI画像生成モデルです。Stable Diffusionシリーズの基盤となるバージョンであり、512×512 解像度の画像で学習されています。そのため、この解像度での画像生成に特に優れています。サイズは約4GBで、一般向けGPU(例:6GB VRAM) 上でもスムーズに動作します。現在、SD1.5は豊かなエコシステムを有しており、ControlNetやLoRAなどの多様なプラグインおよび最適化ツールをサポートしています。 AIアート生成におけるマイルストーンモデルとして、SD1.5はオープンソースである点、軽量なアーキテクチャ、そして豊富なエコシステムといった特徴から、今なお最良の入門モデルです。SDXL/SD3などの新バージョンがリリースされていますが、一般向けハードウェアにおけるコストパフォーマンスは、依然として他を凌いでいます。基本情報
- リリース日: 2022年10月
- コアアーキテクチャ: 潜在拡散モデル(Latent Diffusion Model:LDM)に基づく
- 学習データ: LAION-Aesthetics v2.5データセット(約5億9千万ステップの学習)
- オープンソース特性: モデル、コード、学習データのすべてが完全にオープンソース
強みと限界
モデルの強み:- 軽量性:サイズが小さく、約4GBで、一般向けGPU上でスムーズに動作
- 導入障壁が低い:幅広いプラグインおよび最適化ツールをサポート
- 成熟したエコシステム:豊富なプラグインおよびツールのサポート
- 生成速度が速い:一般向けGPU上でスムーズに動作
- 細部の処理:手や複雑なライティングにおいて歪みが生じやすい
- 解像度の制限:1024×1024の解像度を直接生成すると品質が低下
- プロンプト依存性:効果的な制御には正確な英語による記述が必要