- インペインティングワークフローを用いた画像の編集方法
- ComfyUIのマスクエディタを用いたマスク作成方法
VAE Encoder (for Inpainting)ノード
局部再描画(インペインティング)とは
AIによる画像生成において、全体としては満足できる画像が得られたものの、不要な要素や誤った生成結果(例:不自然な身体部位など)が含まれている場合があります。このような場合、画像全体を再生成すると、全く異なる結果になってしまう可能性があるため、特定の領域のみを修正する「局部再描画(インペインティング)」が非常に有効です。 これは、画家(AIモデル) に絵を描かせた後、その完成した作品の一部だけを修正したいという状況に似ています。つまり、私たちは画家に対して、どの領域を修正すべきか(マスク) を明示し、その後、その指示に基づいて再び描き直してもらう(再描画/インペインティング) というプロセスになります。 代表的なインペインティングの活用シーンには以下のようなものがあります:- 欠陥修復:不要な物体の除去、AI生成による不自然な身体部位の修正など
- ディテール最適化:局所的な要素の精密な調整(例:衣装の質感変更、表情の微調整)
- その他さまざまな応用シーン
ComfyUI 局部再描画ワークフローの実例
モデルおよびリソースの準備
1. モデルのインストール
以下のファイルをダウンロードし、ComfyUI/models/checkpoints フォルダに保存してください:512-inpainting-ema.safetensors
2. 局部再描画用の入力画像
以下の画像をダウンロードし、本チュートリアルの入力画像として使用します:
この画像には既にアルファチャンネル(透過マスク)が含まれているため、マスクを手動で描く必要はありません。ただし、本チュートリアルでは後ほどマスクエディタを用いたマスク作成方法も解説します。
3. 局部再描画ワークフロー
以下の画像をダウンロードし、ComfyUIのキャンバス上にドラッグ&ドロップすることで、ワークフローを読み込みます:
ComfyUI 局部再描画ワークフローの解説
下図の手順に従って、ワークフローが正しく実行されるよう確認してください。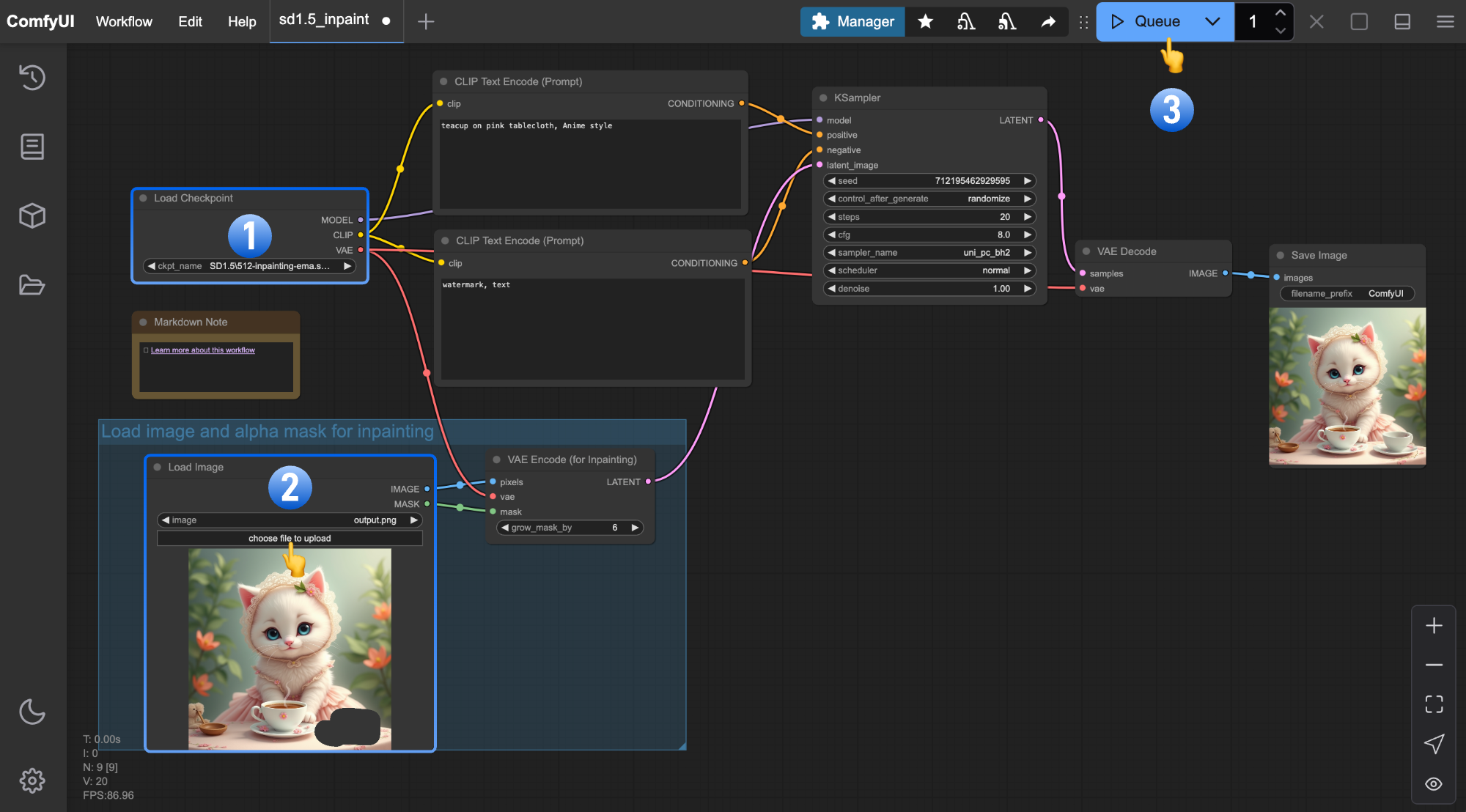
Load Checkpointノードが512-inpainting-ema.safetensorsを正しく読み込んでいることを確認します- 入力画像を
Load Imageノードにアップロードします Queueボタンをクリックするか、Ctrl + Enterキーで画像生成を実行します

これは、当該モデルがインペインティング専用に設計・最適化されているためであり、生成領域をより正確に制御でき、結果として優れた再描画品質を実現します。 先ほどご紹介した「画家」というアナロジーを思い出してください。異なるモデルは、それぞれ得意分野や限界を持つ「画家」のような存在です。適切なモデルを選択することで、より理想的な生成結果を得ることが可能になります。 さらに良い結果を得るためのアプローチとして、以下の方法を試すことができます:
- プロンプト(正のプロンプト/負のプロンプト)をより具体的な記述に変更する
KSamplerのシード値を変えて複数回実行し、異なる生成結果を試す- 本チュートリアルで学ぶマスクエディタを活用し、一度生成された画像を再度インペインティングして、最終的に満足のいく結果を得る
alpha 透過チャンネル(編集対象領域)が含まれているため、マスクの手動描画は不要ですが、実際の運用ではマスクエディタを頻繁に用いてマスクを作成することになります。
マスクエディタの使用方法
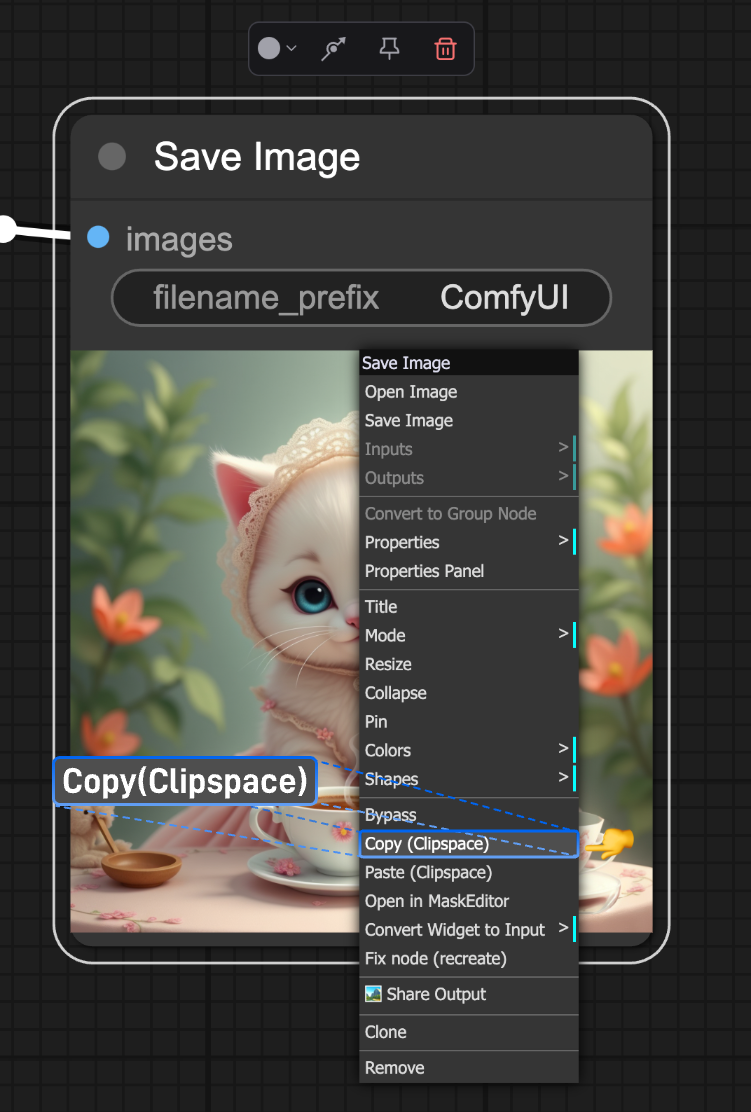
まず、Save Image ノードを右クリックし、「Copy(Clipspace)」を選択して、現在の画像をクリップボードにコピーします:
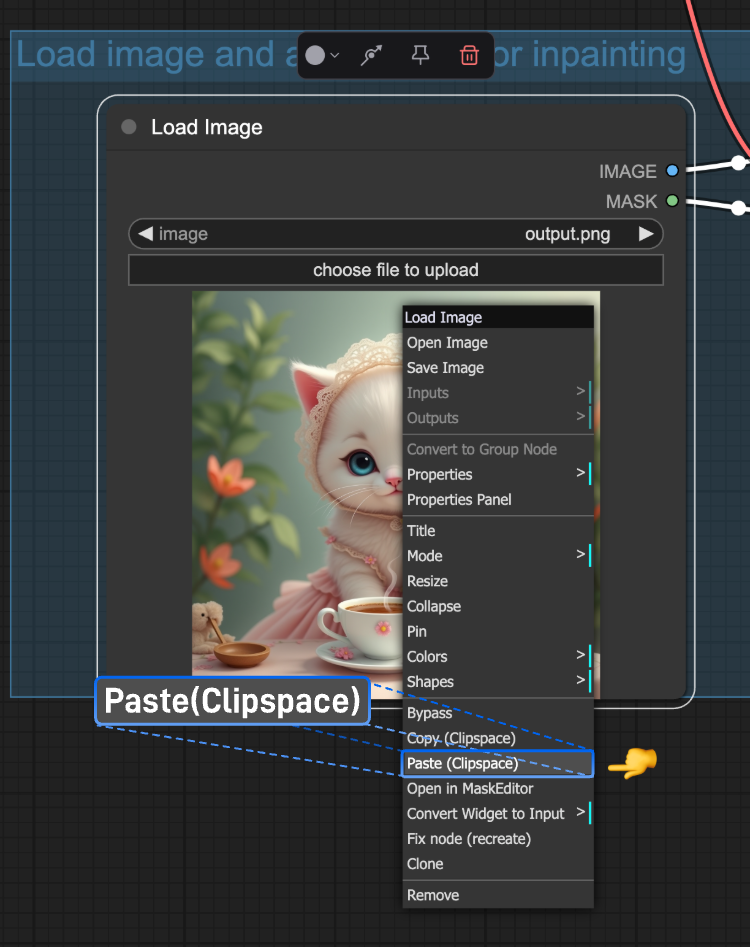
Load Image ノードを右クリックし、「Paste(Clipspace)」を選択して、クリップボードから画像を貼り付けます:
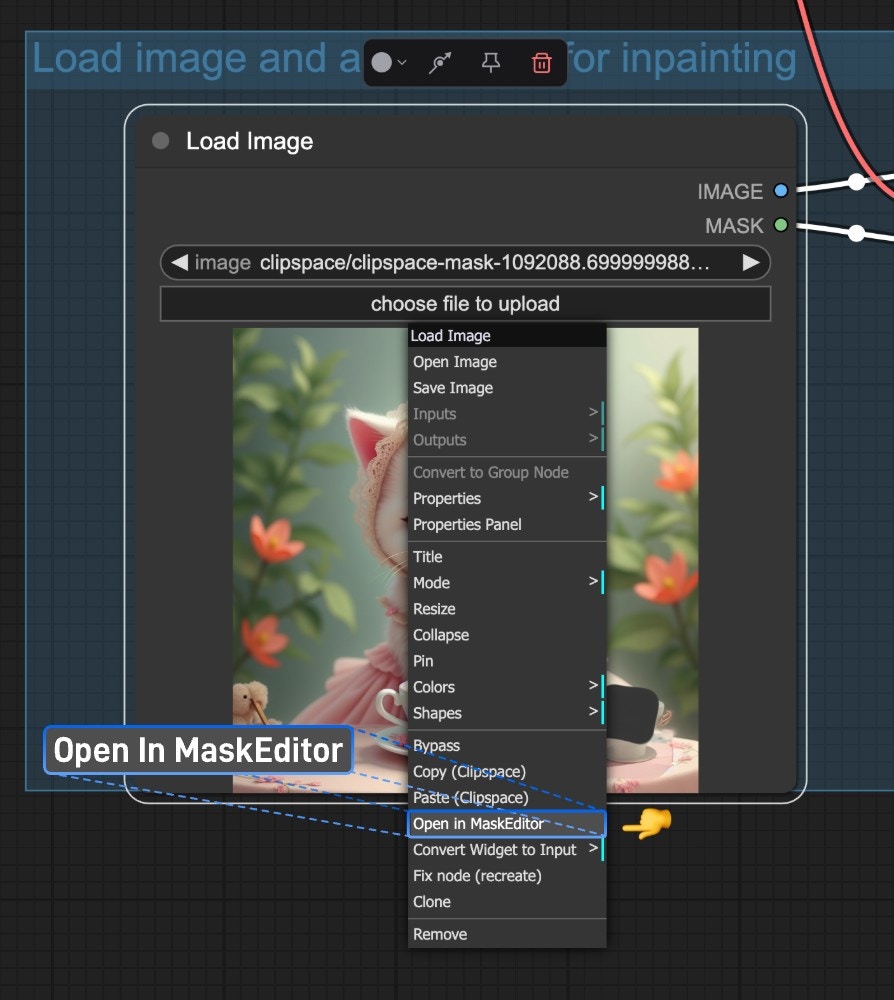
Load Image ノードをもう一度右クリックし、「Open in MaskEditor」を選択して、マスクエディタを開きます:
- 右側パネルでブラシの各種パラメータ(サイズ・不透明度など)を調整できます
- 間違えた部分は消しゴムツールで修正可能です
- 編集が完了したら
Saveボタンをクリックしてマスクを保存します
VAE Encoder (for Inpainting) ノードへの mask 入力として使用され、エンコード処理に組み込まれます。
その後、プロンプトを調整して再生成を繰り返し、満足のいく結果が得られるまで試行してください。
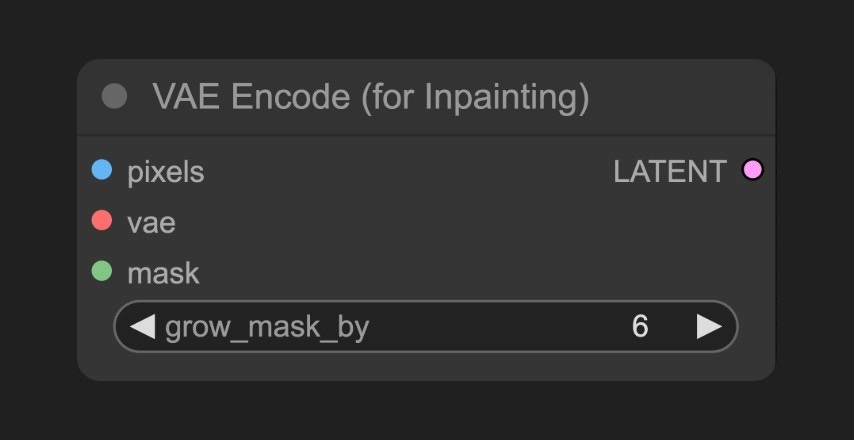
VAE Encoder (for Inpainting) ノード
本ワークフローを テキスト→画像(Text-to-Image) や 画像→画像(Image-to-Image) のワークフローと比較すると、主な違いは VAE 部分の条件入力にあることに気づくでしょう。本ワークフローでは、インペインティング専用に設計された
VAE Encoder (for Inpainting) ノード を使用しており、これにより生成領域をより正確に制御し、高品質な再描画結果を得ることができます。
出力パラメータ