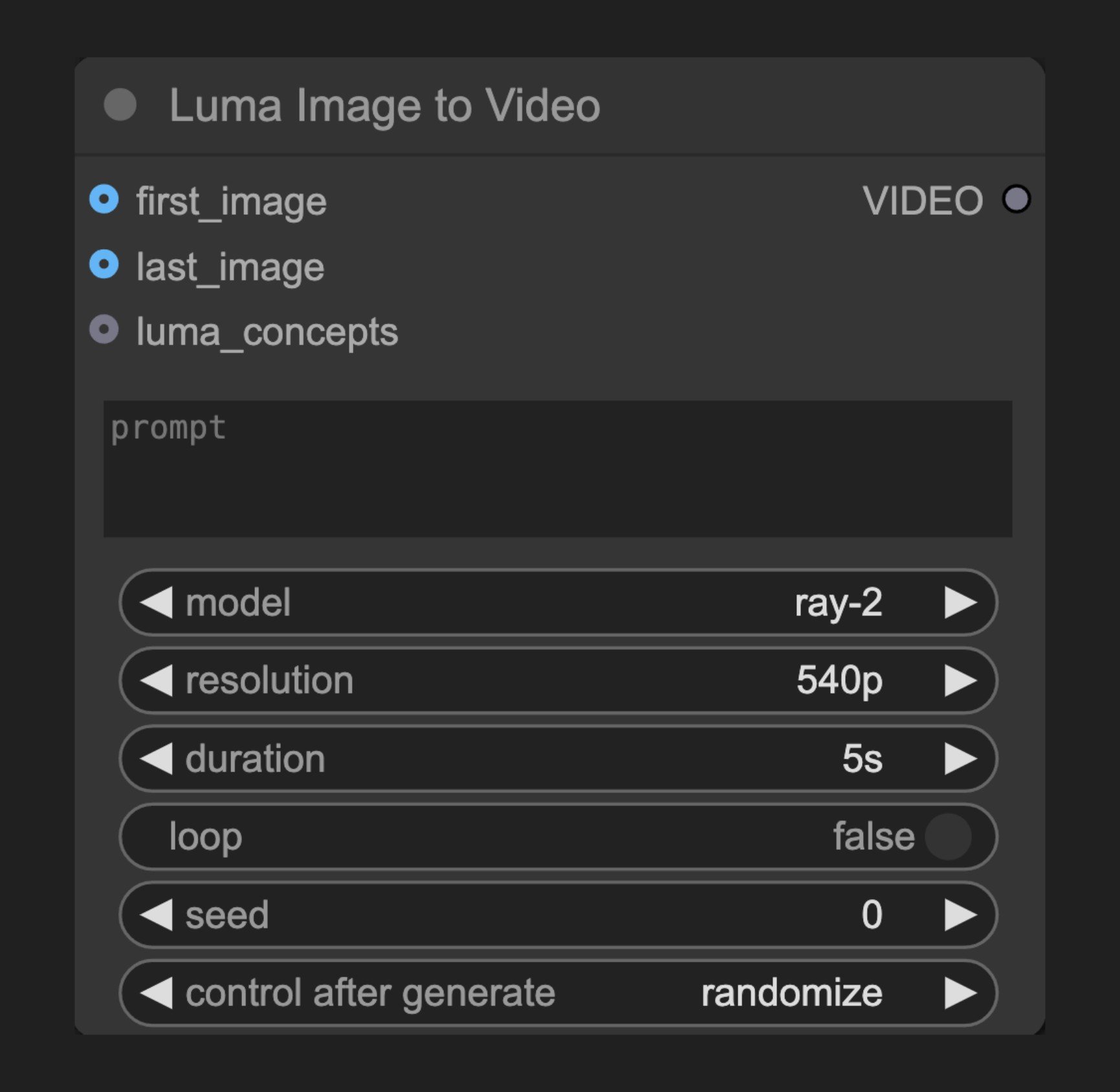
ノードの機能
このノードは Luma AI の「画像→動画」API に接続し、入力画像からダイナミックな動画を生成します。画像の内容を理解し、元のビジュアルスタイルを維持したまま自然で一貫性のある動きを生成します。テキストプロンプトと組み合わせることで、ユーザーは動画のダイナミックな効果を正確に制御できます。パラメータ
基本パラメータ
| パラメータ | 型 | デフォルト値 | 説明 |
|---|---|---|---|
| prompt | 文字列 | "" | 動画の動きおよびコンテンツを記述するテキストプロンプト |
| model | 選択肢 | - | 使用する動画生成モデル |
| resolution | 選択肢 | ”540p” | 出力動画の解像度 |
| duration | 選択肢 | - | 動画の長さオプション |
| loop | ブール値 | False | 動画をループ再生するかどうか |
| seed | 整数 | 0 | ノード再実行時のシード値(実際の結果はシードに依存せず非決定的) |
オプションパラメータ
| パラメータ | 型 | 説明 |
|---|---|---|
| first_image | 画像 | 動画の最初のフレーム(last_image が未指定の場合は必須) |
| last_image | 画像 | 動画の最後のフレーム(first_image が未指定の場合は必須) |
| luma_concepts | LUMA_CONCEPTS | カメラの動きやショットスタイルを制御するためのコンセプト |
要件
- first_image または last_image のいずれか一方は必ず指定する必要があります
- 各画像入力(
first_imageおよびlast_image)には、1 枚の画像のみを指定できます
出力
| 出力 | 型 | 説明 |
|---|---|---|
| VIDEO | 動画 | 生成された動画 |
使用例
Luma Image to Video ワークフローの例
Luma Image to Video ワークフローチュートリアル
ソースコード
[ノードソースコード(2025-05-03 更新)]
class LumaImageToVideoGenerationNode(ComfyNodeABC):
"""
Generates videos synchronously based on prompt, input images, and output_size.
"""
RETURN_TYPES = (IO.VIDEO,)
DESCRIPTION = cleandoc(__doc__ or "") # Handle potential None value
FUNCTION = "api_call"
API_NODE = True
CATEGORY = "api node/video/Luma"
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"prompt": (
IO.STRING,
{
"multiline": True,
"default": "",
"tooltip": "Prompt for the video generation",
},
),
"model": ([model.value for model in LumaVideoModel],),
# "aspect_ratio": ([ratio.value for ratio in LumaAspectRatio], {
# "default": LumaAspectRatio.ratio_16_9,
# }),
"resolution": (
[resolution.value for resolution in LumaVideoOutputResolution],
{
"default": LumaVideoOutputResolution.res_540p,
},
),
"duration": ([dur.value for dur in LumaVideoModelOutputDuration],),
"loop": (
IO.BOOLEAN,
{
"default": False,
},
),
"seed": (
IO.INT,
{
"default": 0,
"min": 0,
"max": 0xFFFFFFFFFFFFFFFF,
"control_after_generate": True,
"tooltip": "Seed to determine if node should re-run; actual results are nondeterministic regardless of seed.",
},
),
},
"optional": {
"first_image": (
IO.IMAGE,
{"tooltip": "First frame of generated video."},
),
"last_image": (IO.IMAGE, {"tooltip": "Last frame of generated video."}),
"luma_concepts": (
LumaIO.LUMA_CONCEPTS,
{
"tooltip": "Optional Camera Concepts to dictate camera motion via the Luma Concepts node."
},
),
},
"hidden": {
"auth_token": "AUTH_TOKEN_COMFY_ORG",
},
}
def api_call(
self,
prompt: str,
model: str,
resolution: str,
duration: str,
loop: bool,
seed,
first_image: torch.Tensor = None,
last_image: torch.Tensor = None,
luma_concepts: LumaConceptChain = None,
auth_token=None,
**kwargs,
):
if first_image is None and last_image is None:
raise Exception(
"At least one of first_image and last_image requires an input."
)
keyframes = self._convert_to_keyframes(first_image, last_image, auth_token)
duration = duration if model != LumaVideoModel.ray_1_6 else None
resolution = resolution if model != LumaVideoModel.ray_1_6 else None
operation = SynchronousOperation(
endpoint=ApiEndpoint(
path="/proxy/luma/generations",
method=HttpMethod.POST,
request_model=LumaGenerationRequest,
response_model=LumaGeneration,
),
request=LumaGenerationRequest(
prompt=prompt,
model=model,
aspect_ratio=LumaAspectRatio.ratio_16_9, # ignored, but still needed by the API for some reason
resolution=resolution,
duration=duration,
loop=loop,
keyframes=keyframes,
concepts=luma_concepts.create_api_model() if luma_concepts else None,
),
auth_token=auth_token,
)
response_api: LumaGeneration = operation.execute()
operation = PollingOperation(
poll_endpoint=ApiEndpoint(
path=f"/proxy/luma/generations/{response_api.id}",
method=HttpMethod.GET,
request_model=EmptyRequest,
response_model=LumaGeneration,
),
completed_statuses=[LumaState.completed],
failed_statuses=[LumaState.failed],
status_extractor=lambda x: x.state,
auth_token=auth_token,
)
response_poll = operation.execute()
vid_response = requests.get(response_poll.assets.video)
return (VideoFromFile(BytesIO(vid_response.content)),)
def _convert_to_keyframes(
self,
first_image: torch.Tensor = None,
last_image: torch.Tensor = None,
auth_token=None,
):
if first_image is None and last_image is None:
return None
frame0 = None
frame1 = None
if first_image is not None:
download_urls = upload_images_to_comfyapi(
first_image, max_images=1, auth_token=auth_token
)
frame0 = LumaImageReference(type="image", url=download_urls[0])
if last_image is not None:
download_urls = upload_images_to_comfyapi(
last_image, max_images=1, auth_token=auth_token
)
frame1 = LumaImageReference(type="image", url=download_urls[0])
return LumaKeyframes(frame0=frame0, frame1=frame1)