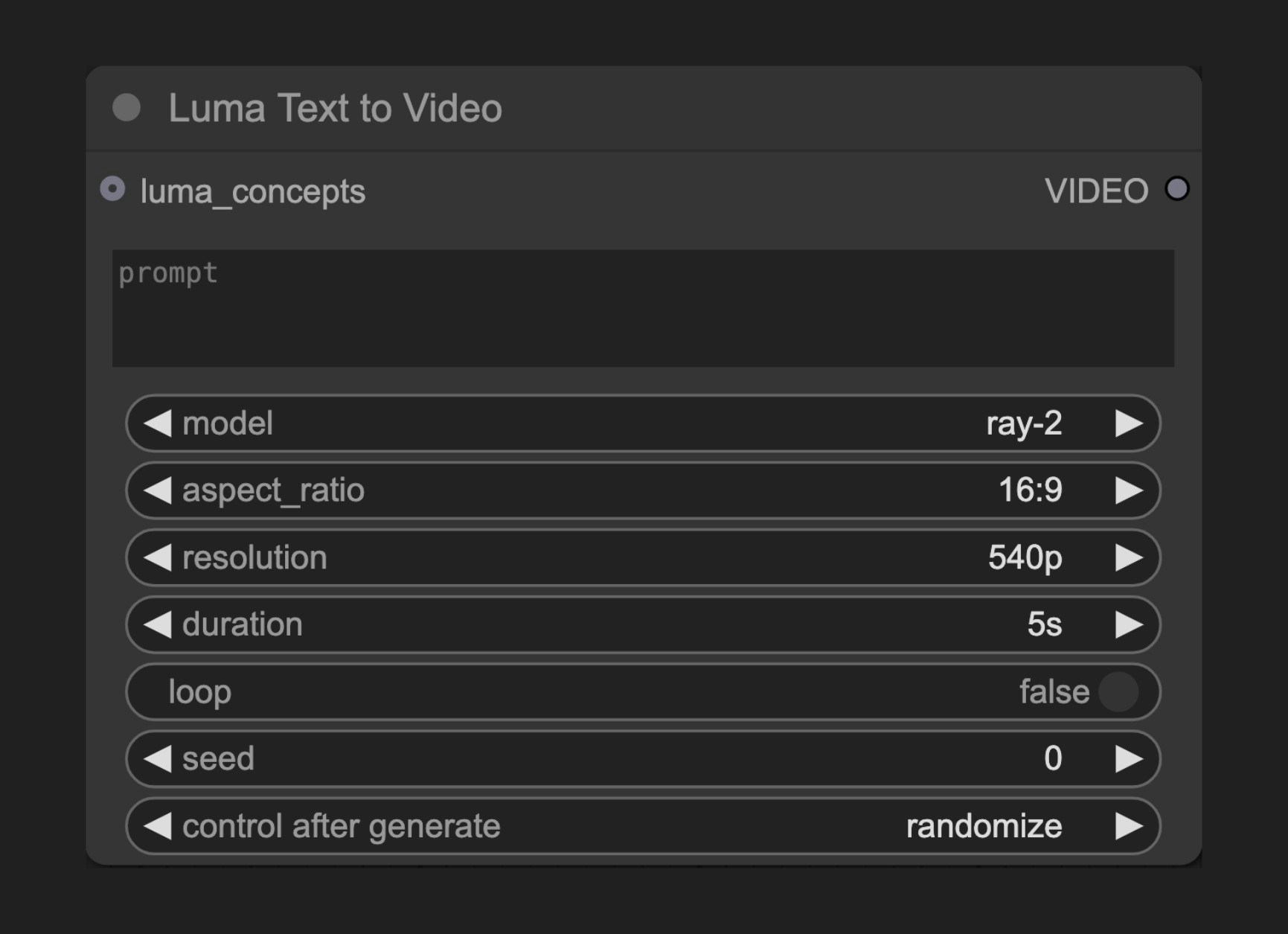
ノードの機能
このノードは Luma AI の「テキストから動画へ」API に接続し、詳細なテキストプロンプトに基づいてダイナミックな動画コンテンツを生成できるようにします。パラメーター
基本パラメーター
| パラメーター | 型 | デフォルト値 | 説明 |
|---|---|---|---|
| prompt | 文字列 | "" | 生成する動画の内容を記述するテキストプロンプト |
| model | 選択肢 | - | 使用する動画生成モデル |
| aspect_ratio | 選択肢 | ”ratio_16_9” | 動画のアスペクト比 |
| resolution | 選択肢 | ”res_540p” | 動画の解像度 |
| duration | 選択肢 | - | 動画の長さオプション |
| loop | ブール値 | False | 動画をループ再生するかどうか |
| seed | 整数 | 0 | ノードの再実行を制御するためのシード値(実際の出力はシードに依存せず非決定的) |
Ray 1.6 モデルを使用する場合、
duration および resolution パラメーターは無効になります。オプションパラメーター
| パラメーター | 型 | 説明 |
|---|---|---|
| luma_concepts | LUMA_CONCEPTS | Luma Concepts ノードを介してカメラモーションを制御するためのカメラコンセプト(任意) |
出力
| 出力 | 型 | 説明 |
|---|---|---|
| VIDEO | 動画 | 生成された動画 |
使用例
Luma Text to Video ワークフローの例
Luma Text to Video ワークフローの例
ソースコード
[ノードのソースコード(2025-05-03 更新)]
class LumaTextToVideoGenerationNode(ComfyNodeABC):
"""
Generates videos synchronously based on prompt and output_size.
"""
RETURN_TYPES = (IO.VIDEO,)
DESCRIPTION = cleandoc(__doc__ or "") # Handle potential None value
FUNCTION = "api_call"
API_NODE = True
CATEGORY = "api node/video/Luma"
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"prompt": (
IO.STRING,
{
"multiline": True,
"default": "",
"tooltip": "Prompt for the video generation",
},
),
"model": ([model.value for model in LumaVideoModel],),
"aspect_ratio": (
[ratio.value for ratio in LumaAspectRatio],
{
"default": LumaAspectRatio.ratio_16_9,
},
),
"resolution": (
[resolution.value for resolution in LumaVideoOutputResolution],
{
"default": LumaVideoOutputResolution.res_540p,
},
),
"duration": ([dur.value for dur in LumaVideoModelOutputDuration],),
"loop": (
IO.BOOLEAN,
{
"default": False,
},
),
"seed": (
IO.INT,
{
"default": 0,
"min": 0,
"max": 0xFFFFFFFFFFFFFFFF,
"control_after_generate": True,
"tooltip": "Seed to determine if node should re-run; actual results are nondeterministic regardless of seed.",
},
),
},
"optional": {
"luma_concepts": (
LumaIO.LUMA_CONCEPTS,
{
"tooltip": "Optional Camera Concepts to dictate camera motion via the Luma Concepts node."
},
),
},
"hidden": {
"auth_token": "AUTH_TOKEN_COMFY_ORG",
},
}
def api_call(
self,
prompt: str,
model: str,
aspect_ratio: str,
resolution: str,
duration: str,
loop: bool,
seed,
luma_concepts: LumaConceptChain = None,
auth_token=None,
**kwargs,
):
duration = duration if model != LumaVideoModel.ray_1_6 else None
resolution = resolution if model != LumaVideoModel.ray_1_6 else None
operation = SynchronousOperation(
endpoint=ApiEndpoint(
path="/proxy/luma/generations",
method=HttpMethod.POST,
request_model=LumaGenerationRequest,
response_model=LumaGeneration,
),
request=LumaGenerationRequest(
prompt=prompt,
model=model,
resolution=resolution,
aspect_ratio=aspect_ratio,
duration=duration,
loop=loop,
concepts=luma_concepts.create_api_model() if luma_concepts else None,
),
auth_token=auth_token,
)
response_api: LumaGeneration = operation.execute()
operation = PollingOperation(
poll_endpoint=ApiEndpoint(
path=f"/proxy/luma/generations/{response_api.id}",
method=HttpMethod.GET,
request_model=EmptyRequest,
response_model=LumaGeneration,
),
completed_statuses=[LumaState.completed],
failed_statuses=[LumaState.failed],
status_extractor=lambda x: x.state,
auth_token=auth_token,
)
response_poll = operation.execute()
vid_response = requests.get(response_poll.assets.video)
return (VideoFromFile(BytesIO(vid_response.content)),)