ACE-Step ComfyUI 文本到音频生成工作流示例
1. 工作流及相关模型下载
点击下面的按钮下载对应的工作流文件,拖入 ComfyUI 中即可加载对应的工作流信息,对应工作流已包含模型下载信息。下载 Json 格式工作流文件
你也可以手动下载ace_step_v1_3.5b.safetensors 后保存到ComfyUI/models/checkpoints 文件夹下
2. 按步骤完成工作流的运行
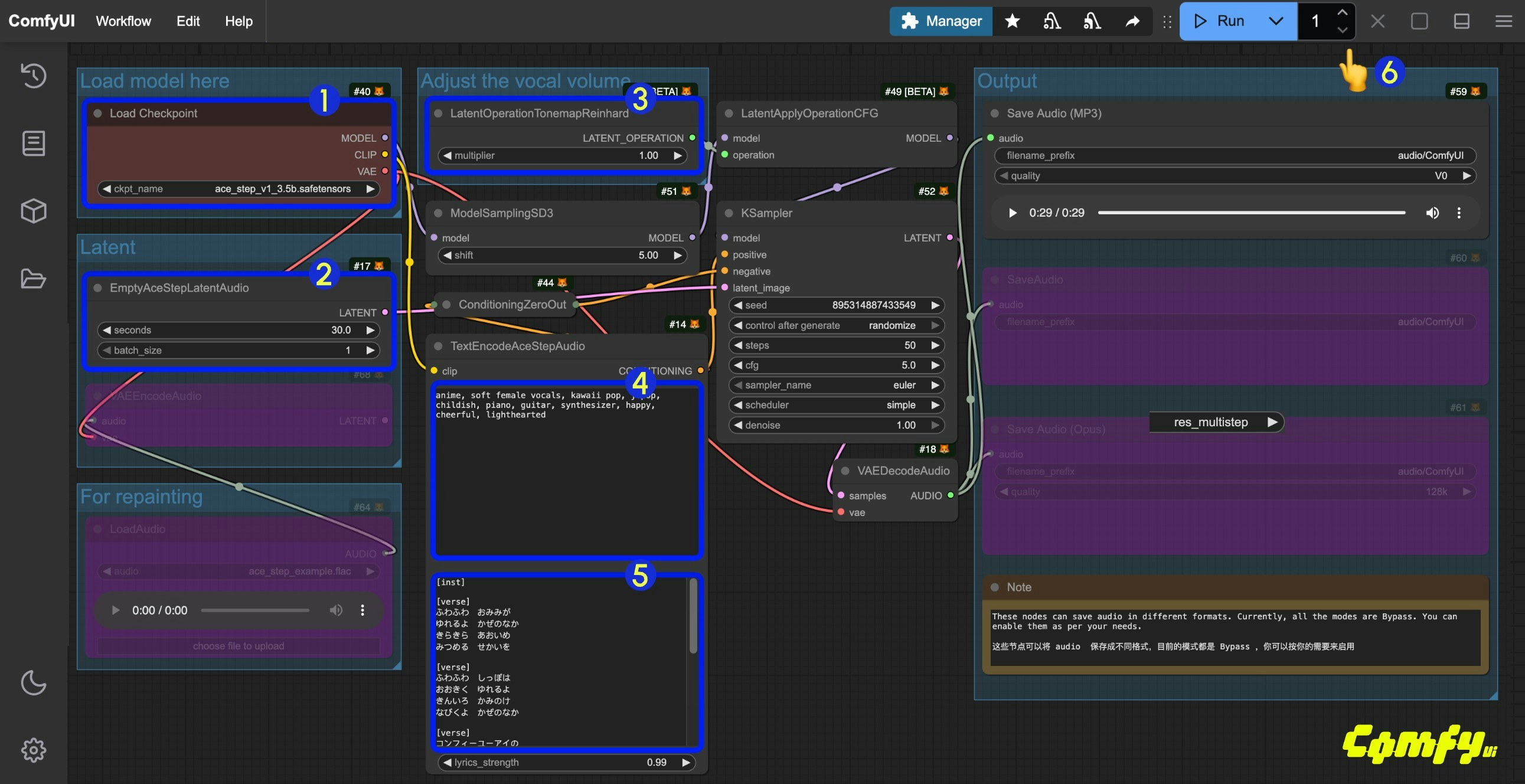
- 确保
Load Checkpoints节点加载了ace_step_v1_3.5b.safetensors模型 - (可选)在
EmptyAceStepLatentAudio节点上你可以设置生成音乐的时长 - (可选)在
LatentOperationTonemapReinhard节点,你可以调整multiplier来调整人声的音量大小(数字越大,人声音量越明显) - (可选)在
TextEncodeAceStepAudio的tags输入对应的音乐风格等等 - (可选)在
TextEncodeAceStepAudio的lyrics中输入对应的歌词,如果你不知道该输入哪些歌词 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行音频的生成。 - 工作流完成后,你可在
Save Audio节点中查看生成的音频,你可以点击播放试听,对应的音频也会被保存至ComfyUI/output/audio(由Save Audio节点决定子目录名称)。
ACE-Step ComfyUI 音频到音频工作流
你可以像图生图工作流一样,输入一段音乐,使用下面的工作流来达到重新对音乐采样生成,同样,你也可以通过控制Ksampler 的 denoise 来调整和原始音频的区别程度。
通过这样的流程,可以实现对音乐的重新编辑,来达到你想要的效果。
1. 工作流文件下载
点击下面的按钮下载对应的工作流文件,拖入 ComfyUI 中即可加载对应的工作流信息下载 Json 格式工作流文件
下载下面的音频作为输入音频下载示例音频文件用于输入
2. 按步骤完成工作流的运行
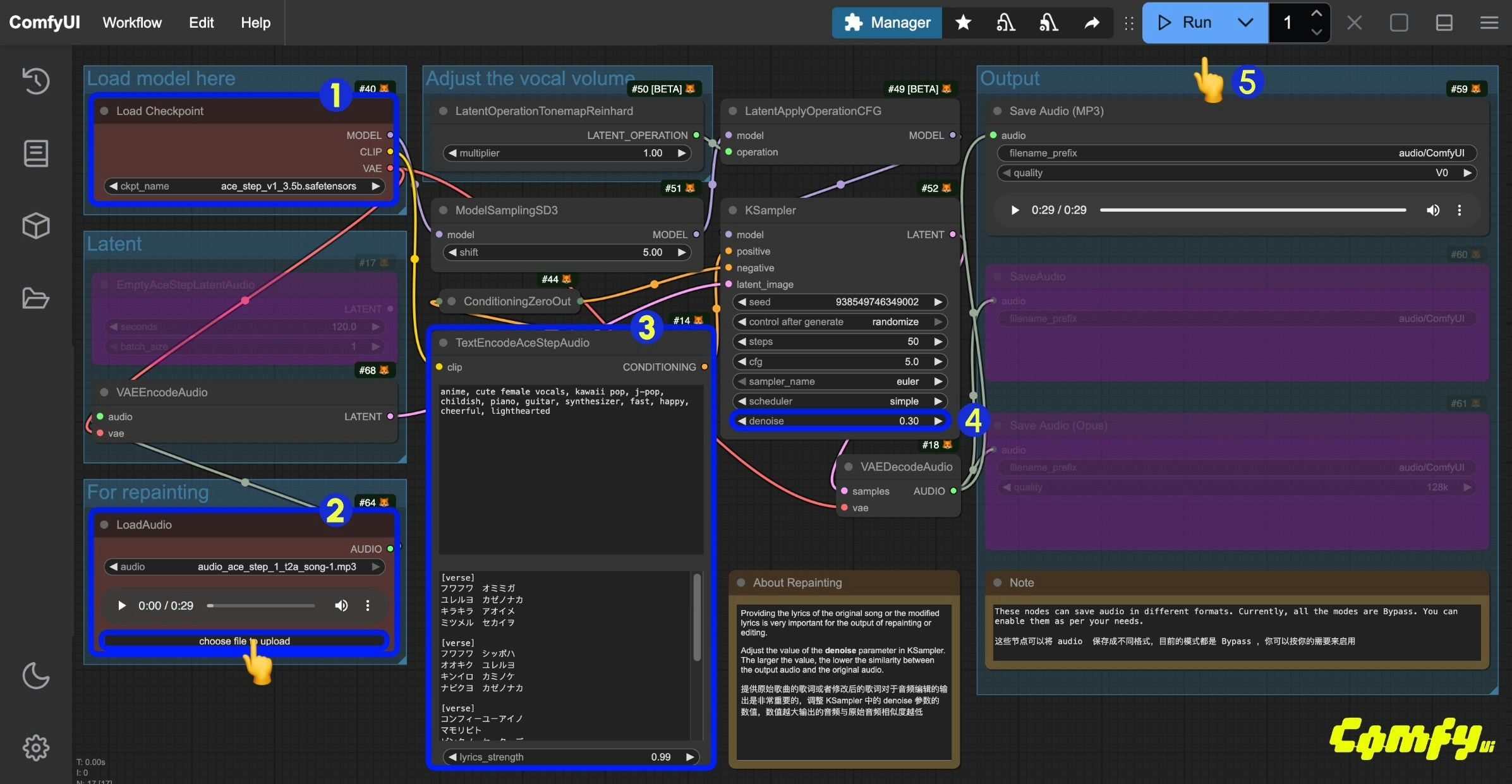
- 确保
Load Checkpoints节点加载了ace_step_v1_3.5b.safetensors模型 - 在
LoadAudio节点中上传提供的音频文件 - (可选)在
TextEncodeAceStepAudio的tags和lyrics中输入对应的音乐风格歌词等,提供歌词对于音频编辑来说非常重要 - (可选)修改
Ksampler节点的denoise参数,来调整采样过程中添加的噪声来调整与原始音频的相似程度,(越小与原始音频越相似,如果设置为1.00则可以近似认为没有音频输入) - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行音频的生成。 - 工作流完成后,你可在
Save Audio节点中查看生成的音频,你可以点击播放试听,对应的音频也会被保存至ComfyUI/output/audio(由Save Audio节点决定子目录名称)。
3. 工作流补充说明
- 在
TextEncodeAceStepAudio的tags中示例工作流中,将原本男声的tags修改为female voice来生成女声的音频 - 在
TextEncodeAceStepAudio的lyrics中示例工作流中,中对原本的歌词进行了调整修改,具体编辑你可以参考 ACE-Step 项目页面中的示例来了解如何完成修改
ACE-Step 提示词指南
ACE 的提示词目前使用的有两个,一个是tags 一个是 lyrics。
tags: 主要用来描述音乐的风格、场景等, 和我们平常其它生成的 prompt 类似,主要描述音频整体的风格和要求,使用英文逗号分隔lyrics: 主要用来描述歌词,支持歌词结构标签,如 [verse](主歌)、[chorus](副歌)和 [bridge](过渡段)来区分歌词的不同部分,也可以在纯音乐情况下输入乐器名称
tags 和 lyrics 在 ACE-Step 模型主页 中可以找到丰富的示例,你可以参考对应示例来尝试对应的提示词,本文档的提示词指南基于项目做了一些整理,以便让你能够快速尝试组合,来达到最想要的效果
tags标签(prompt)
主流音乐风格
使用简短标签组合,来生成特定风格的音乐- electronic(电子音乐)
- rock(摇滚)
- pop(流行)
- funk(放克)
- soul(灵魂乐)
- cyberpunk(赛博朋克)
- Acid jazz(酸爵士)
- electro(电子)
- em(电子音乐)
- soft electric drums(软电鼓)
- melodic(旋律)
场景类型
结合具体使用场景和氛围,生成符合对应氛围的音乐- background music for parties(派对背景音乐)
- radio broadcasts(电台广播音乐)
- workout playlists(健身播放列表音乐)
乐器元素
- saxophone,
- azz(萨克斯风、爵士)
- piano, violin(钢琴、小提琴)
人声类型
- female voice(女声)
- male voice(男声)
- clean vocals(纯净人声)
专业用语
使用音乐中常用的一些专业的用词,来精准控制音乐效果- 110 bpm(每分钟节拍数为110)
- fast tempo(快节奏)
- slow tempo(慢节奏)
- loops(循环片段)
- fills(填充音)
- acoustic guitar(木吉他)
- electric bass(电贝斯)
歌词(lyrics)
歌词结构标签
- [intro] (前奏)
- [verse] (主歌)
- [pre-chorus] (导歌)
- [chorus] (副歌/合唱)
- [bridge] (过渡段/桥段)
- [outro] (尾声)
- [hook] (钩子/主题旋律)
- [refrain] (重复段落)
- [interlude] (间奏)
- [breakdown] (分解段)
- [ad-lib] (即兴段落)
多语言支持
- ACE-Step V1 是支持多语言的,实际使用的时候 ACE-Step 会获取到对应的不同语言转换后的英文字母,然后进行音乐生成。
- 在 ComfyUI 中我们并没有完全实现全部多语言到英文字母的转换,目前仅实现了日语平假名和片假名字符
所以如果你需要使用多语言来进行相关的音乐生成,你需要首先将对应的语言转换成英文字母,然后在对应
lyrics开头输入对应语言代码的缩写,比如中文[zh]韩语[ko]等
- English
- Chinese: [zh]
- Russian: [ru]
- Spanish: [es]
- Japanese: [ja]
- German: [de]
- French: [fr]
- Portuguese: [pt]
- Italian: [it]
- Korean: [ko]
上面的语言标签在撰写文档时并没有经过完全测试,如果对应语言标签不正确,请提交 issue 到我们的文档的仓库 我们会进行及时修改