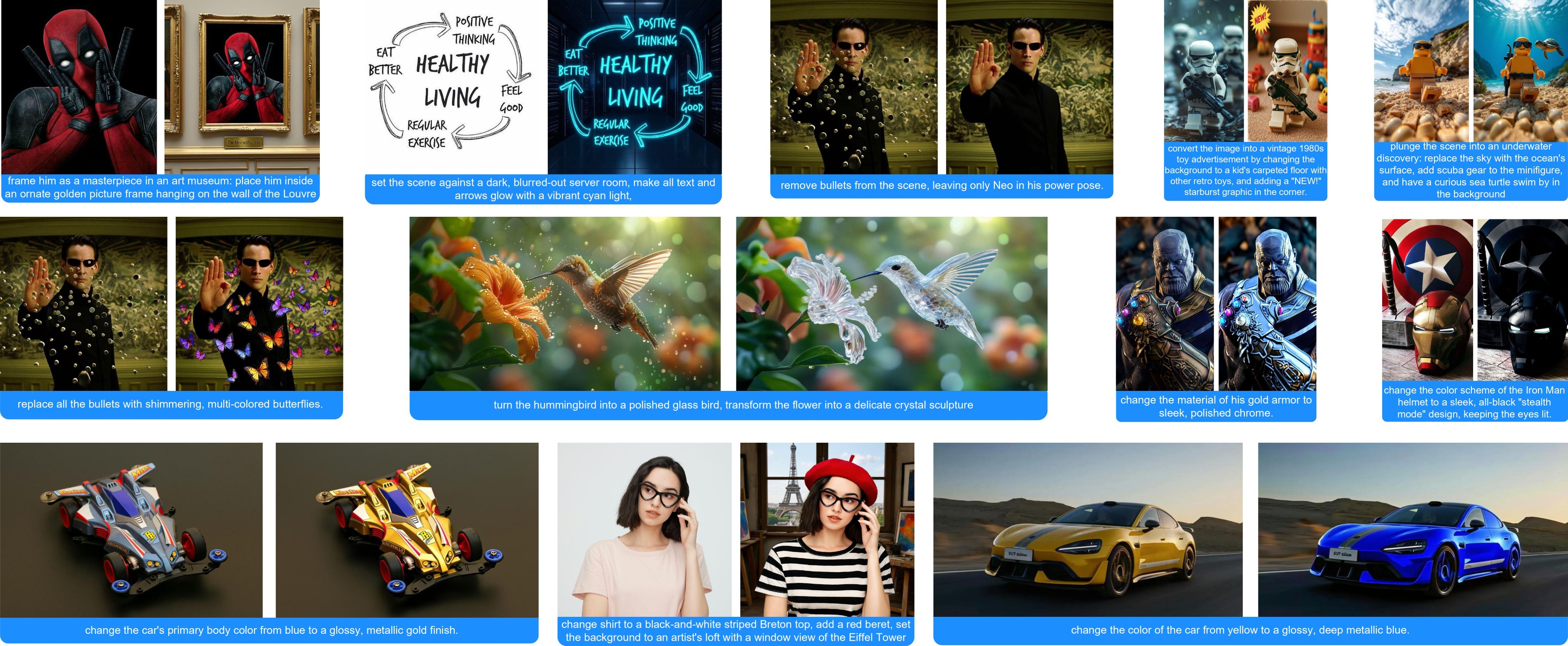
 HiDream-E1 是智象未来(HiDream-ai) 正式开源的交互式图像编辑大模型,是基于 HiDream-I1 构建的图像编辑模型。
可以使用自然语言来实现对图像的编辑,该模型基于 MIT 许可证 发布,支持用于个人项目、科学研究以及商用。
通过与此前发布的 hidream-i1的共同组合,实现了 从图像生成到编辑的 创作能力。
HiDream-E1 是智象未来(HiDream-ai) 正式开源的交互式图像编辑大模型,是基于 HiDream-I1 构建的图像编辑模型。
可以使用自然语言来实现对图像的编辑,该模型基于 MIT 许可证 发布,支持用于个人项目、科学研究以及商用。
通过与此前发布的 hidream-i1的共同组合,实现了 从图像生成到编辑的 创作能力。
| 名称 | 更新时间 | 推理步数 | 分辨率 | HuggingFace 仓库 |
|---|---|---|---|---|
| HiDream-E1-Full | 2025-4-28 | 28 | 768x768 | 🤗 HiDream-E1-Full |
| HiDream-E1.1 | 2025-7-16 | 28 | 动态(1百万像素) | 🤗 HiDream-E1.1 |
HiDream E1 及 E1.1 工作流相关模型
本篇指南涉及的所有模型你都可以在这里找到, E1, E1.1 除了 Diffusion model 之外都是用相同的模型 我们在对应的工作流文件中也以包含了对应的模型信息,你可以选择手动下载模型保存,或者在加载工作流后按工作流提示进行下载,推荐使用 E1.1 这个模型的运行对显存占用要求极高,具体显存占用请参考对应部分的说明 Diffusion Model 你不用同时下载这两个模型,由于 E1.1 是基于 E1 的迭代版本,在实际测试中它的质量和效果较 E1 都有较大提升 Text Encoder:- clip_l_hidream.safetensors 236.12MB
- clip_g_hidream.safetensors 1.29GB
- t5xxl_fp8_e4m3fn_scaled.safetensors 4.8GB
- llama_3.1_8b_instruct_fp8_scaled.safetensors 8.46GB
- ae.safetensors 319.77MB
这个是 Flux 的 VAE 模型,如果你之前使用过 Flux 的工作流,你可能已经下载了这个文件。文件保存位置
HiDream E1.1 ComfyUI 原生工作流示例
E1.1 是于 2025年7月16日更新迭代的版本, 这个版本支持动态一百万分辨率,在工作流中使用了Scale Image to Total Pixels 节点来将输入图片动态调整为 1百万像素
1. HiDream E1.1 工作流及相关素材
下载下面的图片并拖入 ComfyUI 已加载对应工作流及模型 下载下面的图片作为输入
下载下面的图片作为输入

2. 按步骤完成 HiDream-e1 工作流运行
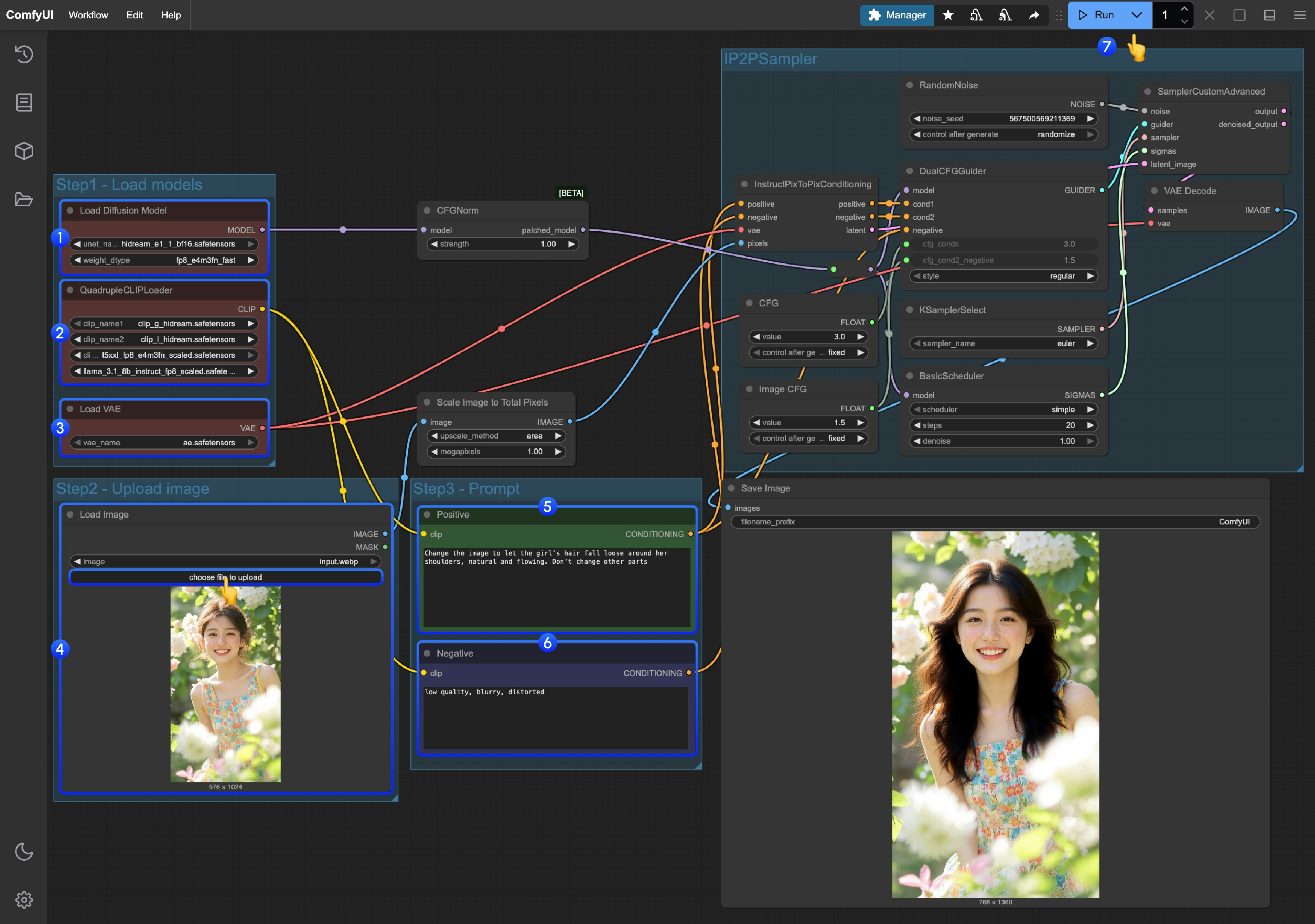
- 确保
Load Diffusion Model节点加载了hidream_e1_1_bf16.safetensors模型 - 确保
QuadrupleCLIPLoader中四个对应的 text encoder 被正确加载- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensors
- 确保
Load VAE节点中使用的是ae.safetensors文件 - 在
Load Image节点中加载提供的输入或你需要的图片 - 在
Empty Text Encoder(Positive)节点中输入 想要对图片进行的修改 - 在
Empty Text Encoder(Negative)节点中输入 不想要在画面中出现的内容 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行图片生成
3. 工作流补充说明
- 由于 HiDream E1.1 支持的是动态总像素为一百万像素输入,所以工作流使用了
Scale Image to Total Pixels来将所有输入图片进行处理转化,这可能会导致比例尺寸相对于输入图片会有所变化 - 使用 fp16 版本的模型,在实际测试过程中,在 A100 40GB 和 4090D 24GB 时使用完整版本时会 Out of memory,所以工作流默认设置了使用
fp8_e4m3fn_fast来进行推理
HiDream E1 ComfyUI 原生 工作流示例
Run on Comfy Cloud
E1 是于 2025 年 4 月 28 日发布的,这个模型只支持 768*768 的分辨率1. HiDream-e1 工作流及相关素材
1.1 下载工作流文件
请下载下面的图片并拖入 ComfyUI 中,工作流已包含模型下载信息,加载后将会提示你进行对应的模型下载。
1.2 下载输入图片
请下载下面的图片,我们将用于输入
2. 按步骤完成 HiDream-e1 工作流运行
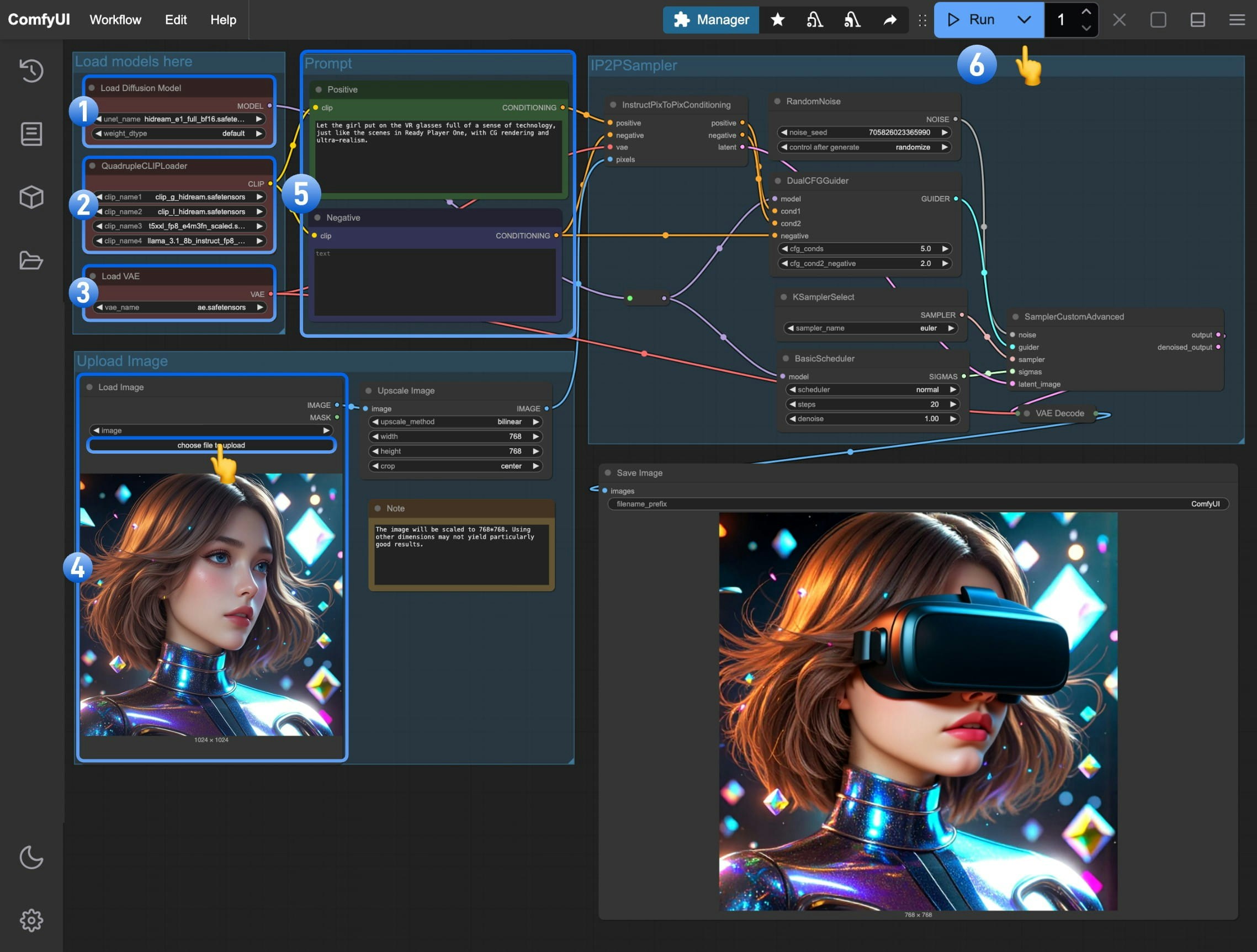
- 确保
Load Diffusion Model节点加载了hidream_e1_full_bf16.safetensors模型 - 确保
QuadrupleCLIPLoader中四个对应的 text encoder 被正确加载- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensors
- 确保
Load VAE节点中使用的是ae.safetensors文件 - 在
Load Image节点中加载我们之前下载的输入图片 - (重要)在
Empty Text Encoder(Positive)节点中输入 想要修改的画面的提示词 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行图片生成
ComfyUI HiDream-e1 工作流补充说明
- 可能需要修改多次提示词或者进行多次的生成才能得到较好的结果
- 这个模型在改变图片风格上比较难保持一致性,需要尽可能完善提示词
- 由于模型支持的是 768*768 的分辨率,在实际测试中调整过其它尺寸,在其它尺寸下图像表现能力不佳,甚至差异较大