- 精准文字编辑: Qwen-Image-Edit支持中英双语文字编辑,可以在保留文字大小/字体/风格的前提下,直接编辑图片中文字,进行增删改。
- 语义/外观 双重编辑: Qwen-Image-Edit不仅支持low-level的视觉外观编辑(例如风格迁移,增删改等),也支持high-level的视觉语义编辑(例如IP制作,物体旋转等)
- 强大的跨基准性能表现: 在多个公开基准测试中的评估表明,Qwen-Image-Edit 在编辑任务中均获得SOTA,是一个强大的图像生成基础模型。
ComfyOrg Qwen-Image-Edit 直播回放
Qwen-Image-Edit ComfyUI 原生工作流示例
1. 工作流文件
更新 ComfyUI 后你可以从模板中找到工作流文件,或者将下面的工作流拖入 ComfyUI 中加载
下载 JSON 格式工作流
在 ComfyUI Cloud 上运行
下载下面的图片作为输入
2. 模型下载
所有模型都可在 Comfy-Org/Qwen-Image_ComfyUI 或 Comfy-Org/Qwen-Image-Edit_ComfyUI 找到 Diffusion model LoRA Text encoder VAE Model Storage Location3. 按步骤完成工作流
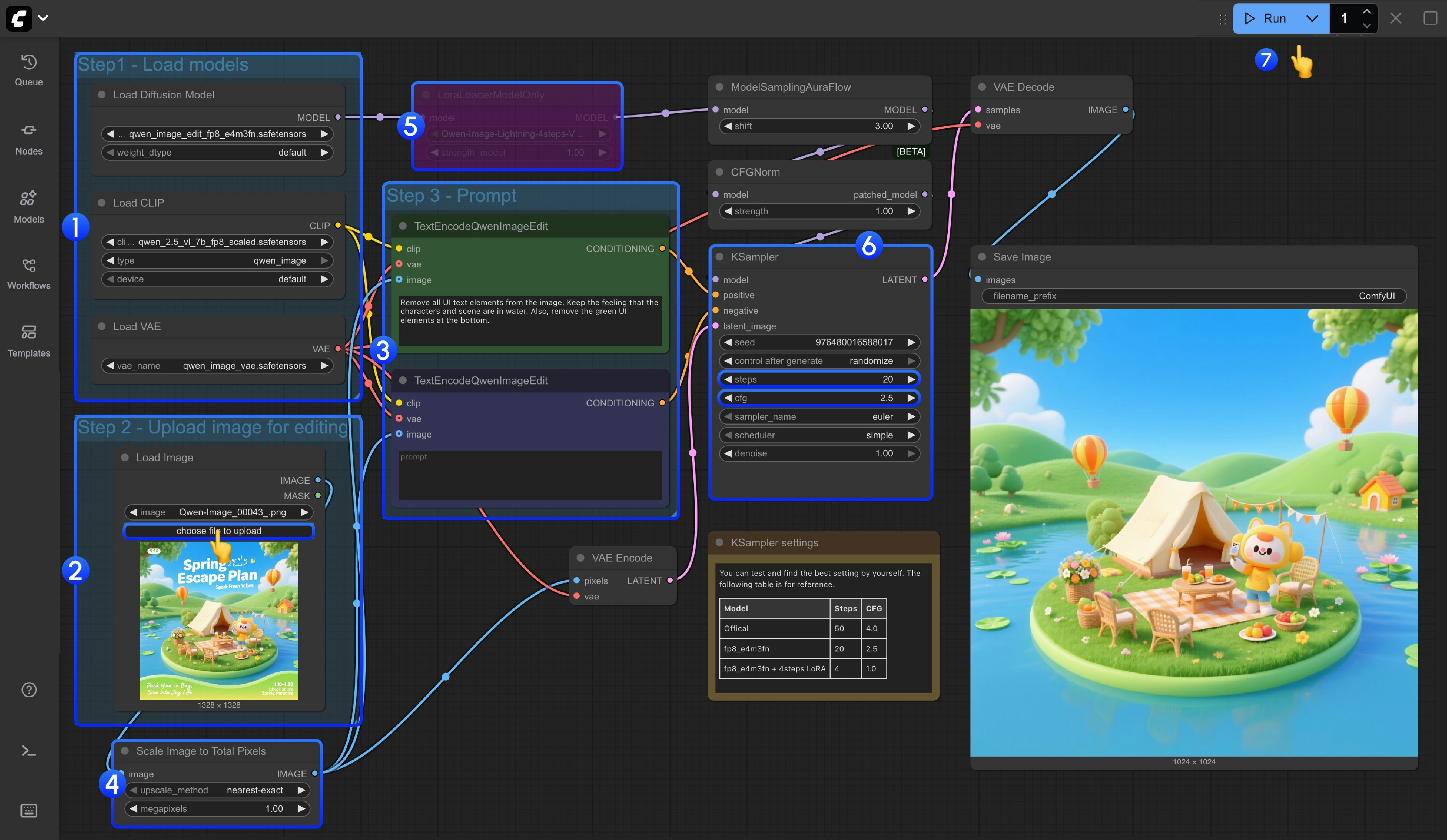
- 模型加载
- 确保
Load Diffusion Model节点加载了qwen_image_edit_fp8_e4m3fn.safetensors - 确保
Load CLIP节点中加载了qwen_2.5_vl_7b_fp8_scaled.safetensors - 确保
Load VAE节点中加载了qwen_image_vae.safetensors
- 确保
- 图片加载
- 确保
Load Image节点中上传了用于编辑的图片
- 确保
- 提示词设置
- 在
CLIP Text Encoder节点中设置好提示词
- 在
- Scale Image to Total Pixels 节点会将你输入图片缩放到总像素为 一百万像素,
- 主要是避免输入图片尺寸过大如 2048x2048 导致的输出图像质量损失问题
- 如果你很了解你输入的图片尺寸,你可以使用
Ctrl+B绕过这个节点
- 如果你要使用 4 步 Lighting LoRA 来实现图片生成的提速,你可以选中
LoraLoaderModelOnly节点,然后按Ctrl+B启用该节点 - 对于 Ksampler 节点的
steps和cfg设置,我们在节点下方增加了一个笔记,你可以测试一下最佳的参数设置 - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流