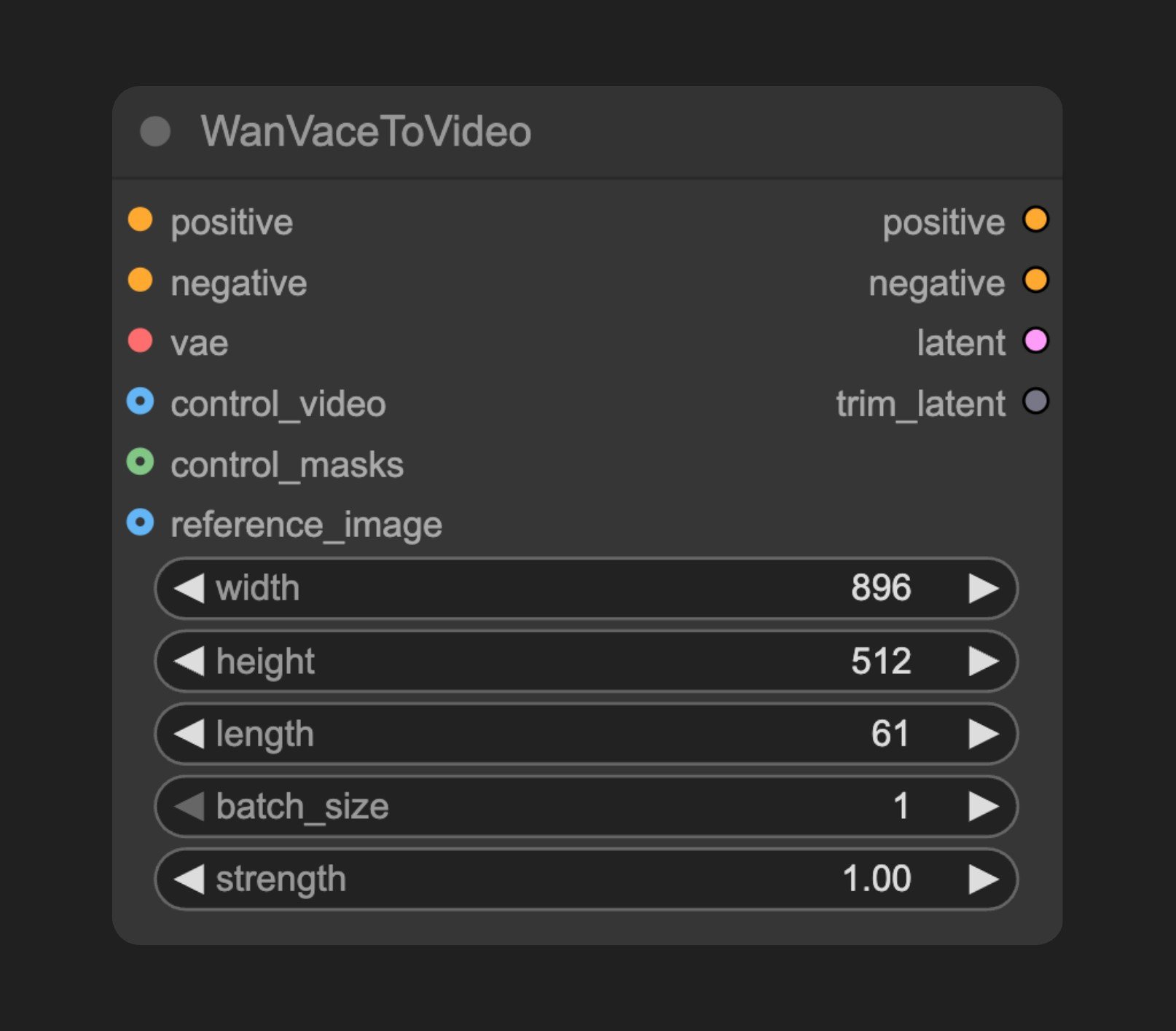
Parameter Description
Required Parameters
| Parameter | Type | Default | Range | Description |
|---|---|---|---|---|
| positive | CONDITIONING | - | - | Positive prompt condition |
| negative | CONDITIONING | - | - | Negative prompt condition |
| vae | VAE | - | - | VAE model for encoding/decoding |
| width | INT | 832 | 16-MAX_RESOLUTION | Video width, step size 16 |
| height | INT | 480 | 16-MAX_RESOLUTION | Video height, step size 16 |
| length | INT | 81 | 1-MAX_RESOLUTION | Number of video frames, step size 4 |
| batch_size | INT | 1 | 1-4096 | Batch size |
| strength | FLOAT | 1.0 | 0.0-1000.0 | Condition strength for VACE control, step size 0.01. This is not a LoRA strength. LoRA weights are applied through separate LoRA nodes. |
Optional Parameters
| Parameter | Type | Description |
|---|---|---|
| control_video | IMAGE | Control video for guiding the generation process |
| control_masks | MASK | Control masks defining which areas should be controlled |
| reference_image | IMAGE | Reference image as starting point or reference (single image) |
Output Parameters
| Parameter | Type | Description |
|---|---|---|
| positive | CONDITIONING | Processed positive prompt condition |
| negative | CONDITIONING | Processed negative prompt condition |
| latent | LATENT | Generated video latent representation |
| trim_latent | INT | Parameter for trimming latent representation, default value is 0. When a reference image is provided, this value is set to the shape size of the reference image in latent space. It indicates how much content from the reference image downstream nodes should trim from the generated latent representation to ensure proper control of the reference image’s influence in the final video output. |
Source Code
[Source code update time: 2025-05-15]class WanVaceToVideo:
@classmethod
def INPUT_TYPES(s):
return {"required": {"positive": ("CONDITIONING", ),
"negative": ("CONDITIONING", ),
"vae": ("VAE", ),
"width": ("INT", {"default": 832, "min": 16, "max": nodes.MAX_RESOLUTION, "step": 16}),
"height": ("INT", {"default": 480, "min": 16, "max": nodes.MAX_RESOLUTION, "step": 16}),
"length": ("INT", {"default": 81, "min": 1, "max": nodes.MAX_RESOLUTION, "step": 4}),
"batch_size": ("INT", {"default": 1, "min": 1, "max": 4096}),
"strength": ("FLOAT", {"default": 1.0, "min": 0.0, "max": 1000.0, "step": 0.01}),
},
"optional": {"control_video": ("IMAGE", ),
"control_masks": ("MASK", ),
"reference_image": ("IMAGE", ),
}}
RETURN_TYPES = ("CONDITIONING", "CONDITIONING", "LATENT", "INT")
RETURN_NAMES = ("positive", "negative", "latent", "trim_latent")
FUNCTION = "encode"
CATEGORY = "conditioning/video_models"
EXPERIMENTAL = True
def encode(self, positive, negative, vae, width, height, length, batch_size, strength, control_video=None, control_masks=None, reference_image=None):
latent_length = ((length - 1) // 4) + 1
if control_video is not None:
control_video = comfy.utils.common_upscale(control_video[:length].movedim(-1, 1), width, height, "bilinear", "center").movedim(1, -1)
if control_video.shape[0] < length:
control_video = torch.nn.functional.pad(control_video, (0, 0, 0, 0, 0, 0, 0, length - control_video.shape[0]), value=0.5)
else:
control_video = torch.ones((length, height, width, 3)) * 0.5
if reference_image is not None:
reference_image = comfy.utils.common_upscale(reference_image[:1].movedim(-1, 1), width, height, "bilinear", "center").movedim(1, -1)
reference_image = vae.encode(reference_image[:, :, :, :3])
reference_image = torch.cat([reference_image, comfy.latent_formats.Wan21().process_out(torch.zeros_like(reference_image))], dim=1)
if control_masks is None:
mask = torch.ones((length, height, width, 1))
else:
mask = control_masks
if mask.ndim == 3:
mask = mask.unsqueeze(1)
mask = comfy.utils.common_upscale(mask[:length], width, height, "bilinear", "center").movedim(1, -1)
if mask.shape[0] < length:
mask = torch.nn.functional.pad(mask, (0, 0, 0, 0, 0, 0, 0, length - mask.shape[0]), value=1.0)
control_video = control_video - 0.5
inactive = (control_video * (1 - mask)) + 0.5
reactive = (control_video * mask) + 0.5
inactive = vae.encode(inactive[:, :, :, :3])
reactive = vae.encode(reactive[:, :, :, :3])
control_video_latent = torch.cat((inactive, reactive), dim=1)
if reference_image is not None:
control_video_latent = torch.cat((reference_image, control_video_latent), dim=2)
vae_stride = 8
height_mask = height // vae_stride
width_mask = width // vae_stride
mask = mask.view(length, height_mask, vae_stride, width_mask, vae_stride)
mask = mask.permute(2, 4, 0, 1, 3)
mask = mask.reshape(vae_stride * vae_stride, length, height_mask, width_mask)
mask = torch.nn.functional.interpolate(mask.unsqueeze(0), size=(latent_length, height_mask, width_mask), mode='nearest-exact').squeeze(0)
trim_latent = 0
if reference_image is not None:
mask_pad = torch.zeros_like(mask[:, :reference_image.shape[2], :, :])
mask = torch.cat((mask_pad, mask), dim=1)
latent_length += reference_image.shape[2]
trim_latent = reference_image.shape[2]
mask = mask.unsqueeze(0)
positive = node_helpers.conditioning_set_values(positive, {"vace_frames": control_video_latent, "vace_mask": mask, "vace_strength": strength})
negative = node_helpers.conditioning_set_values(negative, {"vace_frames": control_video_latent, "vace_mask": mask, "vace_strength": strength})
latent = torch.zeros([batch_size, 16, latent_length, height // 8, width // 8], device=comfy.model_management.intermediate_device())
out_latent = {}
out_latent["samples"] = latent
return (positive, negative, out_latent, trim_latent)