- 核心架构: 采用类似Sora的DiT(Diffusion Transformer)架构,有效融合了文本、图像和动作信息,提高了生成视频帧之间的一致性、质量和对齐度,通过统一的全注意力机制实现多视角镜头切换,确保主体一致性。
- 3D VAE: 定义的 3D VAE 将视频压缩到紧凑的潜空间,同时压缩视频,使得图生视频的生成更加高效。
- 卓越的图像-视频-文本对齐: 使用 MLLM 文本编码器,在图像和视频生成中表现出色,能够更好地遵循文本指令,捕捉细节,并进行复杂推理。
工作流共用模型
在文生视频和图生视频的工作流中下面的这些模型是共有的,请完成下载并保存到指定目录中 保存位置:混元文生视频工作流
混元文生视频开源于 2024 年 12 月,支持通过自然语言描述生成 5 秒的短视频,支持中英文输入。1. 文生视频相关工作流
请保存下面的图片,并拖入 ComfyUI 以加载工作流
2. 混元文生图模型
请下载 hunyuan_video_t2v_720p_bf16.safetensors 并保存至ComfyUI/models/diffusion_models 文件夹中
确保包括共用模型文件夹有以下完整的模型文件:
3. 按步骤完成工作流的运行
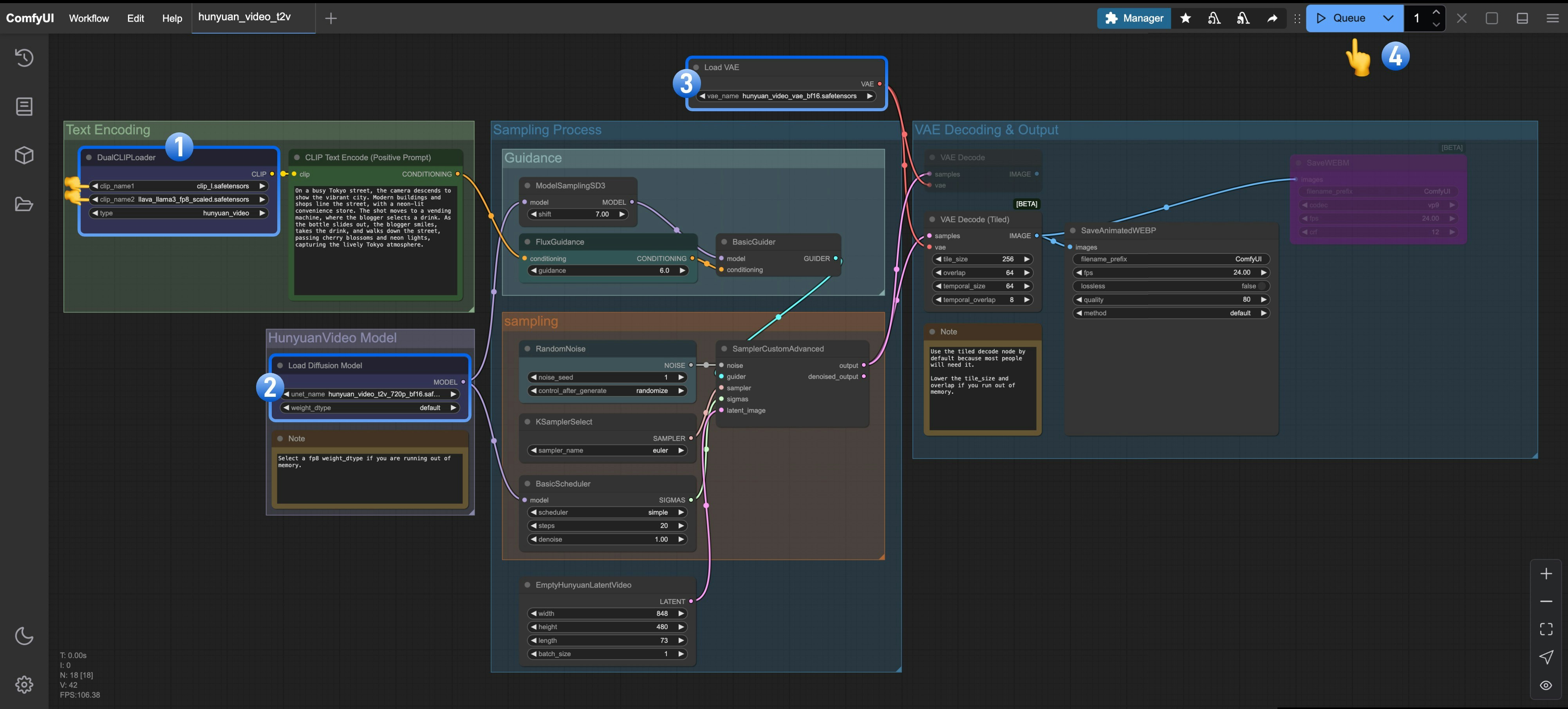
- 确保在
DualCLIPLoader中下面的模型已加载:- clip_name1: clip_l.safetensors
- clip_name2: llava_llama3_fp8_scaled.safetensors
- 确保在
Load Diffusion Model加载了hunyuan_video_t2v_720p_bf16.safetensors - 确保在
Load VAE中加载了hunyuan_video_vae_bf16.safetensors - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
混元图生视频工作流
混元图生视频模型开源于2025年3月6日,基于 HunyuanVideo 框架,支持将静态图像转化为流畅的高质量视频,同时开放了 LoRA 训练代码,支持定制特殊视频效果如:头发生长、物体变形等等。 目前混元图生视频模型分为两个版本:- v1 “concat” : 视频的运动流畅性较好,但比较少遵循图像引导
- v2 “replace”: 在v1 更新后的次日更新的版本,图像的引导性较好,但相对于 V1 版本似乎不那么有活力
v1 “concat”

v2 “replace”

v1 及 v2 版本共用的模型
请下载下面的文件,并保存到ComfyUI/models/clip_vision 目录中
v1 “concat” 图生视频工作流
1. 工作流及相关素材
请下载下面的工作流图片,并拖入 ComfyUI 以加载工作流 请下载下面的图片,我们将使用它作为图生视频的起始帧
请下载下面的图片,我们将使用它作为图生视频的起始帧

2. v1 版本模型
确保包括共用模型文件夹有以下完整的模型文件:3. 按步骤完成工作流
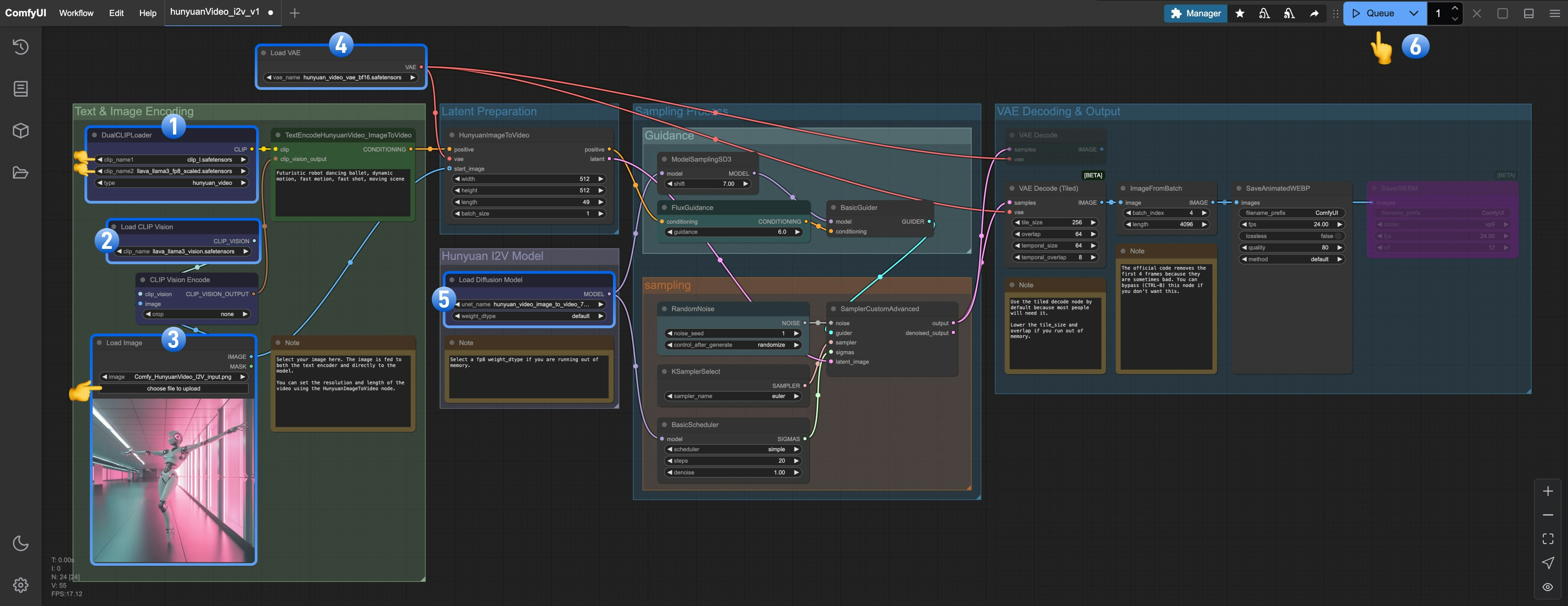
- 确保
DualCLIPLoader中下面的模型已加载:- clip_name1: clip_l.safetensors
- clip_name2: llava_llama3_fp8_scaled.safetensors
- 确保
Load CLIP Vision加载了llava_llama3_vision.safetensors - 请在
Load Image Model加载了hunyuan_video_image_to_video_720p_bf16.safetensors - 确保
Load VAE中加载了hunyuan_video_vae_bf16.safetensors - 确保
Load Diffusion Model中加载了hunyuan_video_image_to_video_720p_bf16.safetensors - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
v2 “replace” 图生视频工作流
v2 版本的工作流与 v1 版本的工作流基本相同,你只需要下载一个 replace 的模型,然后在Load Diffusion Model 中使用即可。
1. 工作流及相关素材
请下载下面的工作流图片,并拖入 ComfyUI 以加载工作流 请下载下面的图片,我们将使用它作为图生视频的起始帧
请下载下面的图片,我们将使用它作为图生视频的起始帧

2. v2 版本模型
确保包括共用模型文件夹有以下完整的模型文件:3. 按步骤完成工作流
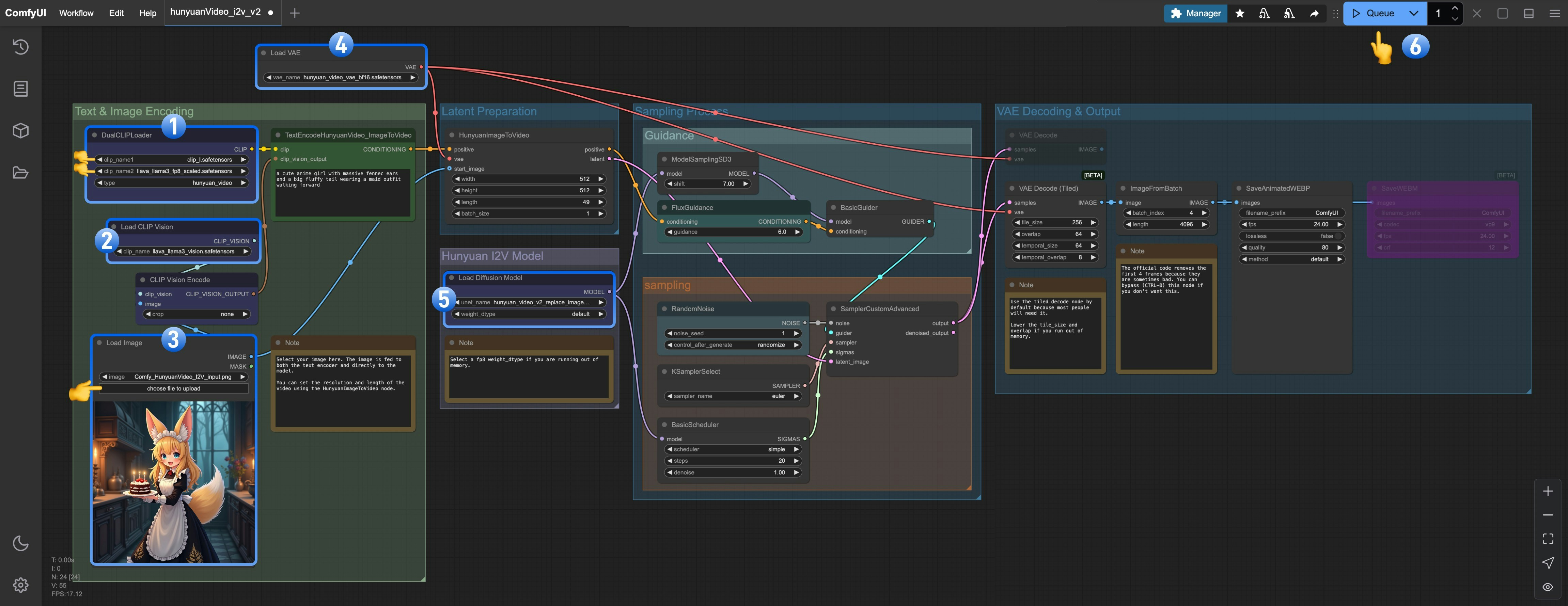
- 确保
DualCLIPLoader中下面的模型已加载:- clip_name1: clip_l.safetensors
- clip_name2: llava_llama3_fp8_scaled.safetensors
- 确保
Load CLIP Vision加载了llava_llama3_vision.safetensors - 请在
Load Image Model加载了hunyuan_video_image_to_video_720p_bf16.safetensors - 确保
Load VAE中加载了hunyuan_video_vae_bf16.safetensors - 确保
Load Diffusion Model中加载了hunyuan_video_v2_replace_image_to_video_720p_bf16.safetensors - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
开始你的尝试
下面是我们提供了一些示例图片和对应的提示词,你可以基于这些内容,进行修改,创作出属于你自己的视频。


