通义万相 2.2(Wan 2.2)是阿里云推出的新一代多模态生成模型。该模型采用创新的 MoE(Mixture of Experts)架构,由高噪专家模型和低噪专家模型组成,能够根据去噪时间步进行专家模型划分,从而生成更高质量的视频内容。
Wan 2.2 具备三大核心特性:影视级美学控制,深度融合专业电影工业的美学标准,支持光影、色彩、构图等多维度视觉控制;大规模复杂运动,轻松还原各类复杂运动并强化运动的流畅度和可控性;精准语义遵循,在复杂场景和多对象生成方面表现卓越,更好还原用户的创意意图。
模型支持文生视频、图生视频等多种生成模式,适用于内容创作、艺术创作、教育培训等多种应用场景。
Wan2.2 提示词指南
模型亮点
- 影视级美学控制:专业镜头语言,支持光影、色彩、构图等多维度视觉控制
- 大规模复杂运动:流畅还原各类复杂运动,强化运动可控性和自然度
- 精准语义遵循:复杂场景理解,多对象生成,更好还原创意意图
- 高效压缩技术:5B版本高压缩比VAE,显存优化,支持混合训练
Wan2.2 开源模型版本
Wan2.2 系列模型基于 Apache2.0 开源协议,支持商业使用。Apache2.0 许可证允许您自由使用、修改和分发这些模型,包括商业用途,只需保留原始版权声明和许可证文本。ComfyOrg Wan2.2 直播回放
对于 ComfyUI Wan2.2 的使用,我们有进行了直播,你可以查看这些回放了解如何使用
本篇教程将使用 🤗 Comfy-Org/Wan_2.2_ComfyUI_Repackaged的版本进行
Wan2.2 TI2V 5B 混合版本工作流示例
1. 工作流文件下载
请更新你的 ComfyUI 到最新版本,并通过菜单工作流 -> 浏览模板 -> 视频 找到 “Wan2.2 5B video generation” 以加载工作流
下载 JSON 格式工作流
Run on Comfy Cloud
2. 手动下载模型
Diffusion Model VAE Text Encoder3. 按步骤完成工作流
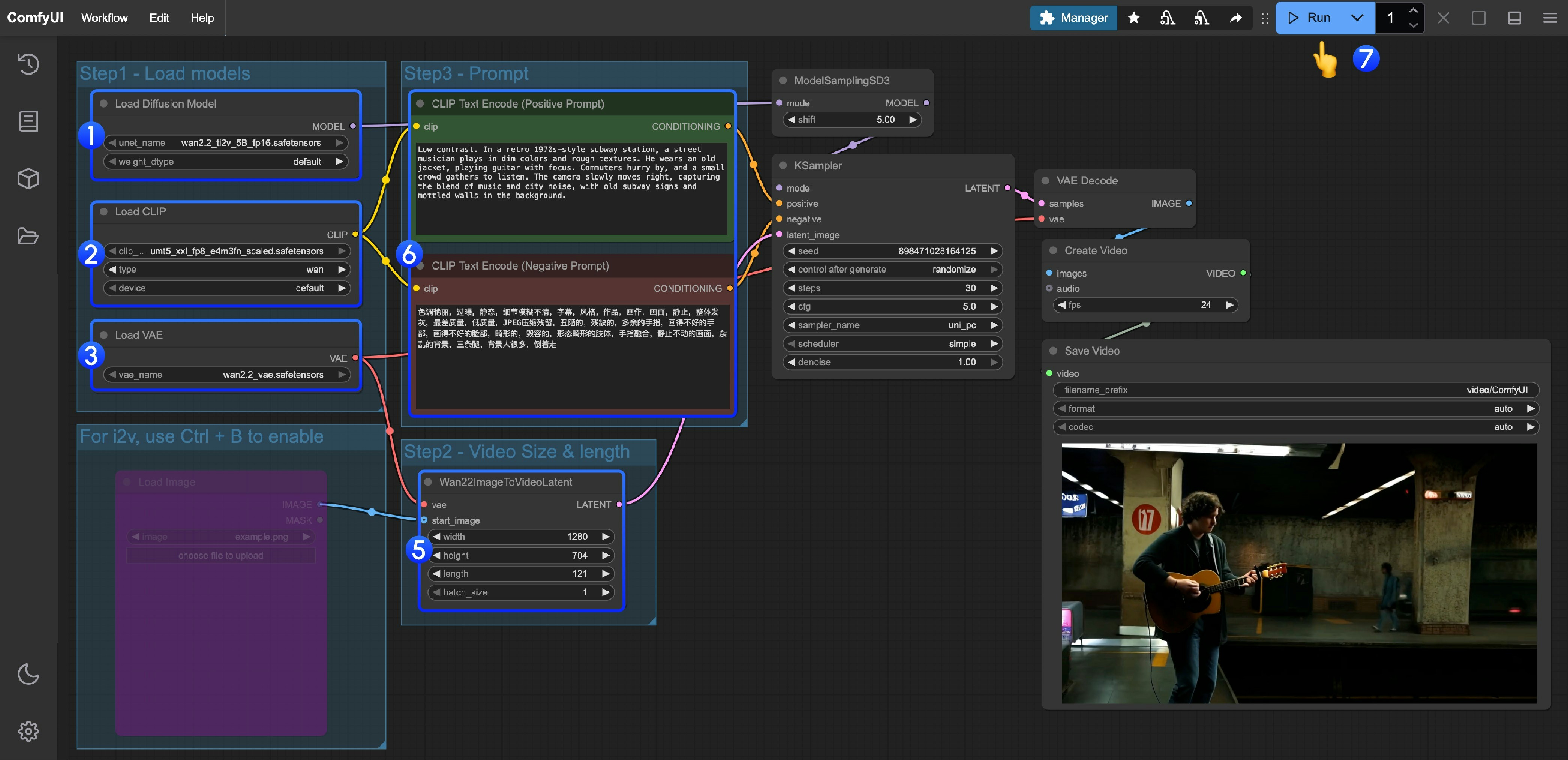
- 确保
Load Diffusion Model节点加载了wan2.2_ti2v_5B_fp16.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan2.2_vae.safetensors模型 - (可选)如果你需要进行图生视频,可以使用快捷键 Ctrl+B 来启用
Load image节点来上传图片 - (可选)在
Wan22ImageToVideoLatent你可以进行尺寸的设置调整,和视频总帧数length调整 - (可选)如果你需要修改提示词(正向及负向)请在序号
5的CLIP Text Encoder节点中进行修改 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
Wan2.2 14B T2V 文生视频工作流示例
1. 工作流文件下载
请更新你的 ComfyUI 到最新版本,并通过菜单工作流 -> 浏览模板 -> 视频 找到 “Wan2.2 14B T2V”
或者更新你的 ComfyUI 到最新版本后,下载下面的工作流并拖入 ComfyUI 以加载工作流
下载 JSON 格式工作流
Run on Comfy Cloud
2. 手动下载模型
Diffusion Model VAE Text Encoder3. 按步骤完成工作流
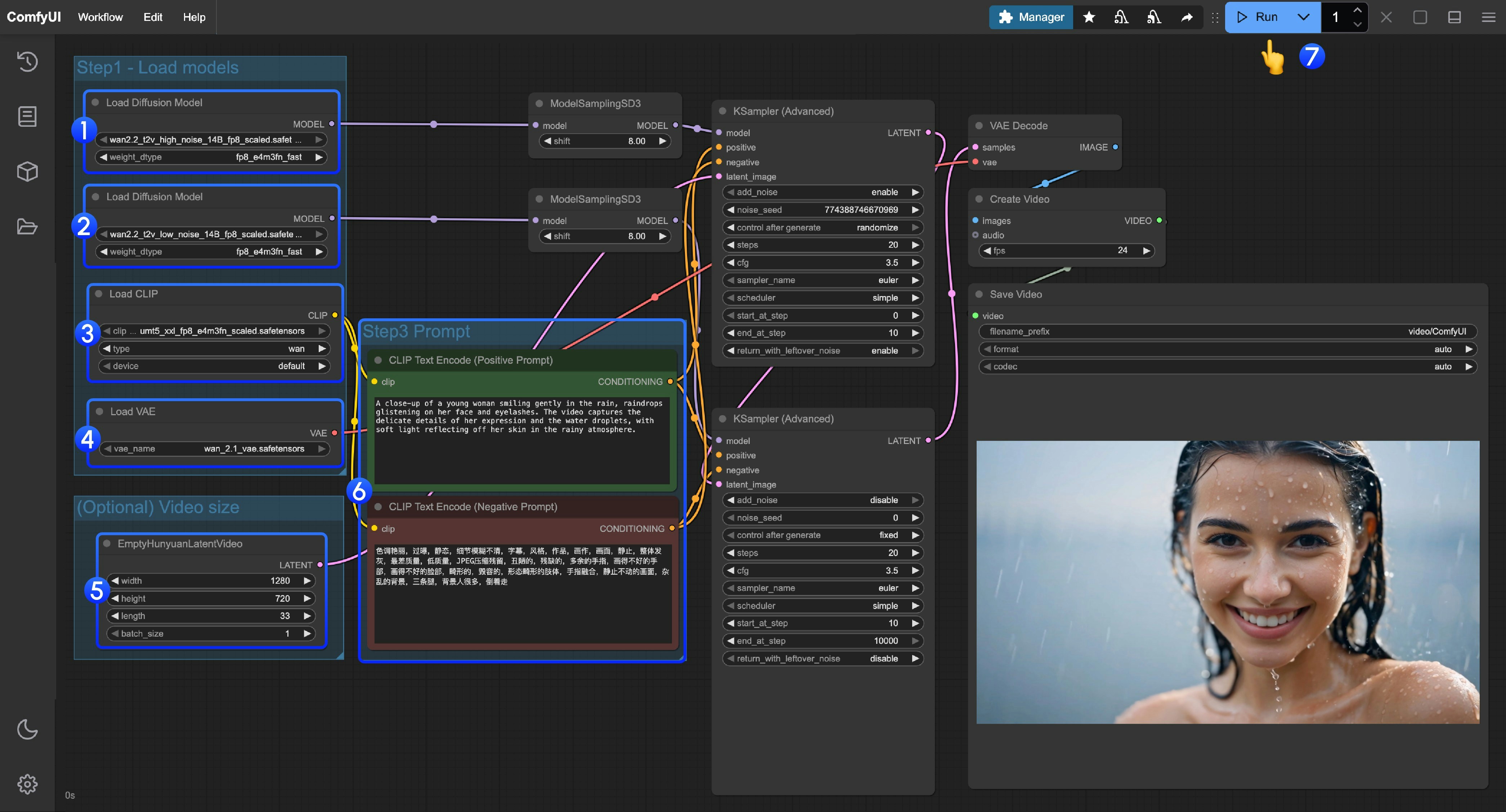
- 确保第一个
Load Diffusion Model节点加载了wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors模型 - 确保第二个
Load Diffusion Model节点加载了wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - (可选)在
EmptyHunyuanLatentVideo你可以进行尺寸的设置调整,和视频总帧数length调整 - 如果你需要修改提示词(正向及负向)请在序号
6的CLIP Text Encoder节点中进行修改 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
Wan2.2 14B I2V 图生视频工作流示例
1. 工作流文件
请更新你的 ComfyUI 到最新版本,并通过菜单工作流 -> 浏览模板 -> 视频 找到 “Wan2.2 14B I2V” 以加载工作流
或者更新你的 ComfyUI 到最新版本后,下载下面的工作流并拖入 ComfyUI 以加载工作流
下载 JSON 格式工作流
Run on Comfy Cloud
你可以使用下面的图片作为输入
2. 手动下载模型
Diffusion Model VAE Text Encoder3. 按步骤完成工作流
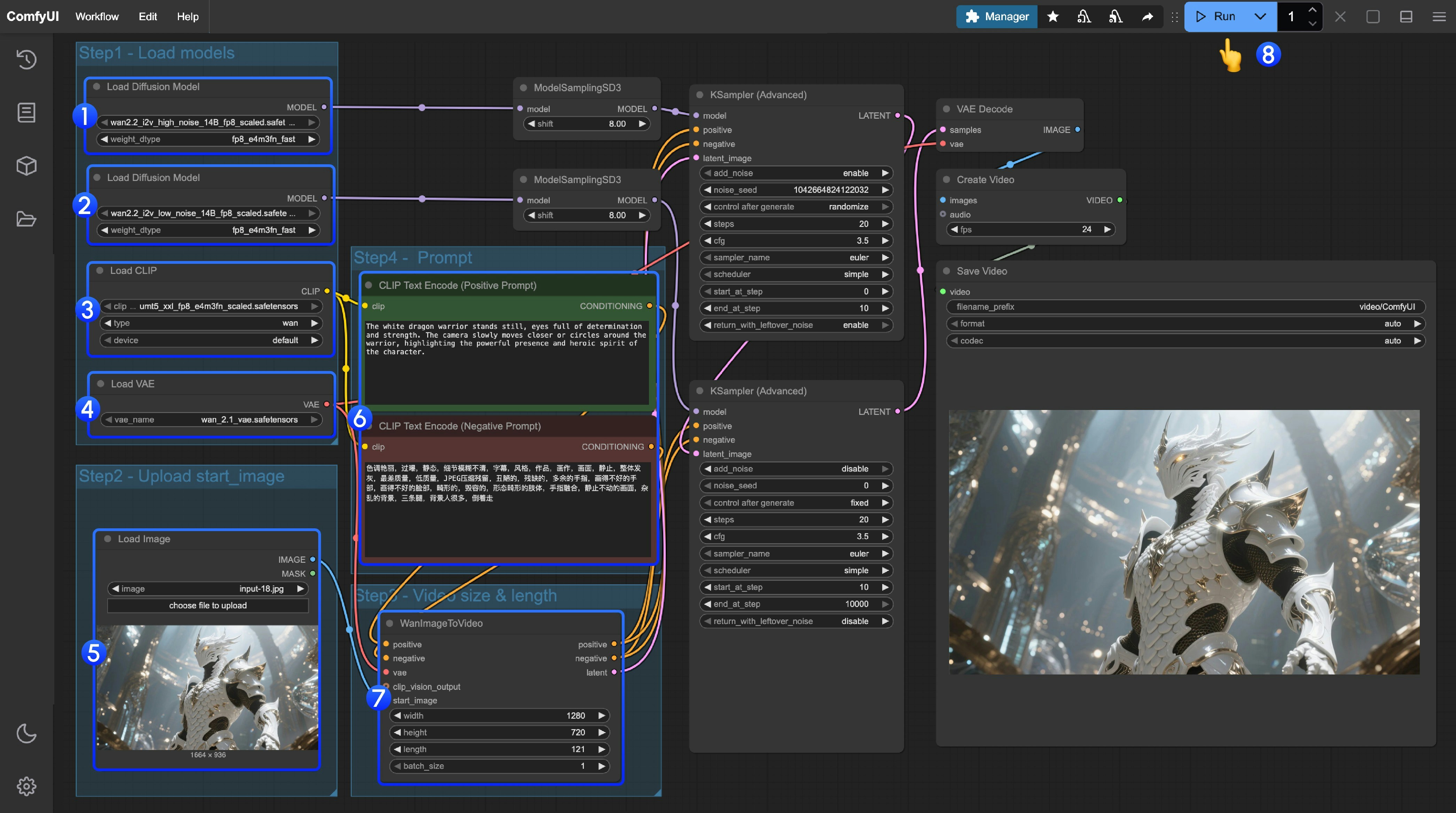
- 确保第一个
Load Diffusion Model节点加载了wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors模型 - 确保第二个
Load Diffusion Model节点加载了wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 在
Load Image节点上传作为起始帧的图像 - 如果你需要修改提示词(正向及负向)请在序号
6的CLIP Text Encoder节点中进行修改 - 可选)在
EmptyHunyuanLatentVideo你可以进行尺寸的设置调整,和视频总帧数length调整 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
Wan2.2 14B FLF2V 首尾帧视频生成工作流示例
首尾帧工作流使用模型位置与 I2V 部分完全一致1. 工作流及素材生成
下载下面的视频或者 JSON 格式工作流在 ComfyUI 中打开下载 JSON 格式工作流
Run on Comfy Cloud
下载下面的素材作为输入

2. 按步骤完成工作流
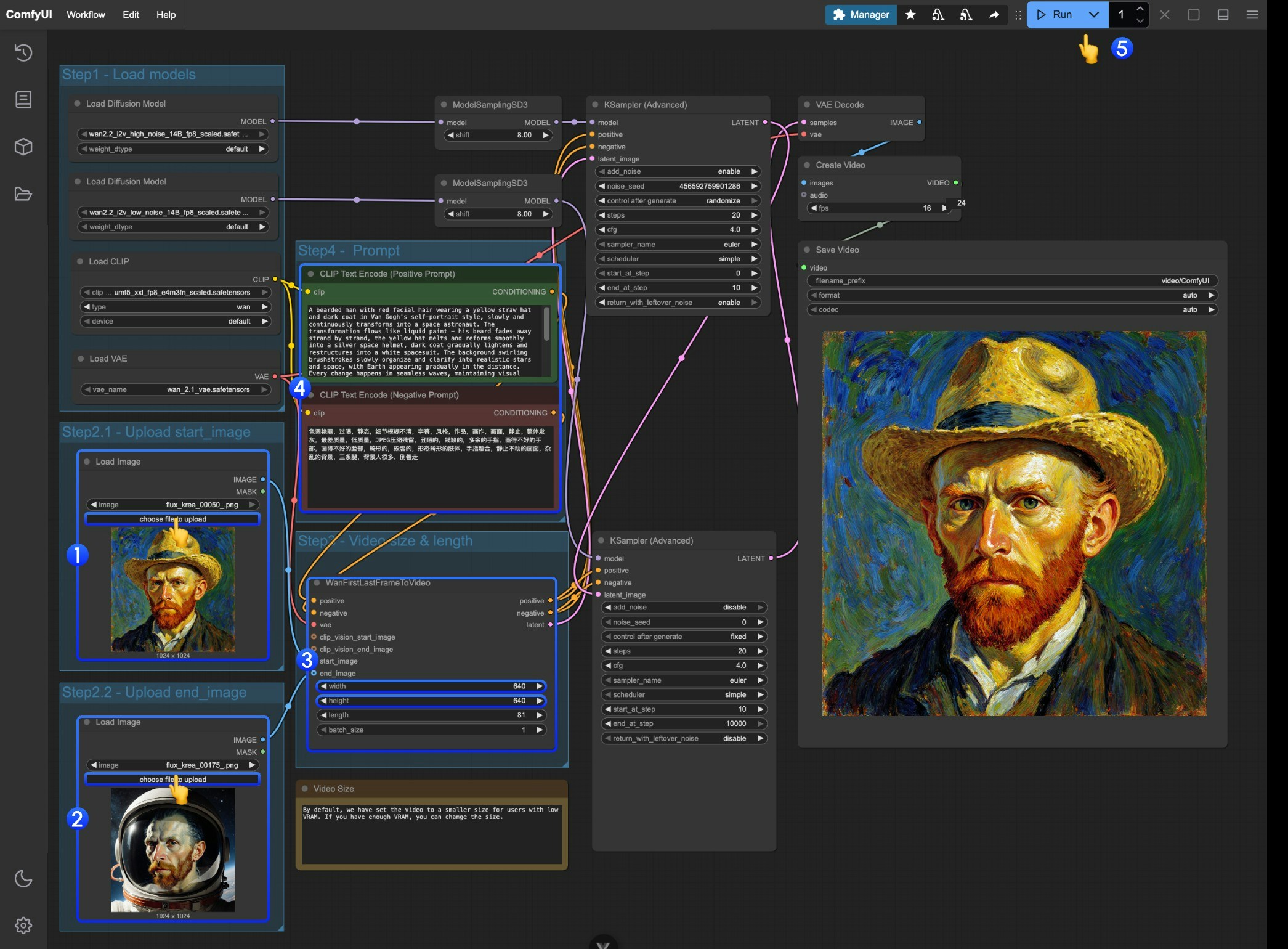
- 在第一个
Load Image节点上传作为起始帧的图像 - 在第二个
Load Image节点上传作为起始帧的图像 - 在
WanFirstLastFrameToVideo上修改尺寸设置- 我们默认设置了一个比较小的尺寸,防止低显存用户运行占用过多资源
- 如果你有足够的显存,可以尝试 720P 左右尺寸
- 根据你的首尾帧撰写合适的提示词
- 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成