- 首尾帧控制:支持输入首帧和尾帧图像,生成中间过渡视频,提升视频连贯性与创意自由度
- 高质量视频生成:基于 Wan2.2 架构,输出影视级质量视频
- 多分辨率支持:支持生成512×512、768×768、1024×1024等分辨率的视频,适配不同场景需求
- 14B 高性能版:模型体积达 32GB+,效果更优但需高显存支持
ComfyOrg Wan2.2 Fun InP & Control Youtube 直播回放
对于 ComfyUI Wan2.2 的使用,我们有进行了直播,你可以查看这些回放了解如何使用Wan2.2 Fun Inp 首尾帧视频生成工作流示例
这里提供的工作流包含了两个版本:- 使用了 lightx2v 的 Wan2.2-Lightning 4 步 LoRA : 但可能导致生成的视频动态会有损失,但速度会更快
- 没有使用加速 LoRA 的 fp8_scaled 版本
| 模型类型 | 分辨率 | 显存占用 | 首次生成时长 | 第二次生成时长 |
|---|---|---|---|---|
| fp8_scaled | 640×640 | 83% | ≈ 524秒 | ≈ 520秒 |
| fp8_scaled + 4步LoRA加速 | 640×640 | 89% | ≈ 138秒 | ≈ 79秒 |
1. 工作流文件下载
下载 JSON 格式工作流
Run on Comfy Cloud
使用下面的素材作为首尾帧

2. 手动下载模型
Diffusion Model- wan2.2_fun_inpaint_high_noise_14B_fp8_scaled.safetensors
- wan2.2_fun_inpaint_low_noise_14B_fp8_scaled.safetensors
- wan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors
- wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
3. 按步骤完成工作流
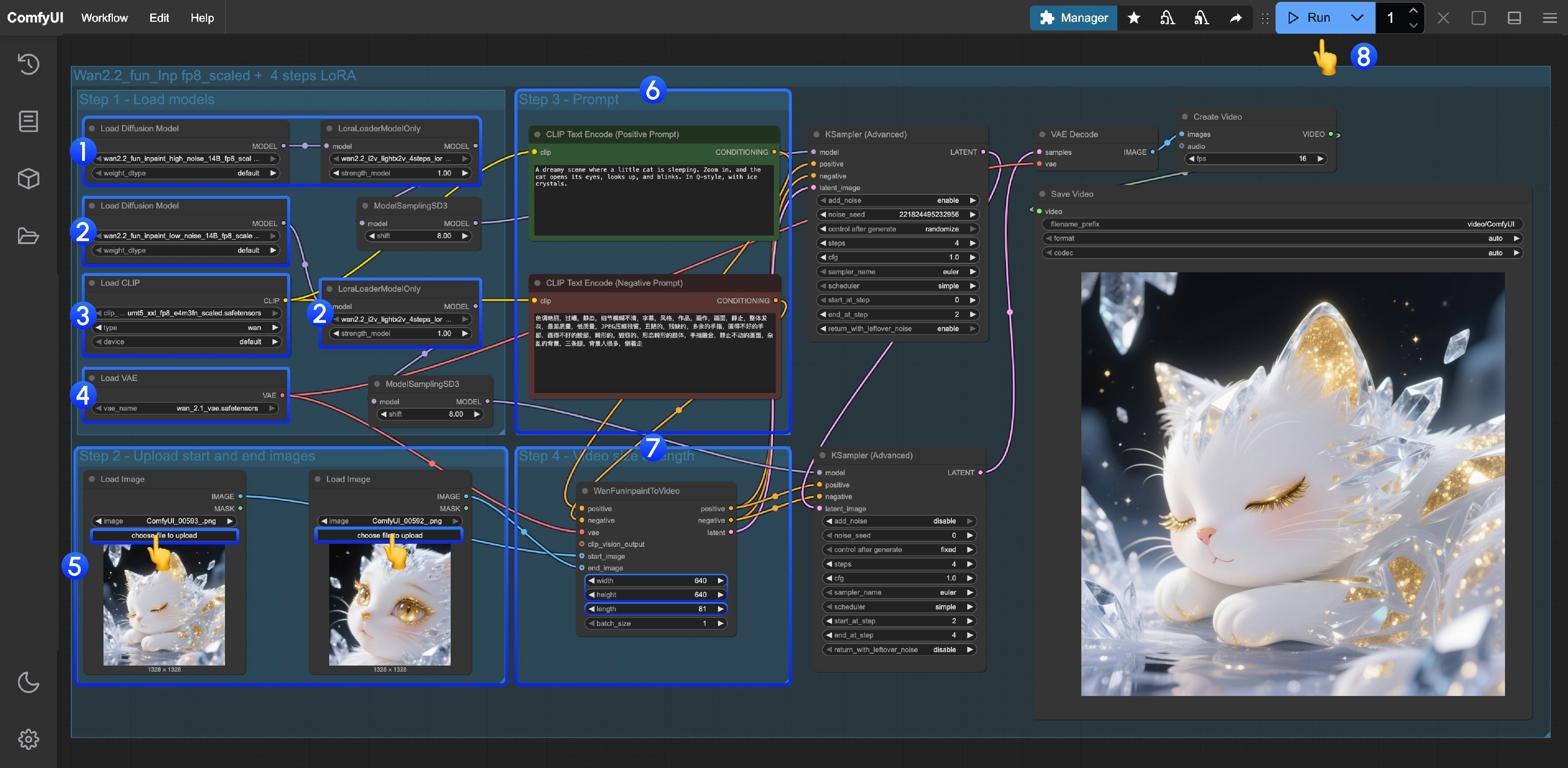
这个工作流是使用了 LoRA 的工作流,请确保对应的 Diffusion model 和 LoRA 是一致的
- High noise 模型及 LoRA 加载
- 确保
Load Diffusion Model节点加载了wan2.2_fun_inpaint_high_noise_14B_fp8_scaled.safetensors模型 - 确保
LoraLoaderModelOnly节点加载了wan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors
- Low noise 模型及 LoRA 加载
- 确保
Load Diffusion Model节点加载了wan2.2_fun_inpaint_low_noise_14B_fp8_scaled.safetensors模型 - 确保
LoraLoaderModelOnly节点加载了wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
- 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 首尾帧图片上传,分别上传首尾帧图片素材
- 在 Prompt 组中输入提示词
WanFunInpaintToVideo节点尺寸和视频长度调整- 调整
width和height的尺寸,默认为640, 我们设置了较小的尺寸你可以按需进行修改 - 调整
length, 这里为视频总帧数,当前工作流 fps 为 16, 假设你需要生成一个 5 秒的视频,那么你应该设置 5*16 = 80
- 调整
- 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成