- 音频驱动视频生成:将静态图片和音频转化为同步视频
- 电影级画质:生成具有自然表情和动作的高质量视频
- 分钟级生成:支持长时长视频创作
- 多格式支持:适用于全身和半身角色
- 增强动作控制:可根据文本指令生成动作和环境
Wan2.2 S2V ComfyUI 原生工作流
1. 工作流文件下载
下载以下工作流文件并拖入 ComfyUI 中加载工作流。Download JSON Workflow
Run on Comfy Cloud
下载下面的图片及音频作为输入:
下载输入音频
2. 模型链接
你可以在 我们的仓库 中找到所有模型。 diffusion_models audio_encoders vae text_encoders3. 工作流说明
3.1 关于 Lightning LoRA
3.2 关于 fp8_scaled 和 bf16 模型
你可以在 这里 找到两种模型: 本模板使用wan2.2_s2v_14B_fp8_scaled.safetensors,它需要更少的显存。但你可以尝试 wan2.2_s2v_14B_bf16.safetensors 来减少质量损失。
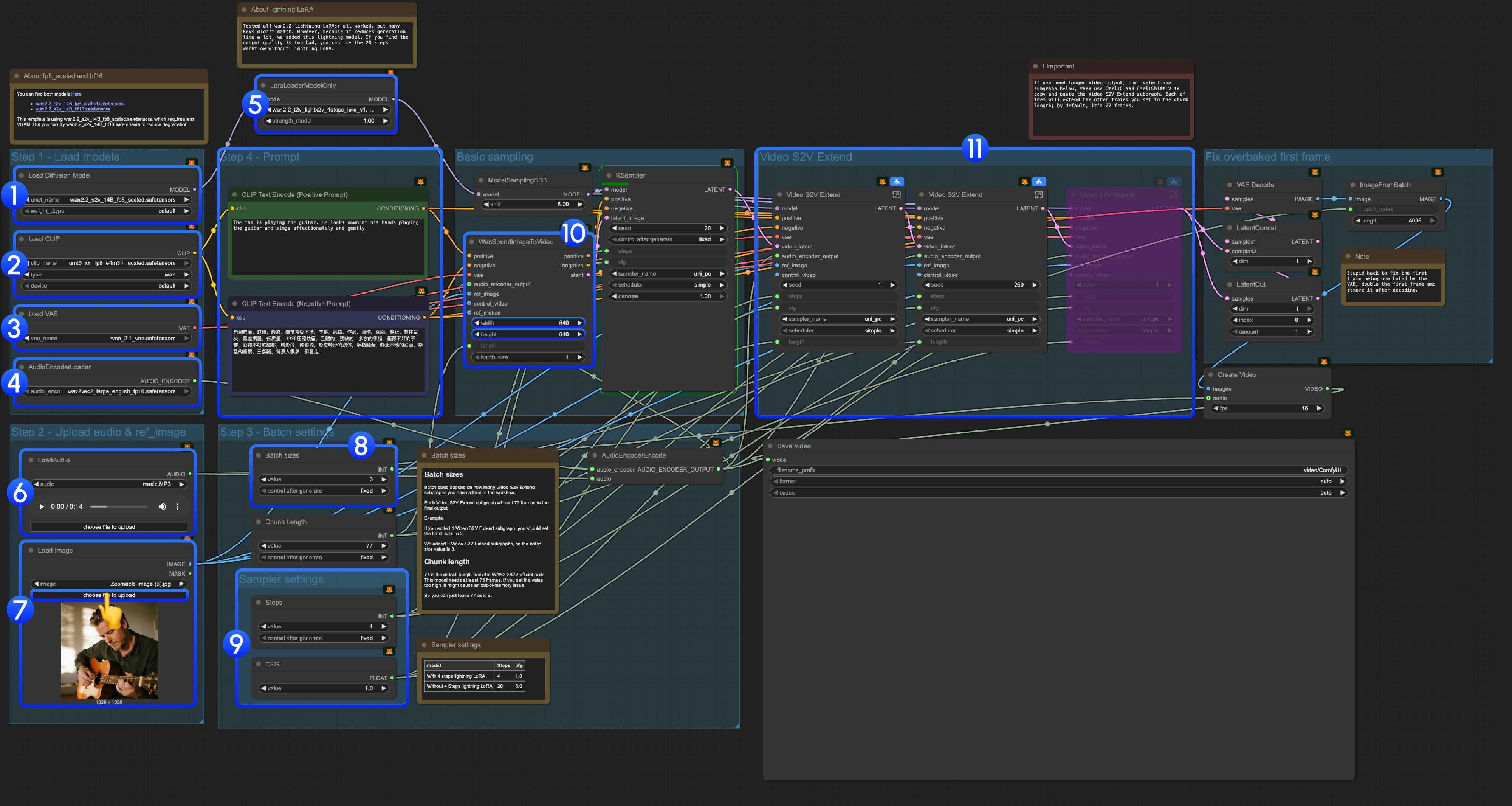
3.3 逐步操作说明
步骤 1:加载模型-
Load Diffusion Model:加载
wan2.2_s2v_14B_fp8_scaled.safetensors或wan2.2_s2v_14B_bf16.safetensors- 提供工作流使用
wan2.2_s2v_14B_fp8_scaled.safetensors,它需要更少的显存 - 但你可以尝试
wan2.2_s2v_14B_bf16.safetensors来减少质量损失
- 提供工作流使用
-
Load CLIP:加载
umt5_xxl_fp8_e4m3fn_scaled.safetensors -
Load VAE:加载
wan_2.1_vae.safetensors -
AudioEncoderLoader:加载
wav2vec2_large_english_fp16.safetensors -
LoraLoaderModelOnly:加载
wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors(Lightning LoRA)- 测试了所有 wan2.2 lightning LoRAs,由于这并不是一个专门为 Wan2.2 S2V 训练的 LoRA,很多键值不匹配,但由于它能大幅减少生成时间,后续将继续优化这个模板
- 使用它会导致极大的动态和质量损失
- 如果你发现输出质量太差,可以尝试原始的 20 步工作流
- LoadAudio:上传我们提供的音频文件,或者你自己的音频
- Load Image:上传参考图片
-
Batch sizes:根据你添加的 Video S2V Extend 子图节点数量设置
- 每个 Video S2V Extend 子图会为最终输出添加 77 帧
- 例如:如果添加了 2 个 Video S2V Extend 子图,批处理大小应设为 3, 也就是这里应为所有总采样次数
- Chunk Length:保持默认值 77
-
采样器设置: 根据是否使用 Lightning LoRA 选择不同设置
- 使用 4 步 Lightning LoRA: steps: 4, cfg: 1.0
- 不使用 4 步 Lightning LoRA: steps: 20, cfg: 6.0
- 尺寸设置: 设置输出视频的尺寸
-
Video S2V Extend:视频扩展子图节点,由于我们默认的每次采样帧数为 77, 由于这是一个 16fps 的模型,所以每个扩展将会生成 77 / 16 = 4.8125 秒的视频
- 你需要一定的计算来使得视频扩展子图节点的数量和输入音频数量匹配,如: 输入音频为 14s, 则需要的总帧数为 14x16=224, 每个视频扩展为 77 帧,所以你需要 224/77 = 2.9 向上取整则为 3 个视频扩展子图节点
- 使用 Ctrl-Enter 或者点击 运行按钮来运行工作流