OmniGen2 소개
OmniGen2는 약 7B의 총 파라미터(텍스트 모델 3B + 이미지 생성 모델 4B)를 갖춘 강력하고 효율적인 통합 멀티모달 생성 모델입니다. OmniGen v1과 달리, OmniGen2는 완전히 독립된 텍스트 자기회귀 모델과 이미지 확산 모델을 갖춘 혁신적인 이중 경로 트랜스포머 아키텍처를 채택해 파라미터 분리와 특화된 최적화를 달성했습니다.모델 주요 특징
- 시각적 이해: Qwen-VL-2.5 파운데이션 모델의 강력한 이미지 콘텐츠 해석 및 분석 능력을 계승
- 텍스트 기반 이미지 생성: 텍스트 프롬프트로부터 고화질이고 미학적으로 뛰어난 이미지를 생성
- 지시어 기반 이미지 편집: 복잡한 지시어 기반 이미지 수정을 수행하며, 오픈소스 모델 중 최고 수준의 성능 달성
- 맥락 기반 생성: 사람, 참조 객체, 장면 등 다양한 입력을 처리하고 유연하게 조합해 참신하고 일관된 시각적 출력을 생성하는 다재다능한 기능
기술적 특징
- 이중 경로 아키텍처: Qwen 2.5 VL (3B) 텍스트 인코더 + 독립적 확산 트랜스포머 (4B) 기반
- Omni-RoPE 위치 인코딩: 다중 이미지 공간 위치 지정 및 개체 식별 지원
- 파라미터 분리 설계: 텍스트 생성이 이미지 품질에 부정적인 영향을 미치는 것을 방지
- 복잡한 텍스트 이해 및 이미지 이해 지원
- 제어 가능한 이미지 생성 및 편집
- 뛰어난 디테일 보존 능력
- 여러 이미지 생성 작업을 지원하는 통합 아키텍처
- 텍스트 생성 기능: 이미지 내 명확한 텍스트 콘텐츠 생성 가능
OmniGen2 모델 다운로드
본 문서에는 다양한 워크플로우가 포함되어 있으므로, 해당 모델 파일과 설치 위치는 다음과 같습니다. 모델 파일의 다운로드 정보는 각 워크플로우에도 포함되어 있습니다. 확산 모델 VAE 텍스트 인코더 파일 저장 위치:ComfyUI OmniGen2 텍스트 기반 이미지 생성 워크플로우
1. 워크플로우 파일 다운로드
Comfy Cloud에서 실행

2. 워크플로우 단계별 완료
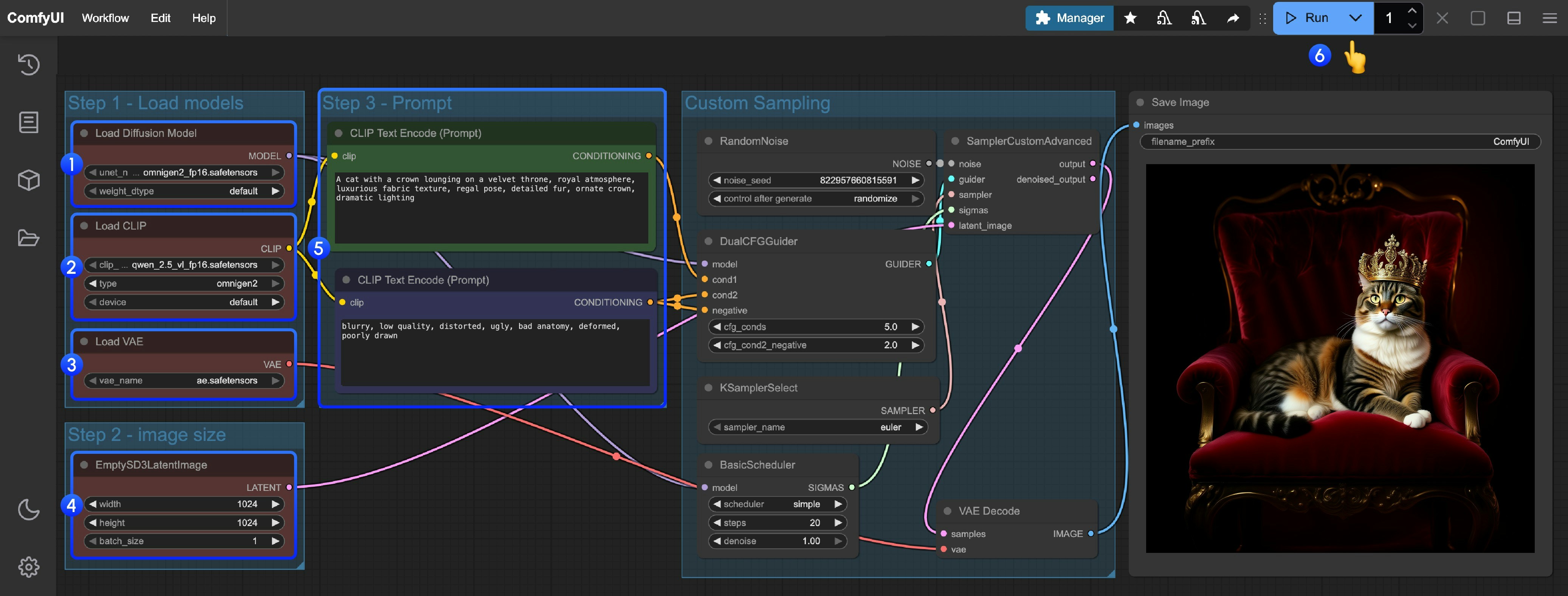
- 메인 모델 로드:
Load Diffusion Model노드가omnigen2_fp16.safetensors를 로드하는지 확인하세요. - 텍스트 인코더 로드:
Load CLIP노드가qwen_2.5_vl_fp16.safetensors를 로드하는지 확인하세요. - VAE 로드:
Load VAE노드가ae.safetensors를 로드하는지 확인하세요. - 이미지 크기 설정:
EmptySD3LatentImage노드에서 생성할 이미지 크기를 설정하세요(권장 크기 1024x1024). - 입력 프롬프트:
- 첫 번째
CLIPTextEncode노드에 긍정적 프롬프트를 입력하세요(이미지에 나타나길 원하는 내용). - 두 번째
CLIPTextEncode노드에 부정적 프롬프트를 입력하세요(이미지에 나타나지 않길 원하는 내용).
- 첫 번째
- 생성 시작:
Queue Prompt버튼을 클릭하거나, 단축키Ctrl(cmd) + Enter를 사용해 텍스트 기반 이미지 생성을 실행하세요. - 결과 확인: 생성이 완료되면 해당 이미지들이 자동으로
ComfyUI/output/디렉터리에 저장되며,SaveImage노드에서 미리보기할 수 있습니다.
ComfyUI OmniGen2 이미지 편집 워크플로우
OmniGen2는 풍부한 이미지 편집 기능을 갖추고 있으며, 이미지에 텍스트 추가도 지원합니다.1. 워크플로우 파일 다운로드
Comfy Cloud에서 실행
 아래 이미지를 다운로드하세요. 이 이미지를 입력 이미지로 사용하겠습니다.
아래 이미지를 다운로드하세요. 이 이미지를 입력 이미지로 사용하겠습니다.

2. 워크플로우 단계별 완료
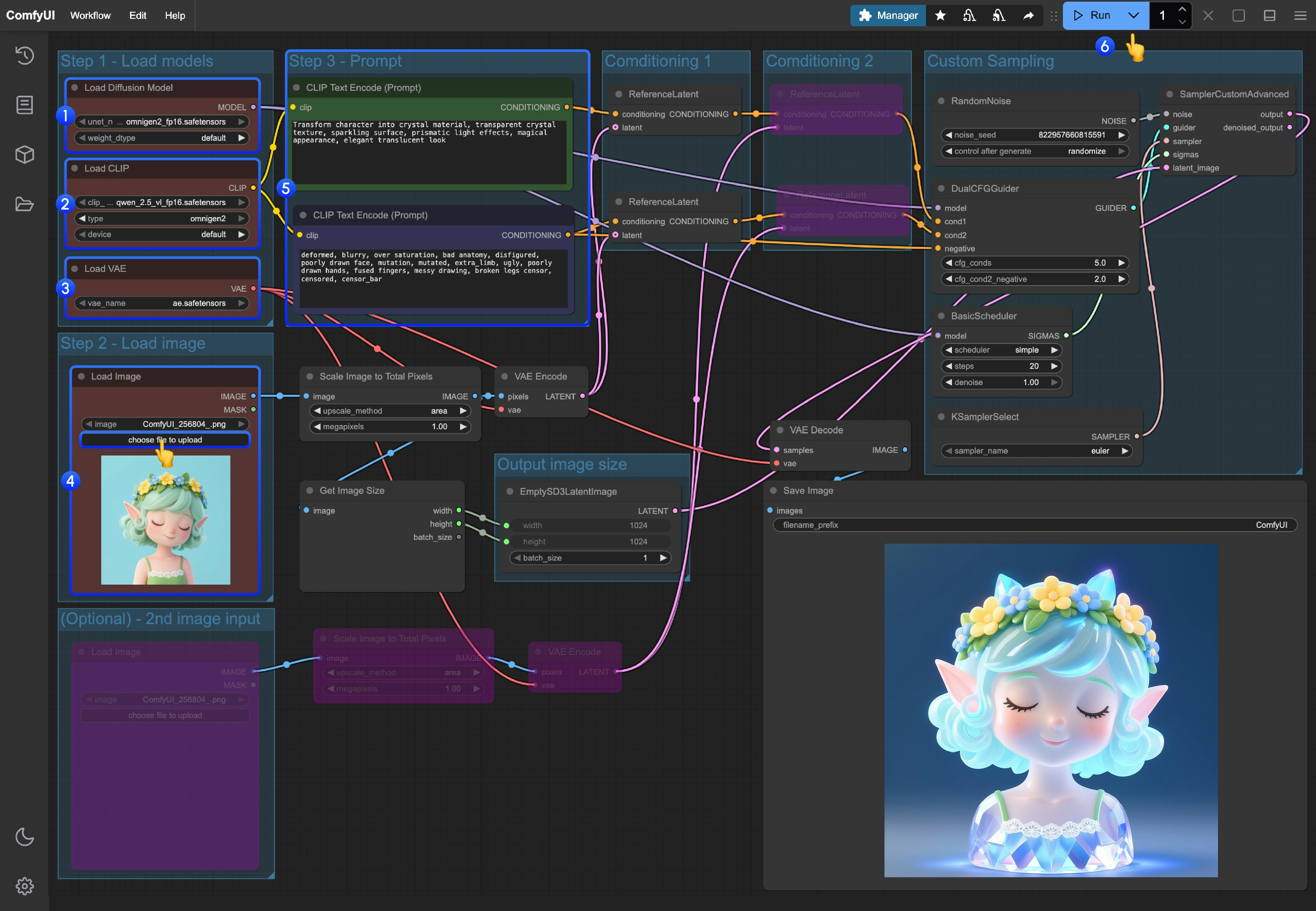
- 메인 모델 로드:
Load Diffusion Model노드가omnigen2_fp16.safetensors를 로드하는지 확인하세요. - 텍스트 인코더 로드:
Load CLIP노드가qwen_2.5_vl_fp16.safetensors를 로드하는지 확인하세요. - VAE 로드:
Load VAE노드가ae.safetensors를 로드하는지 확인하세요. - 이미지 업로드: 제공된 이미지를
Load Image노드에서 업로드하세요. - 입력 프롬프트:
- 첫 번째
CLIPTextEncode노드에 긍정적 프롬프트를 입력하세요(이미지에 나타나길 원하는 내용). - 두 번째
CLIPTextEncode노드에 부정적 프롬프트를 입력하세요(이미지에 나타나지 않길 원하는 내용).
- 첫 번째
- 생성 시작:
Queue Prompt버튼을 클릭하거나, 단축키Ctrl(cmd) + Enter를 사용해 텍스트 기반 이미지 생성을 실행하세요. - 결과 확인: 생성이 완료되면 해당 이미지들이 자동으로
ComfyUI/output/디렉터리에 저장되며,SaveImage노드에서 미리보기할 수 있습니다.
3. 추가 워크플로우 안내
- 두 번째 이미지 입력을 활성화하려면, 워크플로우에서 분홍색/보라