- 텍스트 기반 이미지 생성 워크플로우 완료하기
- 확산 모델 원리에 대한 기본적인 이해하기
- 워크플로우 노드의 기능과 역할 알아보기
- SD1.5 모델에 대한 초기 이해하기
텍스트 기반 이미지 생성이란?
텍스트 기반 이미지 생성은 텍스트 설명을 통해 이미지를 생성하는 AI 아트 생성의 핵심 과정으로, 그 중심에는 확산 모델이 있습니다. 텍스트 기반 이미지 생성 과정에는 다음과 같은 요소가 필요합니다:- 아티스트: 이미지 생성 모델
- 캔버스: 잠재 공간
- 이미지 요구사항(프롬프트): 긍정적 프롬프트(이미지에 포함되기를 원하는 요소)와 부정적 프롬프트(포함되지 않기를 원하는 요소) 포함
ComfyUI 텍스트 기반 이미지 생성 워크플로우 예제 가이드
1. 준비 작업
ComfyUI/models/checkpoints 폴더에 최소 한 개의 SD1.5 모델 파일이 있는지 확인하세요. 예를 들어 v1-5-pruned-emaonly-fp16.safetensors가 있습니다.
아직 설치하지 않았다면, ComfyUI AI 아트 생성 시작하기의 모델 설치 섹션을 참고해 주세요.
2. 텍스트 기반 이미지 생성 워크플로우 로드하기
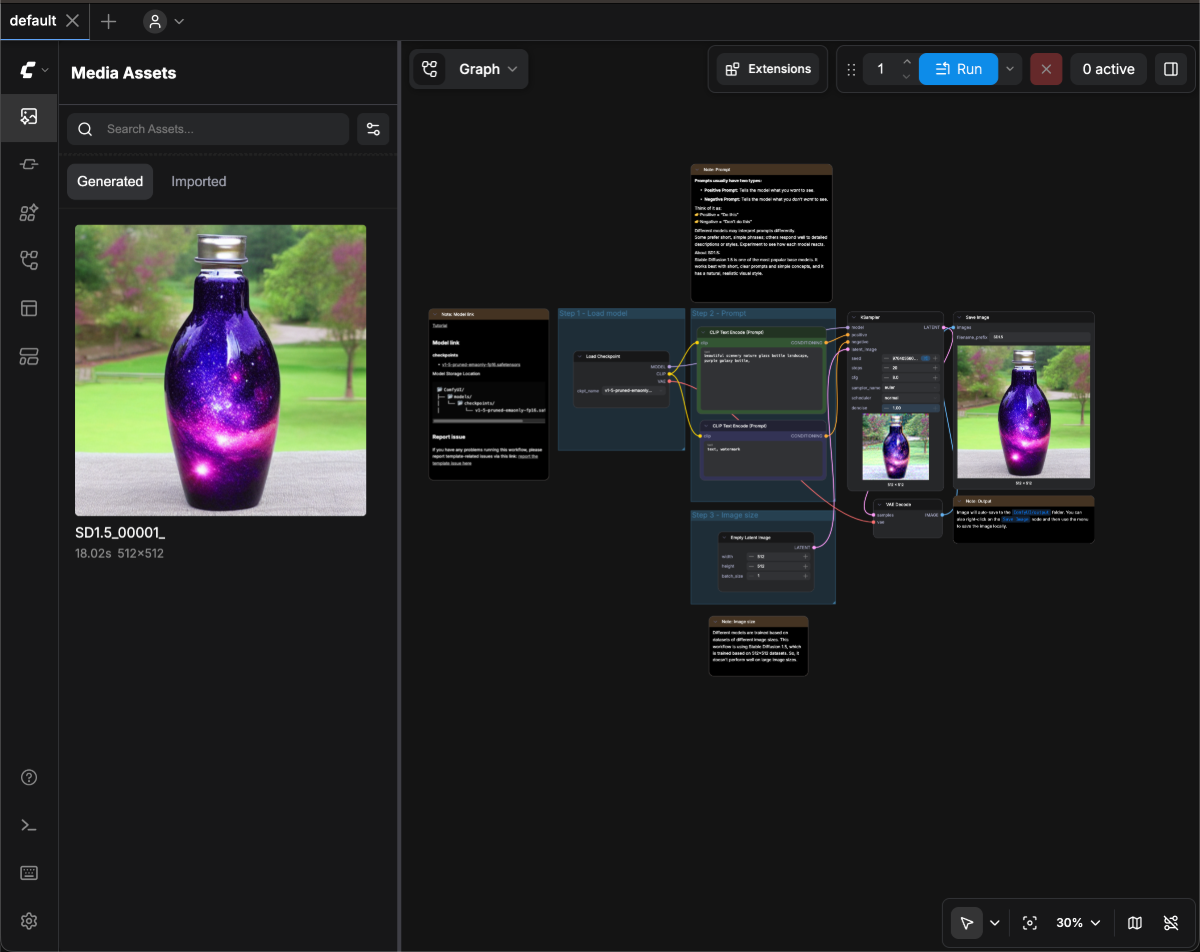
아래 이미지를 다운로드한 후, ComfyUI로 드래그하여 워크플로우를 로드하세요:
3. 모델 로드 및 첫 번째 이미지 생성하기
이미지 모델을 설치한 후, 아래 이미지를 따라 모델을 로드하고 첫 번째 이미지를 생성하세요. 이미지 번호에 따라 다음 단계를 따르세요:
이미지 번호에 따라 다음 단계를 따르세요:
- Load Checkpoint 노드에서 화살표를 사용하거나 텍스트 영역을 클릭해 v1-5-pruned-emaonly-fp16.safetensors가 선택되었는지 확인하고, 좌우 화살표에 null 텍스트가 표시되지 않도록 하세요.
Queue버튼을 클릭하거나 단축키Ctrl + Enter를 사용해 이미지 생성을 실행하세요.
4. 실험 시작하기
CLIP Text Encoder의 텍스트를 수정해 보세요.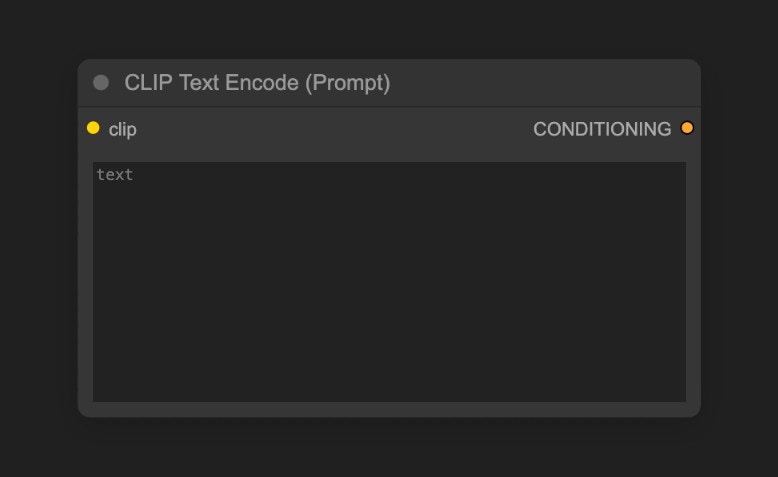
Positive 연결은 긍정적 프롬프트를, Negative 연결은 부정적 프롬프트를 나타냅니다.
SD1.5 모델을 위한 몇 가지 기본 프롬프팅 원칙은 다음과 같습니다:
- 가능하면 영어를 사용하세요.
- 프롬프트는 영어 쉼표
,로 구분하세요. - 긴 문장보다는 구체적인 표현을 사용하세요.
- 구체적인 묘사를 사용하세요.
(golden hour:1.2)와 같은 표현을 사용해 특정 키워드의 중요도를 높여 이미지에 더 많이 나타나게 할 수 있습니다. 여기서1.2는 가중치이고,golden hour는 키워드입니다.masterpiece, best quality, 4k와 같은 키워드를 사용해 생성 품질을 높일 수 있습니다.
텍스트 기반 이미지 생성 작동 원리
텍스트 기반 이미지 생성 전체 과정은 역확산 과정으로 이해할 수 있습니다. 우리가 다운로드한 v1-5-pruned-emaonly-fp16.safetensors는 사전 훈련된 모델로, 순수한 가우시안 노이즈로부터 목표 이미지를 생성할 수 있습니다. 우리는 단지 우리의 프롬프트만 입력하면, 무작위 노이즈를 제거해 목표 이미지를 생성할 수 있습니다. 우리는 두 가지 개념을 이해해야 합니다:- 잠재 공간: 잠재 공간은 확산 모델에서 사용하는 추상적인 데이터 표현 방식입니다. 이미지를 픽셀 공간에서 잠재 공간으로 변환하면 저장 공간이 줄어들고, 확산 모델 훈련과 노이즈 제거 복잡성을 줄이는 데 유리합니다. 마치 건축가들이 건물 설계 대신 설계도(잠재 공간)를 사용하는 것과 같으며, 구조적 특징을 유지하면서 수정 비용을 크게 줄일 수 있습니다.
- 픽셀 공간: 픽셀 공간은 이미지를 저장하는 공간으로, 우리가 최종적으로 보는 이미지이며 픽셀 값을 저장합니다.
ComfyUI 텍스트 기반 이미지 생성 워크플로우 노드 설명
A. Load Checkpoint 노드
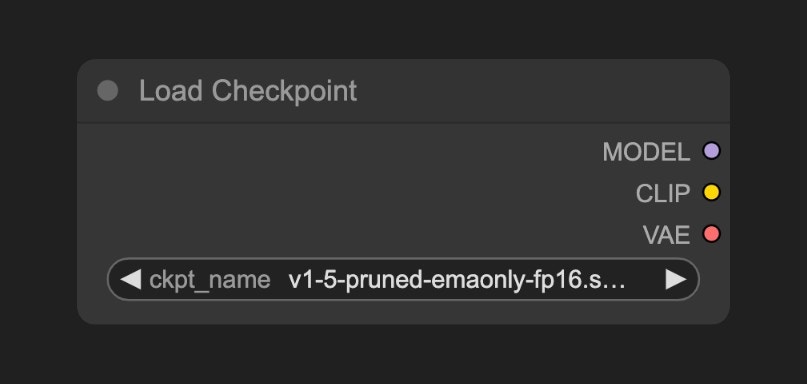
checkpoint는 보통 세 가지 구성 요소를 포함합니다: MODEL (UNet), CLIP, 그리고 VAE
MODEL (UNet): 확산 과정 중 노이즈 예측과 이미지 생성을 담당하는 UNet 모델CLIP: 텍스트 프롬프트를 모델이 이해할 수 있는 벡터로 변환하는 텍스트 인코더로, 모델은 직접 텍스트 프롬프트를 이해할 수 없기 때문입니다.VAE: 이미지를 픽셀 공간과 잠재 공간 간에 변환하는 변분 AutoEncoder로, 확산 모델은 잠재 공간에서 작동하며 우리의 이미지는 픽셀 공간에 있습니다.
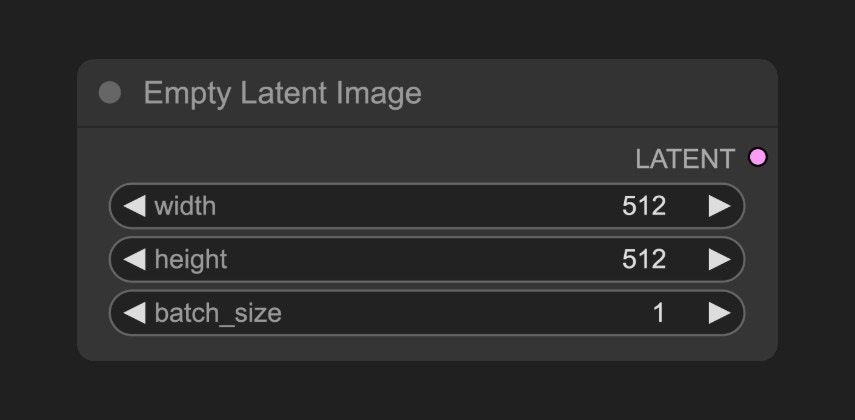
B. Empty Latent Image 노드
C. CLIP Text Encoder 노드
- KSampler 노드에 연결된
Positive조건 입력은 긍정적 프롬프트(이미지에 포함되기를 원하는 요소)를 나타냅니다. - KSampler 노드에 연결된
Negative조건 입력은 부정적 프롬프트(이미지에 포함되지 않기를 원하는 요소)를 나타냅니다.
Load Checkpoint 노드의 CLIP 구성 요소에 의해 의미적 벡터로 인코딩되고, KSampler 노드에 조건으로 출력됩니다.
D. KSampler 노드
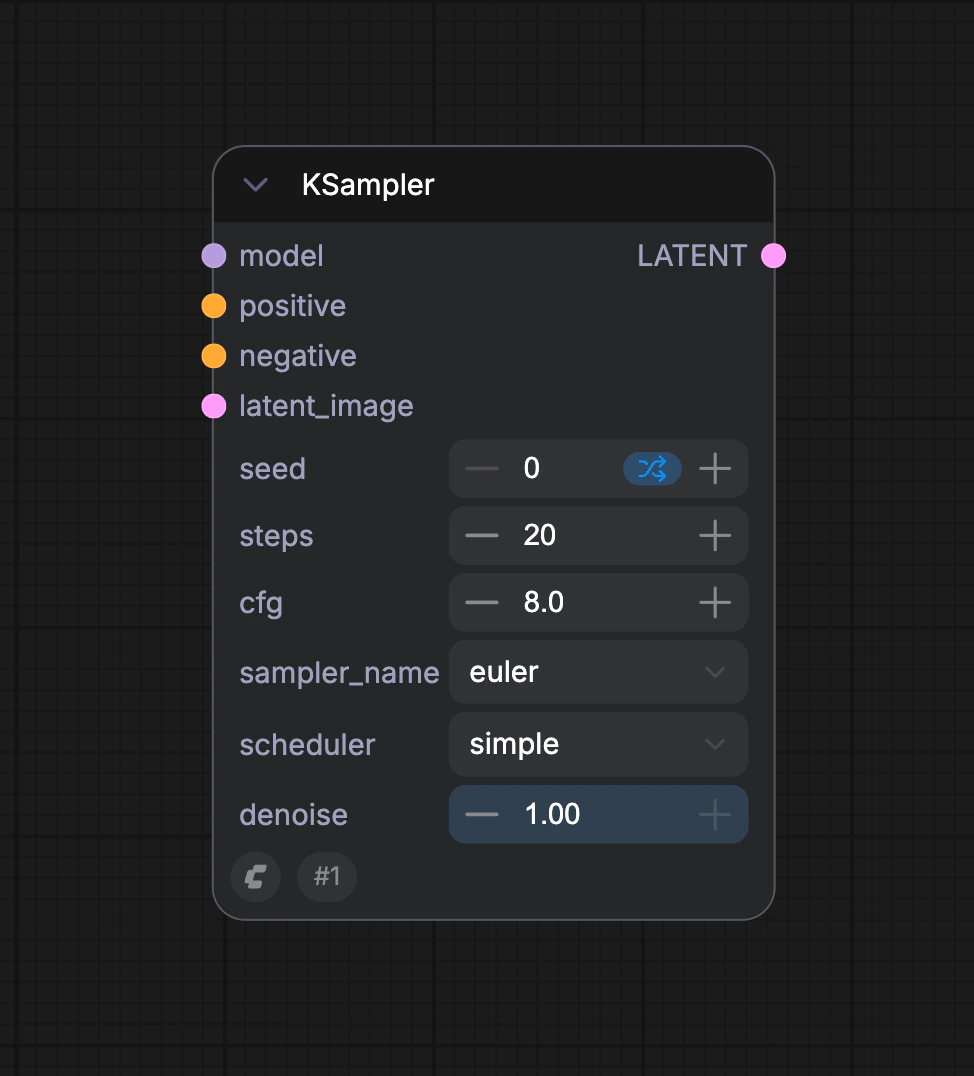
KSampler 노드에서 잠재 공간은
seed를 초기화 파라미터로 사용해 랜덤 노이즈를 구성하고, 의미적 벡터 Positive와 Negative는 조건으로 확산 모델에 입력됩니다.
그런 다음, steps 파라미터로 지정된 노이즈 제거 단계 수에 따라 노이즈 제거가 수행됩니다. 각 노이즈 제거 단계는 denoise 파라미터로 지정된 노이즈 제거 강도 계수를 사용해 잠재 공간을 노이즈 제거하고 새로운 잠재 공간 이미지를 생성합니다.
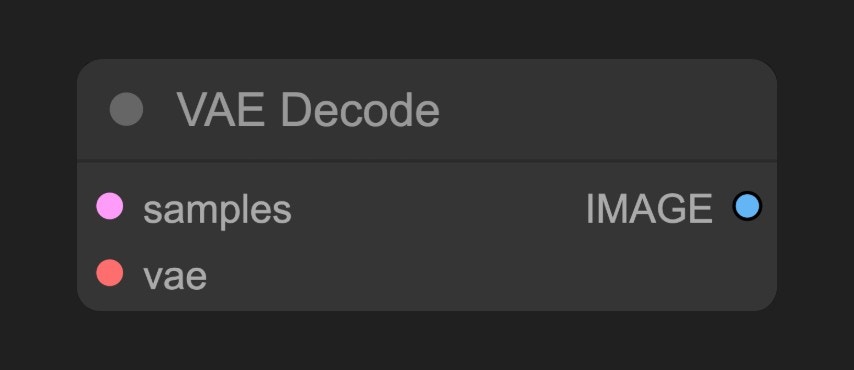
E. VAE 디코드 노드
F. Save Image 노드
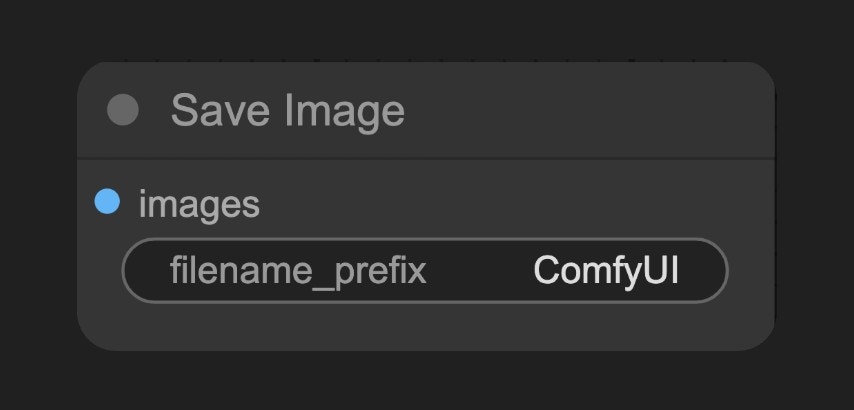
ComfyUI/output 폴더로 저장합니다.
SD1.5 모델 소개
**SD1.5 (Stable Diffusion 1.5)**는 Stability AI에서 개발한 AI 이미지 생성 모델입니다. Stable Diffusion 시리즈의 기본 버전으로, 512×512 해상도 이미지로 훈련되어 이 해상도에서 특히 뛰어난 이미지 생성 성능을 발휘합니다. 약 4GB 크기로, **소비자급 GPU(예: 6GB VRAM)**에서도 원활하게 작동합니다. 현재 SD1.5는 다양한 플러그인(예: ControlNet, LoRA)과 최적화 도구를 지원하는 풍부한 생태계를 갖추고 있습니다. AI 아트 생성의 이정표와 같은 모델로서, SD1.5는 오픈소스 성격과 경량 아키텍처, 풍부한 생태계 덕분에 여전히 최고의 입문용 선택입니다. SDXL/SD3와 같은 신버전이 출시되었지만, 소비자급 하드웨어에서의 가치는 여전히 타의 추종을 불허합니다.기본 정보
- 출시일: 2022년 10월
- 핵심 아키텍처: 잠재 확산 모델(LDM) 기반
- 훈련 데이터: LAION-Aesthetics v2.5 데이터셋(약 5.9억 회 훈련 단계)
- 오픈소스 특징: 모델/코드/훈련 데이터 모두 완전 오픈소스
장점과 한계
모델 장점:- 경량: 약 4GB 크기로 소비자 GPU에서도 원활히 작동
- 진입 장벽 낮음: 다양한 플러그인과 최적화 도구를 지원
- 성숙한 생태계: 광범위한 플러그인 및 도구 지원
- 빠른 생성: 소비자 GPU에서도 원활한 작동
- 디테일 처리: 손이나 복잡한 조명에서 왜곡 발생 가능성
- 해상도 제한: 직접 1024x1024 생성 시 품질 저하
- 프롬프트 의존성: 정확한 영어 설명이 제어에 필수적임