 HiDream-I1 は、HiDream-ai 社が 2025 年 4 月 7 日に公式にオープンソース化したテキストから画像へ変換するモデルです。このモデルは 17B(170 億)パラメータを有し、MIT ライセンス の下で公開されており、個人プロジェクト、学術研究、商用利用のすべてに対応しています。現在、複数のベンチマークテストにおいて優れた性能を発揮しています。
HiDream-I1 は、HiDream-ai 社が 2025 年 4 月 7 日に公式にオープンソース化したテキストから画像へ変換するモデルです。このモデルは 17B(170 億)パラメータを有し、MIT ライセンス の下で公開されており、個人プロジェクト、学術研究、商用利用のすべてに対応しています。現在、複数のベンチマークテストにおいて優れた性能を発揮しています。
モデルの特徴
ハイブリッドアーキテクチャ設計拡散トランスフォーマー(DiT)とエキスパートの混合(MoE)アーキテクチャを組み合わせた設計:
- DiT を基盤とし、マルチモーダル情報を処理するための双方向ストリーム型 MMDiT モジュールと、グローバルな一貫性を最適化する単一ストリーム型 DiT モジュールを採用。
- 動的ルーティング機構により、計算リソースを柔軟に配分することで、複雑なシーン処理能力を向上させ、色再現性やエッジ処理などの細部表現においても優れた性能を発揮します。
以下の 4 種類のテキストエンコーダを統合:
- OpenCLIP ViT-bigG、OpenAI CLIP ViT-L(視覚的・意味的な整合性確保)
- T5-XXL(長文の解析)
- Llama-3.1-8B-Instruct(指示文の理解) この組み合わせにより、色・数量・空間関係など、複雑な意味解析において SOTA(State-of-the-Art)レベルの性能を達成しており、中国語プロンプトへの対応力は同様のオープンソースモデルと比較して著しく優れています。
本ワークフロー例について
本例では、ComfyOrg が再パッケージしたバージョンを使用します。本例で使用するすべてのモデルファイルは、HiDream-I1_ComfyUI リポジトリから入手できます。HiDream-I1 ワークフロー
ComfyUI ネイティブ版 HiDream-I1 の各種ワークフローにおけるモデル要件は基本的に同一であり、異なるのは diffusion models ファイルのみです。 どのバージョンを選択すべきか迷う場合は、以下の推奨事項をご参照ください:- HiDream-I1-Full:最高品質の画像生成が可能
- HiDream-I1-Dev:高品質な画像生成と速度のバランスを重視
- HiDream-I1-Fast:わずか 16 ステップで画像を生成可能。リアルタイムでの反復試行が必要なシナリオに最適
cfg パラメータを 1.0 に設定してください。該当するワークフローには、対応するパラメータ設定が明記されています。
モデルのインストール
以下に示すモデルファイルは、本例で共通して使用するファイルです。各リンクをクリックしてダウンロードし、指定された保存場所に配置してください。
diffusion models については、それぞれのワークフローで個別にダウンロード方法をご案内します。 text_encoders:
- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors このモデルは多くのワークフローで既に使用されており、すでにダウンロード済みである可能性があります。
- llama_3.1_8b_instruct_fp8_scaled.safetensors
- ae.safetensors これは Flux の VAE モデルであり、以前に Flux のワークフローを使用したことがある場合、すでにダウンロード済みである可能性があります。
対応するワークフローで、該当するモデルファイルのダウンロード方法をご案内します。 モデルファイルの保存場所
HiDream-I1 Full バージョンのワークフロー
Comfy Cloud で実行
1. モデルファイルのダウンロード
ハードウェア環境に応じて適切なバージョンを選択し、対応するリンクをクリックして、ComfyUI/models/diffusion_models/ フォルダにダウンロードしてください。
- FP8 バージョン:hidream_i1_full_fp8.safetensors(VRAM 16GB 以上が必要)
- 完全版:hidream_i1_full_f16.safetensors(VRAM 27GB 以上が必要)
2. ワークフローファイルのダウンロード
以下の画像をダウンロードし、ComfyUI にドラッグ&ドロップして、対応するワークフローを読み込んでください。
3. ワークフローの実行手順(ステップバイステップ)
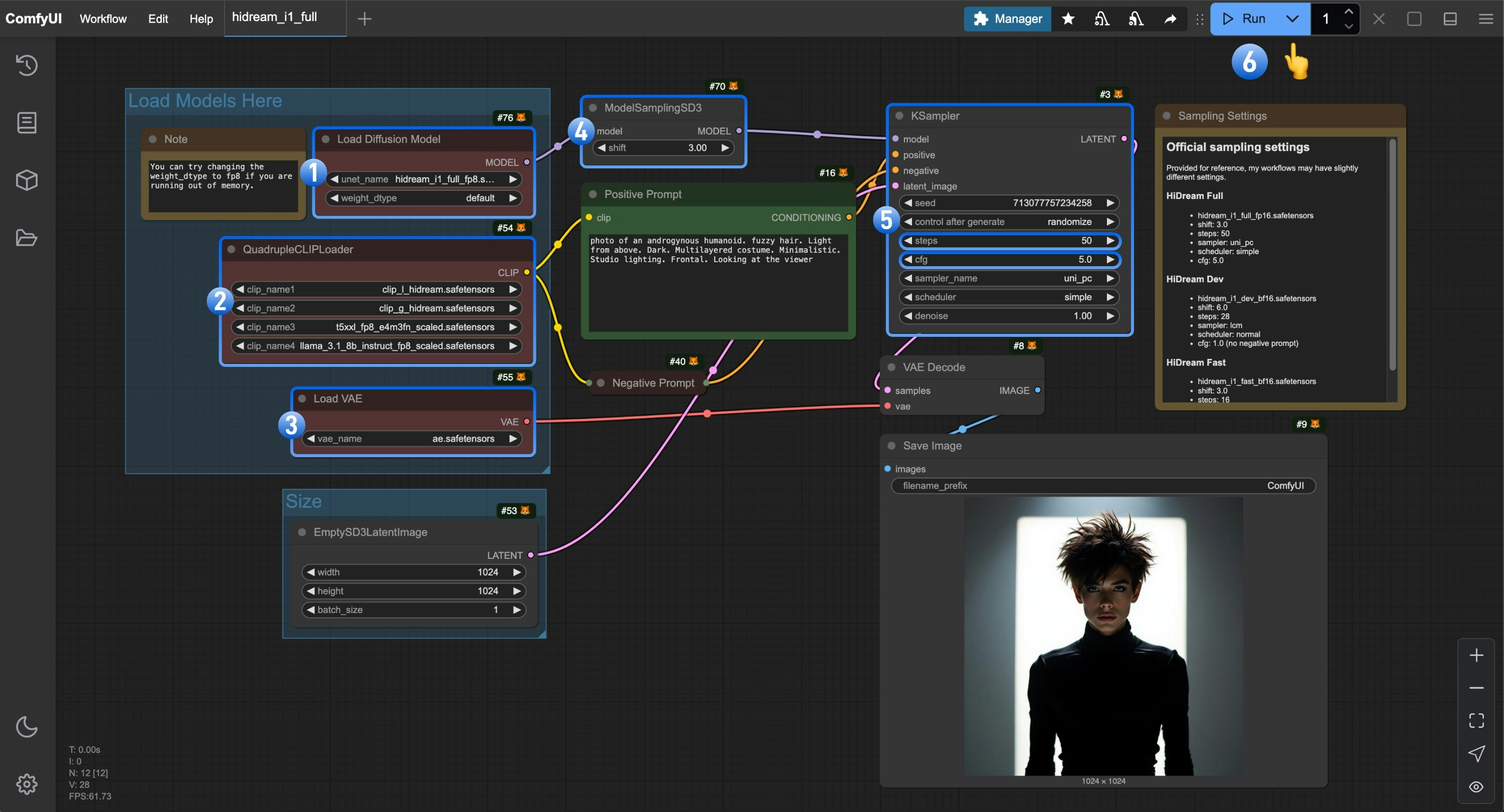
Load Diffusion Modelノードがhidream_i1_full_fp8.safetensorsファイルを使用していることを確認してください。QuadrupleCLIPLoader内の 4 つのテキストエンコーダが正しく読み込まれていることを確認してください:- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensors
Load VAEノードがae.safetensorsファイルを使用していることを確認してください。- Full バージョンでは、
ModelSamplingSD3ノードのshiftパラメータを3.0に設定してください。 Ksamplerノードでは、以下の設定を行ってください:stepsを50に設定cfgを5.0に設定- (任意)
samplerをlcmに設定 - (任意)
schedulerをnormalに設定
Runボタンをクリックするか、ショートカットキーCtrl(Cmd)+ Enterを押して、画像生成を実行してください。
HiDream-I1 Dev バージョンのワークフロー
Comfy Cloud で実行
1. モデルファイルのダウンロード
ハードウェア環境に応じて適切なバージョンを選択し、対応するリンクをクリックして、ComfyUI/models/diffusion_models/ フォルダにダウンロードしてください。
- FP8 バージョン:hidream_i1_dev_fp8.safetensors(VRAM 16GB 以上が必要)
- 完全版:hidream_i1_dev_bf16.safetensors(VRAM 27GB 以上が必要)
2. ワークフローファイルのダウンロード
以下の画像をダウンロードし、ComfyUI にドラッグ&ドロップして、対応するワークフローを読み込んでください。
3. ワークフローの実行手順(ステップバイステップ)
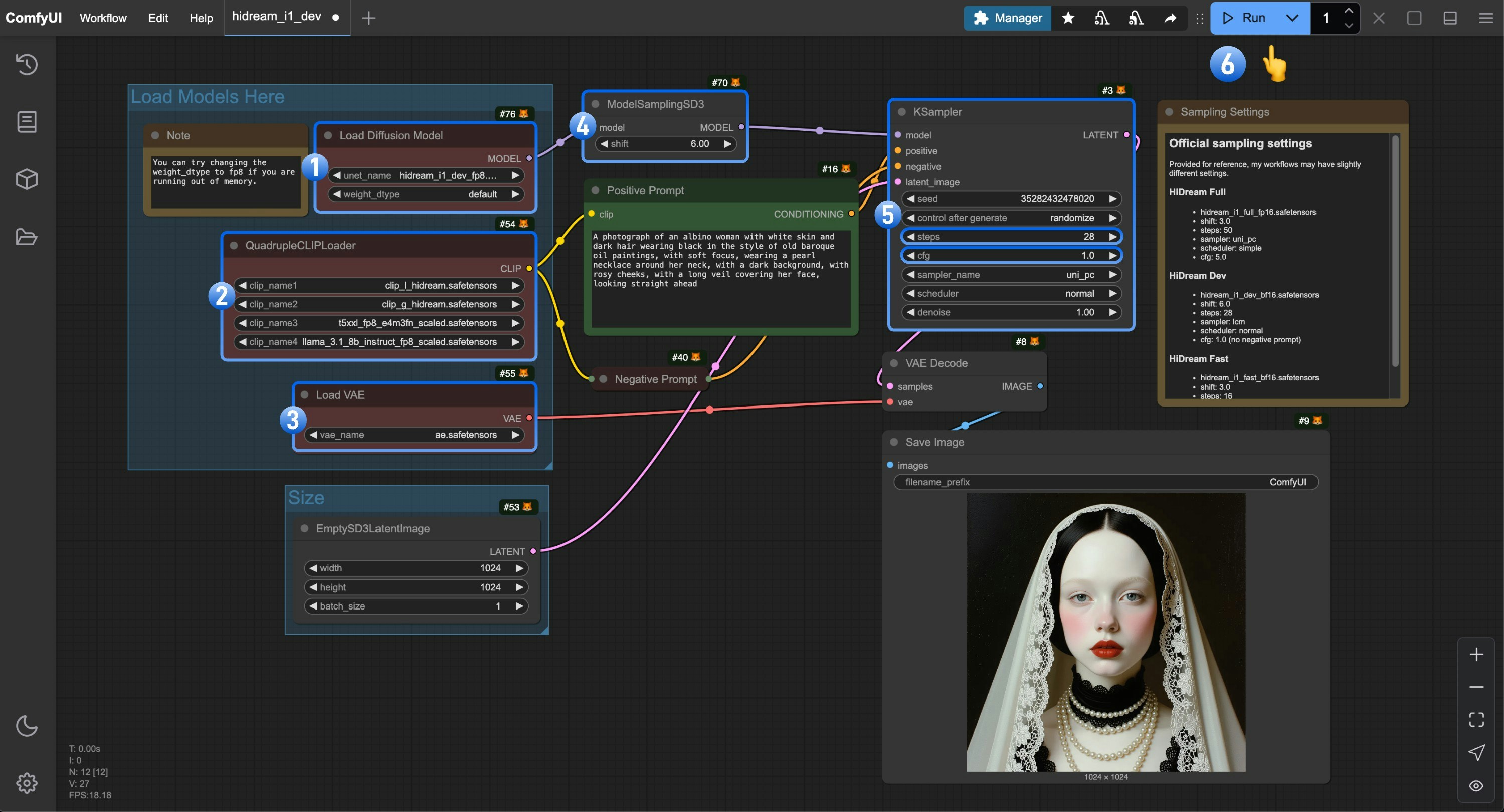
Load Diffusion Modelノードがhidream_i1_dev_fp8.safetensorsファイルを使用していることを確認してください。QuadrupleCLIPLoader内の 4 つのテキストエンコーダが正しく読み込まれていることを確認してください:- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensors
Load VAEノードがae.safetensorsファイルを使用していることを確認してください。- Dev バージョンでは、
ModelSamplingSD3ノードのshiftパラメータを6.0に設定してください。 Ksamplerノードでは、以下の設定を行ってください:stepsを28に設定- (重要)
cfgを1.0に設定 - (任意)
samplerをlcmに設定 - (任意)
schedulerをnormalに設定
Runボタンをクリックするか、ショートカットキーCtrl(Cmd)+ Enterを押して、画像生成を実行してください。
HiDream-I1 Fast バージョンのワークフロー
Comfy Cloud で実行
1. モデルファイルのダウンロード
ハードウェア環境に応じて適切なバージョンを選択し、対応するリンクをクリックして、ComfyUI/models/diffusion_models/ フォルダにダウンロードしてください。
- FP8 バージョン:hidream_i1_fast_fp8.safetensors(VRAM 16GB 以上が必要)
- 完全版:hidream_i1_fast_bf16.safetensors(VRAM 27GB 以上が必要)
2. ワークフローファイルのダウンロード
以下の画像をダウンロードし、ComfyUI にドラッグ&ドロップして、対応するワークフローを読み込んでください。
3. ワークフローの実行手順(ステップバイステップ)
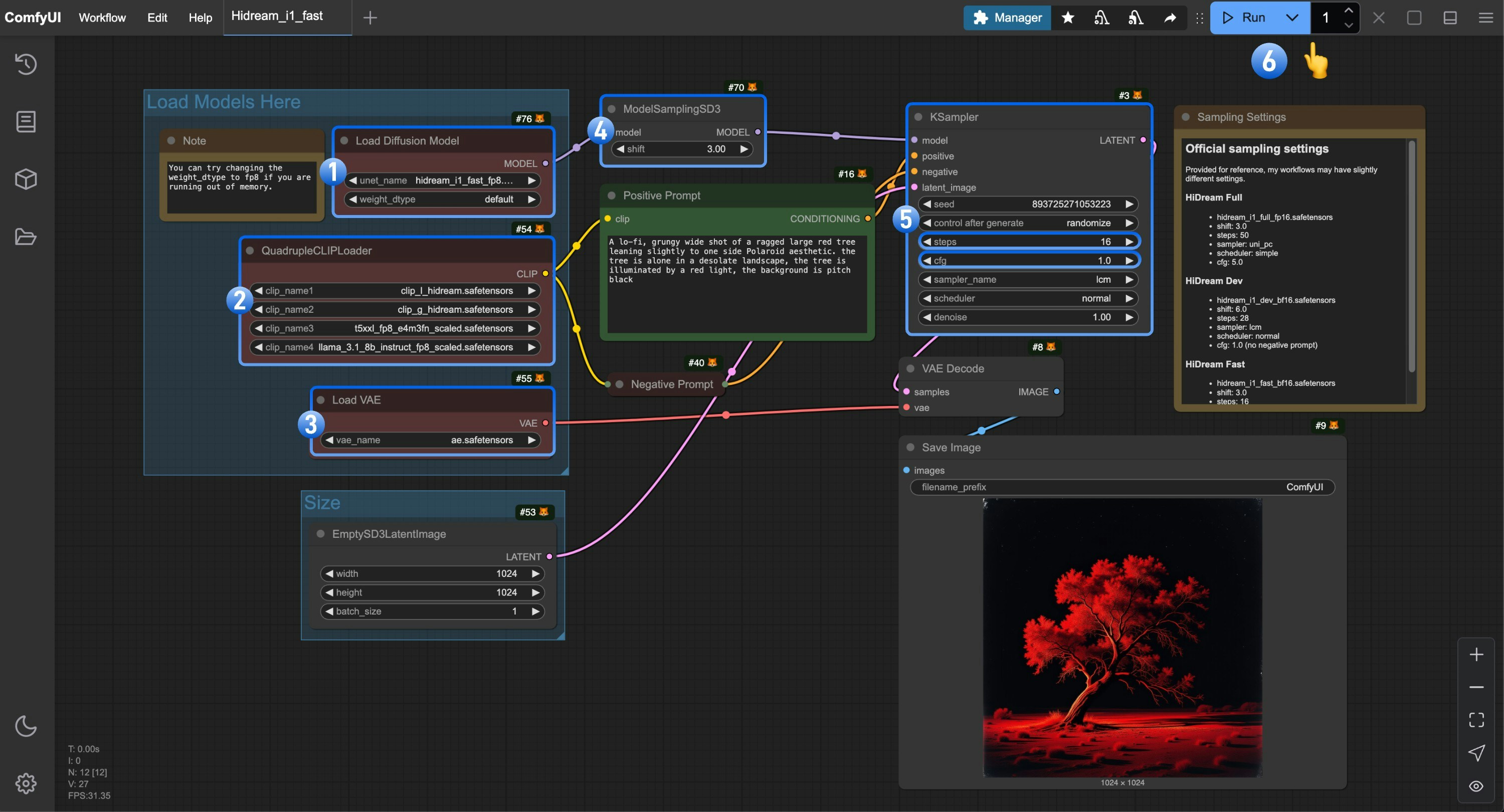
Load Diffusion Modelノードがhidream_i1_fast_fp8.safetensorsファイルを使用していることを確認してください。QuadrupleCLIPLoader内の 4 つのテキストエンコーダが正しく読み込まれていることを確認してください:- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensors
Load VAEノードがae.safetensorsファイルを使用していることを確認してください。- Fast バージョンでは、
ModelSamplingSD3ノードのshiftパラメータを3.0に設定してください。 Ksamplerノードでは、以下の設定を行ってください:stepsを16に設定- (重要)
cfgを1.0に設定 - (任意)
samplerをlcmに設定 - (任意)
schedulerをnormalに設定
Runボタンをクリックするか、ショートカットキーCtrl(Cmd)+ Enterを押して、画像生成を実行してください。
その他の関連リソース
GGUF バージョンのモデル
GGUF バージョンのモデルを利用するには、City96 が提供する ComfyUI-GGUF 拡張のUnet Loader (GGUF) ノードを、標準の Load Diffusion Model ノードと置き換える必要があります。
NF4 バージョンのモデル
- HiDream-I1-nf4
- NF4 バージョンのモデルを利用するには、ComfyUI-HiDream-Sampler 拡張のノードを使用します。