OmniGen2 について
OmniGen2 は、総パラメータ数約 70 億(テキストモデル 30 億 + 画像生成モデル 40 億)の、強力かつ効率的な統合型マルチモーダル生成モデルです。OmniGen v1 とは異なり、OmniGen2 は革新的な「デュアルパス Transformer アーキテクチャ」を採用しており、テキストの自己回帰モデルと画像の拡散モデルが完全に独立しています。これにより、パラメータの分離(decoupling)と専門化された最適化が実現されています。モデルの主な特長
- 視覚的理解能力: Qwen-VL-2.5 ベースモデルが持つ優れた画像内容の解釈・分析能力を継承
- テキストから画像への生成(Text-to-Image): テキストプロンプトから高忠実度で美しく仕上げられた画像を生成
- 指示に基づく画像編集(Instruction-guided Image Editing): 複雑な指示を用いた画像変更を実行可能で、オープンソースモデルの中では最先端の性能を達成
- コンテキスト対応の生成(Contextual Generation): 人物、参照オブジェクト、シーンなど多様な入力を柔軟に処理・組み合わせる汎用性を持ち、新規かつ一貫性のある視覚出力を生成
技術的特徴
- デュアルパスアーキテクチャ: Qwen 2.5 VL(30 億)テキストエンコーダー + 独立型拡散 Transformer(40 億)を基盤
- Omni-RoPE 位置エンコーディング: 複数画像の空間的位置付けおよび識別子の区別をサポート
- パラメータ分離設計: テキスト生成による画像品質への悪影響を回避
- 複雑なテキスト理解および画像理解をサポート
- 制御可能な画像生成および編集機能
- 優れたディテール保持能力
- 複数の画像生成タスクを統一アーキテクチャでサポート
- テキスト生成機能:画像内に明確な文字コンテンツを生成可能
OmniGen2 モデルのダウンロード
本記事では複数のワークフローを取り扱うため、対応するモデルファイルおよびインストール先は以下の通りです。各ワークフロー内にも、該当するモデルファイルのダウンロード情報が記載されています。 拡散モデル(Diffusion Models) VAE テキストエンコーダー(Text Encoders) ファイル保存先:ComfyUI OmniGen2 テキストから画像へ(Text-to-Image)ワークフロー
1. ワークフローファイルのダウンロード
Comfy Cloud で実行

2. ワークフローの手順通り実行
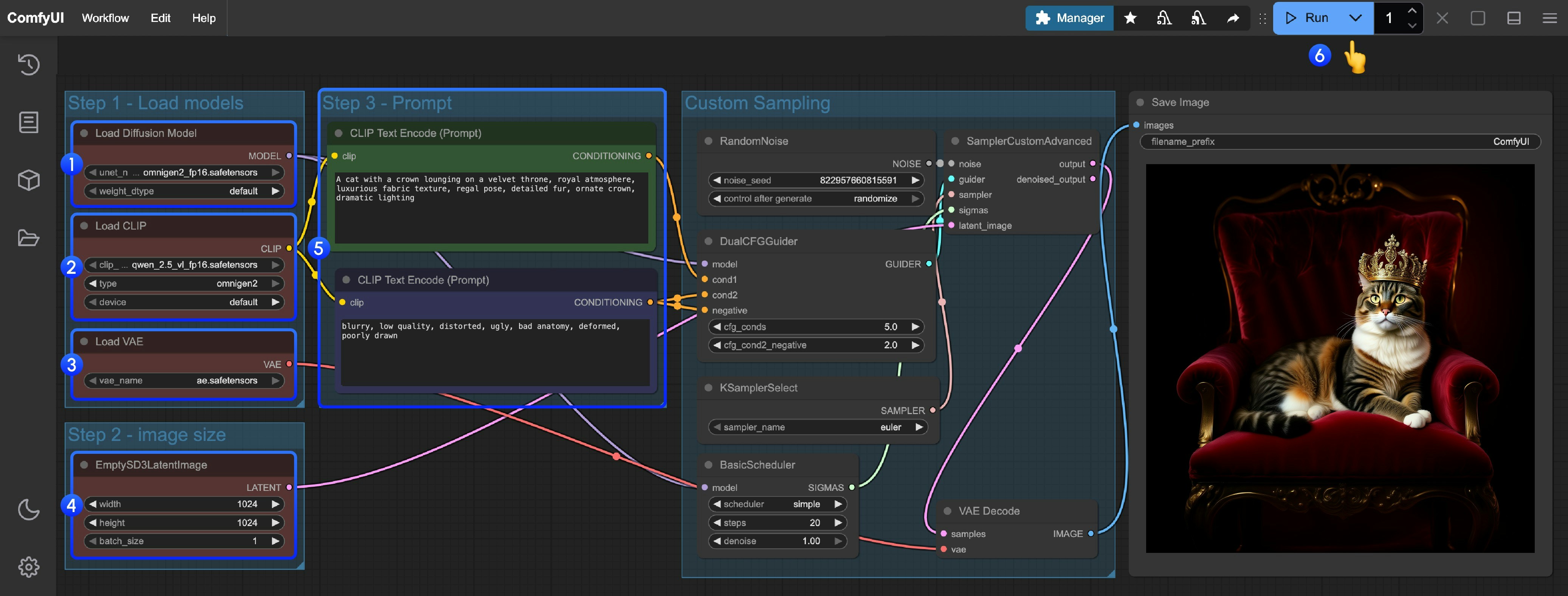
- メインモデルの読み込み:
Load Diffusion Modelノードがomnigen2_fp16.safetensorsを正しく読み込んでいることを確認 - テキストエンコーダーの読み込み:
Load CLIPノードがqwen_2.5_vl_fp16.safetensorsを正しく読み込んでいることを確認 - VAE の読み込み:
Load VAEノードがae.safetensorsを正しく読み込んでいることを確認 - 画像サイズの設定:
EmptySD3LatentImageノードで生成画像のサイズを設定(推奨:1024×1024) - プロンプトの入力:
- 最初の
CLipTextEncodeノードに「正のプロンプト」(画像に含めたい内容)を入力 - 2 つ目の
CLipTextEncodeノードに「負のプロンプト」(画像に含めたくない内容)を入力
- 最初の
- 生成開始:
Queue Promptボタンをクリックするか、ショートカットキーCtrl(Mac の場合は Cmd)+ Enterを押してテキストから画像への生成を実行 - 結果の確認: 生成が完了すると、対応する画像が自動的に
ComfyUI/output/ディレクトリに保存されます。また、SaveImageノード内でプレビューも可能です
ComfyUI OmniGen2 画像編集ワークフロー
OmniGen2 は豊富な画像編集機能を備えており、画像へのテキスト追加もサポートします。1. ワークフローファイルのダウンロード
Comfy Cloud で実行
 以下の画像をダウンロードし、この画像を入力として使用します。
以下の画像をダウンロードし、この画像を入力として使用します。

2. ワークフローの手順通り実行
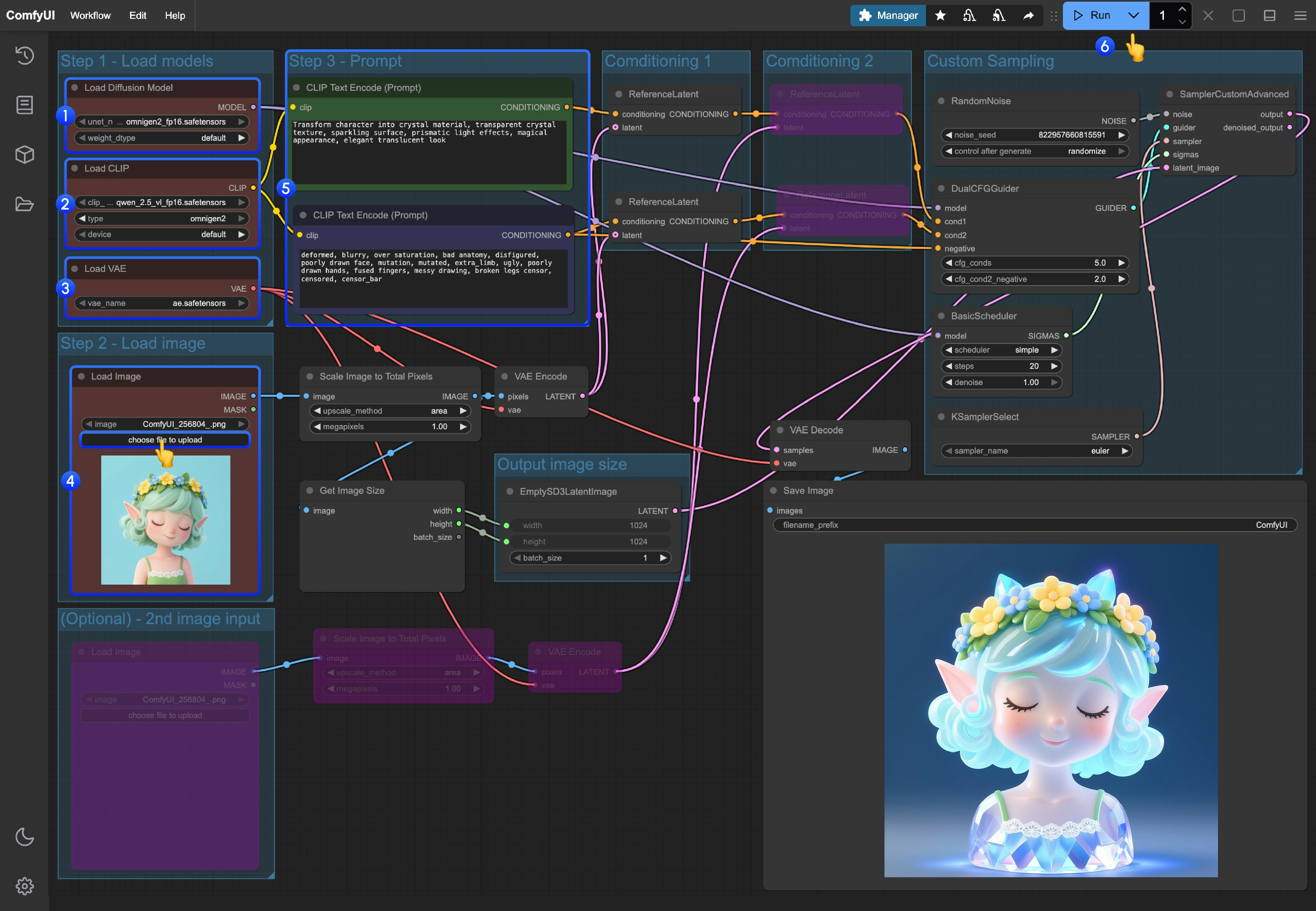
- メインモデルの読み込み:
Load Diffusion Modelノードがomnigen2_fp16.safetensorsを正しく読み込んでいることを確認 - テキストエンコーダーの読み込み:
Load CLIPノードがqwen_2.5_vl_fp16.safetensorsを正しく読み込んでいることを確認 - VAE の読み込み:
Load VAEノードがae.safetensorsを正しく読み込んでいることを確認 - 画像のアップロード:
Load Imageノードで上記の画像をアップロード - プロンプトの入力:
- 最初の
CLipTextEncodeノードに「正のプロンプト」(画像に含めたい内容)を入力 - 2 つ目の
CLipTextEncodeノードに「負のプロンプト」(画像に含めたくない内容)を入力
- 最初の
- 生成開始:
Queue Promptボタンをクリックするか、ショートカットキーCtrl(Mac の場合は Cmd)+ Enterを押して画像編集を実行 - 結果の確認: 生成が完了すると、対応する画像が自動的に
ComfyUI/output/ディレクトリに保存されます。また、SaveImageノード内でプレビューも可能です
3. 追加のワークフロー操作説明
- 第二の画像入力を有効化したい場合、ワークフロー内でピンク/パープル色で表示されているノードに対し、ショートカットキー Ctrl + B を使用して、対応する入力ポートを有効化できます
- カスタムサイズを指定したい場合、
EmptySD3LatentImageノードに接続されているGet image sizeノードを削除し、任意のサイズを直接入力してください