 HiDream-E1 は、HiDream-ai 社が公式にオープンソース化したインタラクティブな画像編集用大規模モデルであり、HiDream-I1 を基盤として構築されています。
自然言語による画像編集が可能です。本モデルは MIT ライセンス の下で公開されており、個人プロジェクト、学術研究、商用利用のいずれにも対応しています。
HiDream-E1 は、HiDream-ai 社が公式にオープンソース化したインタラクティブな画像編集用大規模モデルであり、HiDream-I1 を基盤として構築されています。
自然言語による画像編集が可能です。本モデルは MIT ライセンス の下で公開されており、個人プロジェクト、学術研究、商用利用のいずれにも対応しています。以前にリリースされた hidream-i1 と組み合わせることで、画像生成から画像編集までの一貫したクリエイティブな機能を実現します。
HiDream E1 - GitHub
HiDream E1 および E1.1 ワークフローに関連するモデル
本ガイドで使用されるすべてのモデルは、こちら から入手できます。Diffusion モデルを除き、E1 および E1.1 は同一のモデルを共有しています。対応するワークフローファイルには、関連モデルの情報も含まれています。モデルは手動でダウンロードして保存することもできますし、ワークフローを読み込んだ後に表示されるプロンプトに従って自動的にダウンロードすることもできます。推奨は E1.1 を使用することです。 本モデルの実行には大量の VRAM を必要とします。具体的な VRAM 要件については、関連セクションをご確認ください。 Diffusion モデル 両方のモデルを同時にダウンロードする必要はありません。E1.1 は E1 をベースとした改良版であり、実際のテスト結果から、品質およびパフォーマンスの両面で E1 を大幅に上回ることが確認されています。 テキストエンコーダー:
- clip_l_hidream.safetensors 236.12MB
- clip_g_hidream.safetensors 1.29GB
- t5xxl_fp8_e4m3fn_scaled.safetensors 4.8GB
- llama_3.1_8b_instruct_fp8_scaled.safetensors 8.46GB
- ae.safetensors 319.77MB
これは Flux 向けの VAE モデルです。以前に Flux ワークフローをご利用になったことがある場合、すでにこのファイルをダウンロード済みである可能性があります。モデルの保存先ディレクトリ構成:
HiDream E1.1 の ComfyUI ネイティブ ワークフローの例
E1.1 は 2025年7月16日にリリースされた更新版で、動的な 1メガピクセル解像度 をサポートしています。ワークフローではScale Image to Total Pixels ノードを用いて、入力画像を自動的に 100万ピクセルにスケーリングします。
1. HiDream E1.1 ワークフローおよび関連素材
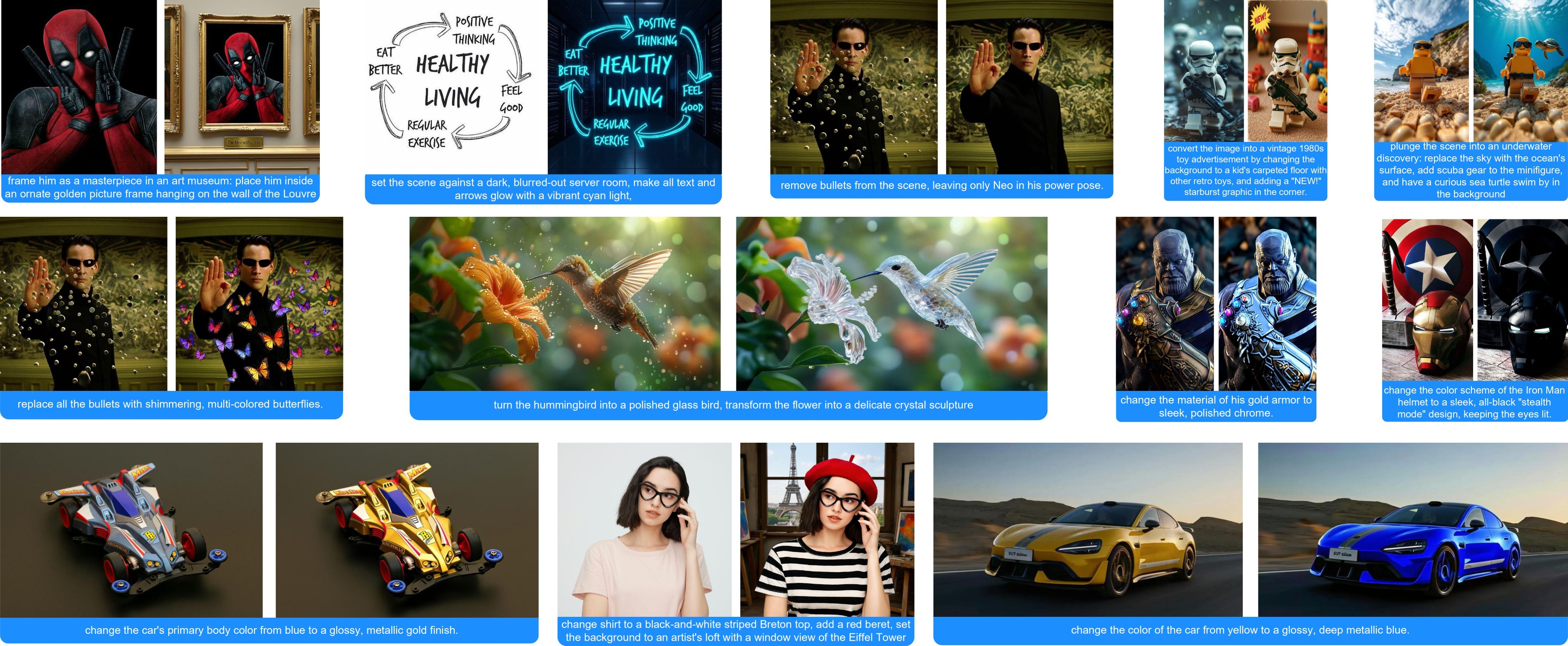
以下の画像をダウンロードし、対応するワークフローおよびモデルが読み込まれた状態で ComfyUI にドラッグ&ドロップしてください: 以下の画像を入力画像としてダウンロードしてください:
以下の画像を入力画像としてダウンロードしてください:
2. HiDream-e1 ワークフローの実行手順(ステップ・バイ・ステップ)
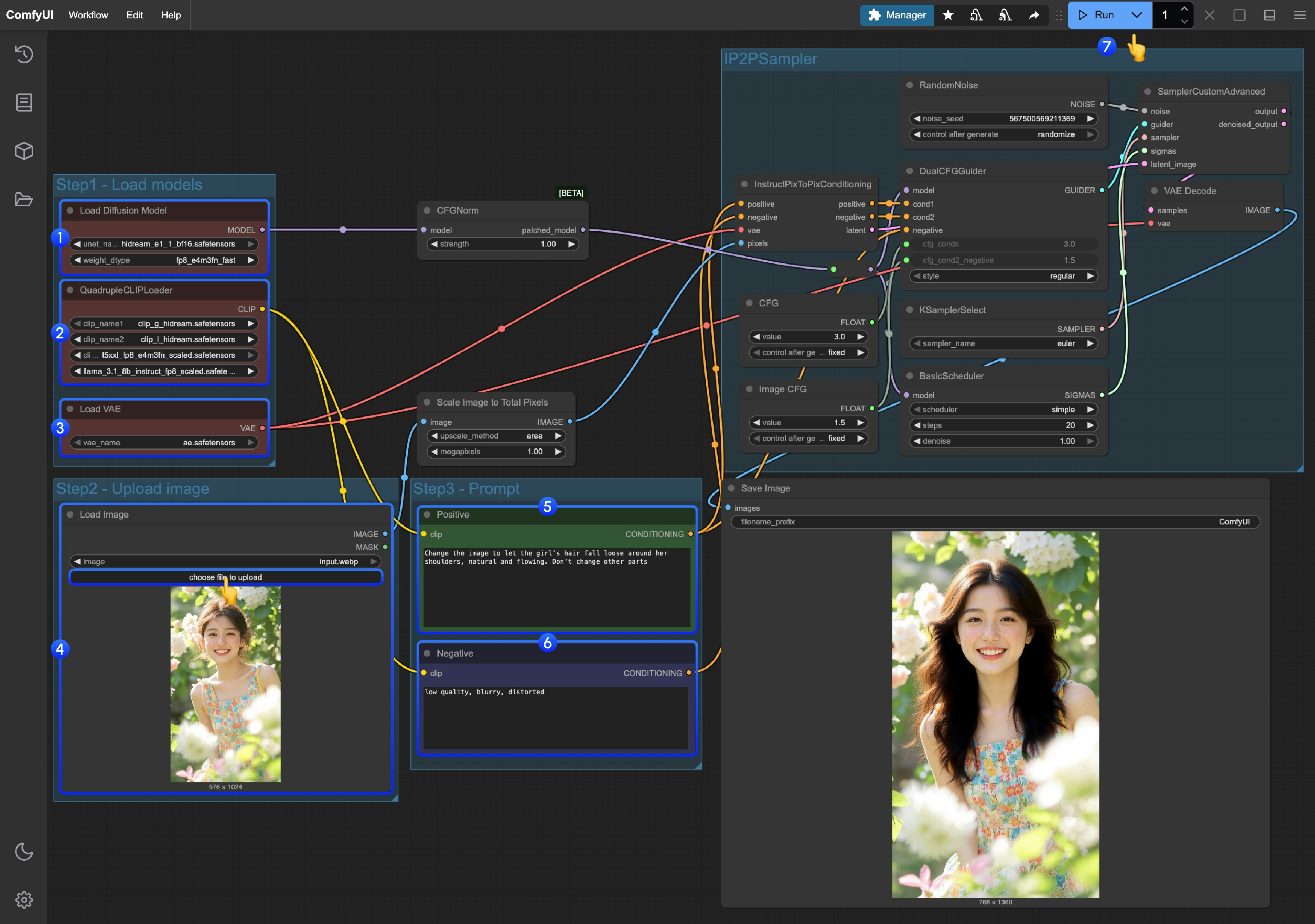
Load Diffusion Modelノードがhidream_e1_1_bf16.safetensorsを正しく読み込んでいることを確認してください。QuadrupleCLIPLoader内の4つのテキストエンコーダーが正しく読み込まれていることを確認してください:
- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensorsLoad VAEノードがae.safetensorsを使用していることを確認してください。Load Imageノードで、提供された入力画像または任意の画像を読み込んでください。Empty Text Encoder(Positive)ノードに、画像に対して行いたい変更内容 を入力してください。Empty Text Encoder(Negative)ノードに、画像に含めたくない要素 を入力してください。Runボタンをクリックするか、ショートカットキーCtrl(macOS の場合は Cmd) + Enterを押して画像生成を実行してください。
3. ワークフローに関する補足事項
- HiDream E1.1 は「合計ピクセル数が 100万」の動的入力をサポートするため、ワークフローでは
Scale Image to Total Pixelsノードを用いてすべての入力画像を処理・変換します。このため、元の入力画像と比較してアスペクト比が変化する場合があります。 - fp16 版モデルを使用する場合、A100 40GB および RTX 4090D 24GB における実際のテストでは、Full バージョンでメモリ不足(Out of memory)が発生しました。そのため、ワークフローはデフォルトで
fp8_e4m3fn_fastを推論に使用するよう設定されています。
HiDream E1 の ComfyUI ネイティブ ワークフローの例
Comfy Cloud で実行
E1 は 2025年4月28日にリリースされたモデルで、768×768 の固定解像度のみ をサポートします。1. HiDream-e1 ワークフロー
以下の画像をダウンロードし、ComfyUI にドラッグ&ドロップしてください。ワークフローには既にモデルのダウンロード情報が含まれており、読み込み後に該当モデルのダウンロードを促すメッセージが表示されます。 以下の画像を入力画像としてダウンロードしてください:
以下の画像を入力画像としてダウンロードしてください:
2. HiDream-e1 ワークフローの実行手順(ステップ・バイ・ステップ)
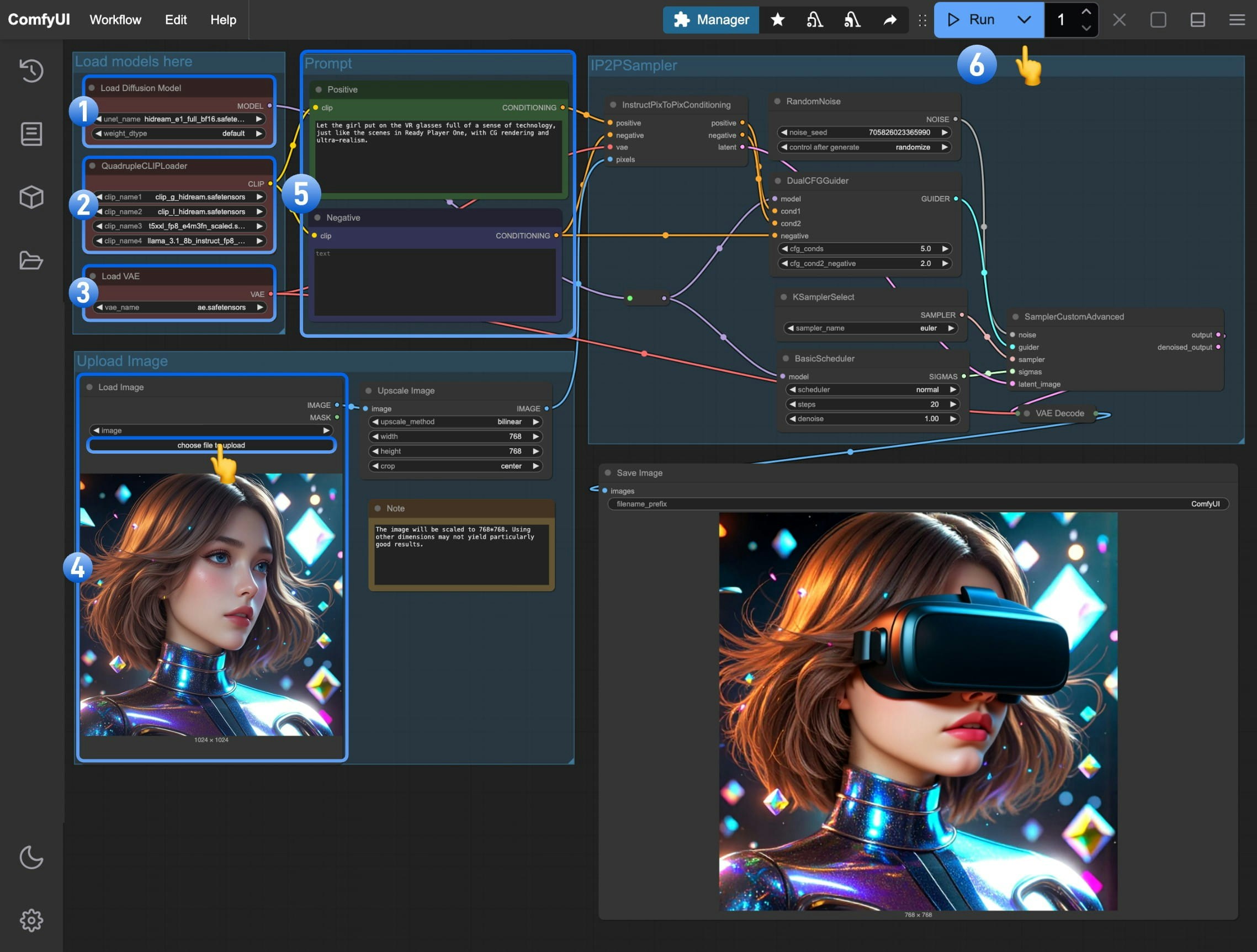
Load Diffusion Modelノードがhidream_e1_full_bf16.safetensorsを正しく読み込んでいることを確認してください。QuadrupleCLIPLoader内の4つのテキストエンコーダーが正しく読み込まれていることを確認してください:
- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensorsLoad VAEノードがae.safetensorsを使用していることを確認してください。Load Imageノードで、前述の手順でダウンロードした入力画像を読み込んでください。- (重要)
Empty Text Encoder(Positive)ノードに、画像をどのように変更したいかを表すプロンプト を入力してください。 Runボタンをクリックするか、ショートカットキーCtrl(macOS の場合は Cmd) + Enterを押して画像生成を実行してください。
ComfyUI HiDream-e1 ワークフローに関する補足事項
- より良い結果を得るためには、プロンプトを複数回修正したり、複数回生成を試行する必要がある場合があります。
- 本モデルは画像スタイルの変更時に一貫性を保つのが難しく、プロンプトをできる限り詳細かつ包括的に記述することを推奨します。
- モデルは 768×768 の解像度のみをサポートしており、他の解像度で実行した場合、画像品質が著しく低下したり、意図しない出力になることがあります。