 HiDream-I1 is a text-to-image model officially open-sourced by HiDream-ai on April 7, 2025. The model has 17B parameters and is released under the MIT license, supporting personal projects, scientific research, and commercial use.
It currently performs excellently in multiple benchmark tests.
HiDream-I1 is a text-to-image model officially open-sourced by HiDream-ai on April 7, 2025. The model has 17B parameters and is released under the MIT license, supporting personal projects, scientific research, and commercial use.
It currently performs excellently in multiple benchmark tests.
Model Features
Hybrid Architecture Design A combination of Diffusion Transformer (DiT) and Mixture of Experts (MoE) architecture:- Based on Diffusion Transformer (DiT), with dual-stream MMDiT modules processing multimodal information and single-stream DiT modules optimizing global consistency.
- Dynamic routing mechanism flexibly allocates computing resources, enhancing complex scene processing capabilities and delivering excellent performance in color restoration, edge processing, and other details.
- OpenCLIP ViT-bigG, OpenAI CLIP ViT-L (visual semantic alignment)
- T5-XXL (long text parsing)
- Llama-3.1-8B-Instruct (instruction understanding) This combination achieves SOTA performance in complex semantic parsing of colors, quantities, spatial relationships, etc., with Chinese prompt support significantly outperforming similar open-source models.
About This Workflow Example
In this example, we will use the repackaged version from ComfyOrg. You can find all the model files we’ll use in this example in the HiDream-I1_ComfyUI repository.HiDream-I1 Workflow
The model requirements for different ComfyUI native HiDream-I1 workflows are basically the same, with only the diffusion models files being different. If you don’t know which version to choose, please refer to the following suggestions:- HiDream-I1-Full can generate the highest quality images
- HiDream-I1-Dev balances high-quality image generation with speed
- HiDream-I1-Fast can generate images in just 16 steps, suitable for scenarios requiring real-time iteration
cfg parameter to 1.0 during sampling. We have noted the corresponding parameter settings in the relevant workflows.
Model Installation
The following model files are common files that we will use. Please click on the corresponding links to download and save them according to the model file save location. We will guide you to download the corresponding diffusion models in the corresponding workflows. text_encoders:- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors This model has been used in many workflows, you may have already downloaded this file.
- llama_3.1_8b_instruct_fp8_scaled.safetensors
- ae.safetensors This is Flux’s VAE model, if you have used Flux’s workflow before, you may have already downloaded this file.
HiDream-I1 Full Version Workflow
Run on Comfy Cloud
1. Model File Download
Please select the appropriate version based on your hardware. Click the link and download the corresponding model file to save it to theComfyUI/models/diffusion_models/ folder.
- FP8 version: hidream_i1_full_fp8.safetensors requires more than 16GB of VRAM
- Full version: hidream_i1_full_f16.safetensors requires more than 27GB of VRAM
2. Workflow File Download
Please download the image below and drag it into ComfyUI to load the corresponding workflow
3. Complete the Workflow Step by Step
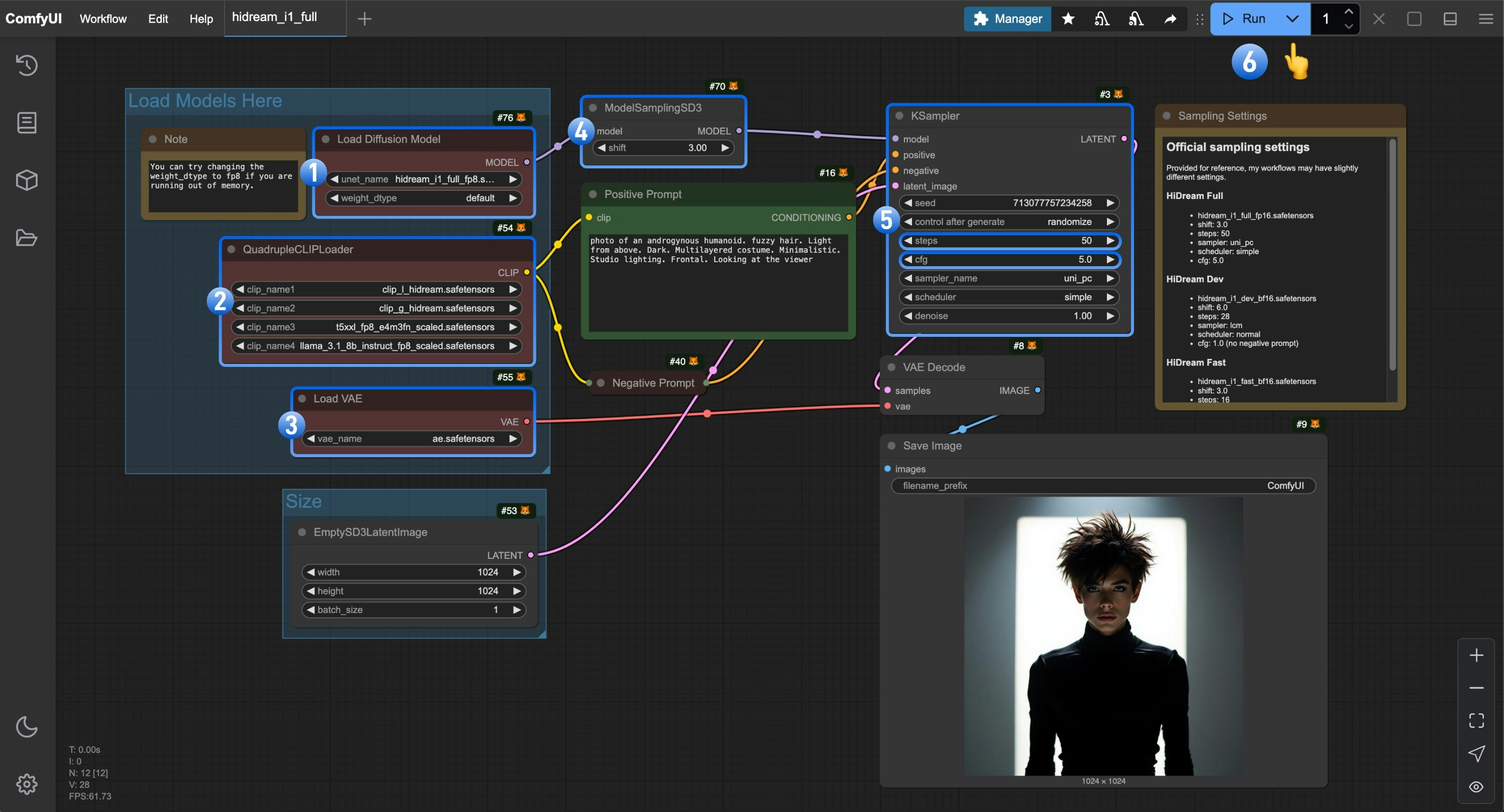
- Make sure the
Load Diffusion Modelnode is using thehidream_i1_full_fp8.safetensorsfile - Make sure the four corresponding text encoders in
QuadrupleCLIPLoaderare loaded correctly- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensors
- Make sure the
Load VAEnode is using theae.safetensorsfile - For the full version, you need to set the
shiftparameter inModelSamplingSD3to3.0 - For the
Ksamplernode, you need to make the following settings- Set
stepsto50 - Set
cfgto5.0 - (Optional) Set
samplertolcm - (Optional) Set
schedulertonormal
- Set
- Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute the image generation
HiDream-I1 Dev Version Workflow
Run on Comfy Cloud
1. Model File Download
Please select the appropriate version based on your hardware, click the link and download the corresponding model file to save to theComfyUI/models/diffusion_models/ folder.
- FP8 version: hidream_i1_dev_fp8.safetensors requires more than 16GB of VRAM
- Full version: hidream_i1_dev_bf16.safetensors requires more than 27GB of VRAM
2. Workflow File Download
Please download the image below and drag it into ComfyUI to load the corresponding workflow
3. Complete the Workflow Step by Step
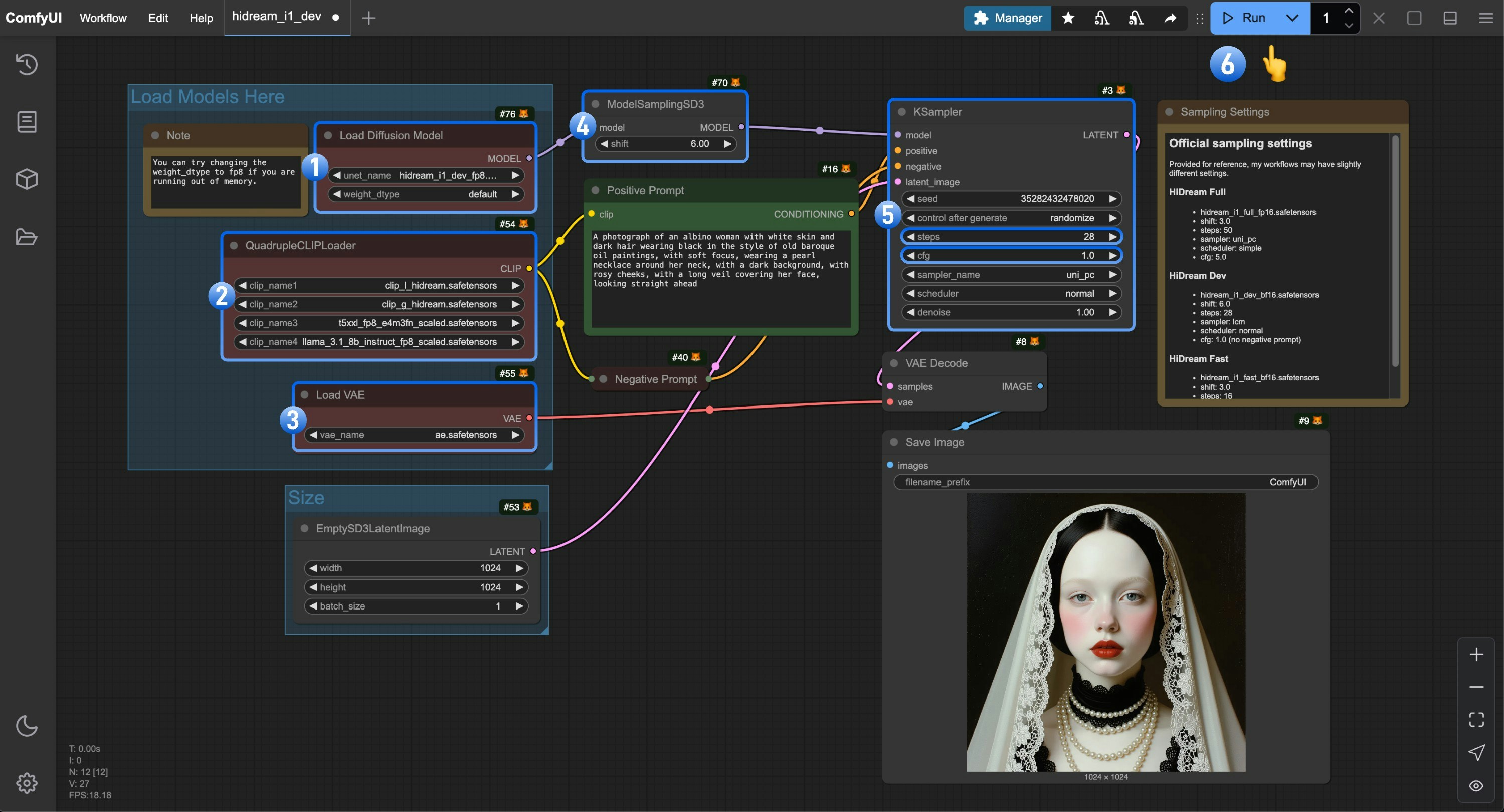
- Make sure the
Load Diffusion Modelnode is using thehidream_i1_dev_fp8.safetensorsfile - Make sure the four corresponding text encoders in
QuadrupleCLIPLoaderare loaded correctly- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensors
- Make sure the
Load VAEnode is using theae.safetensorsfile - For the dev version, you need to set the
shiftparameter inModelSamplingSD3to6.0 - For the
Ksamplernode, you need to make the following settings- Set
stepsto28 - (Important) Set
cfgto1.0 - (Optional) Set
samplertolcm - (Optional) Set
schedulertonormal
- Set
- Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute the image generation
HiDream-I1 Fast Version Workflow
Run on Comfy Cloud
1. Model File Download
Please select the appropriate version based on your hardware, click the link and download the corresponding model file to save to theComfyUI/models/diffusion_models/ folder.
- FP8 version: hidream_i1_fast_fp8.safetensors requires more than 16GB of VRAM
- Full version: hidream_i1_fast_bf16.safetensors requires more than 27GB of VRAM
2. Workflow File Download
Please download the image below and drag it into ComfyUI to load the corresponding workflow
3. Complete the Workflow Step by Step
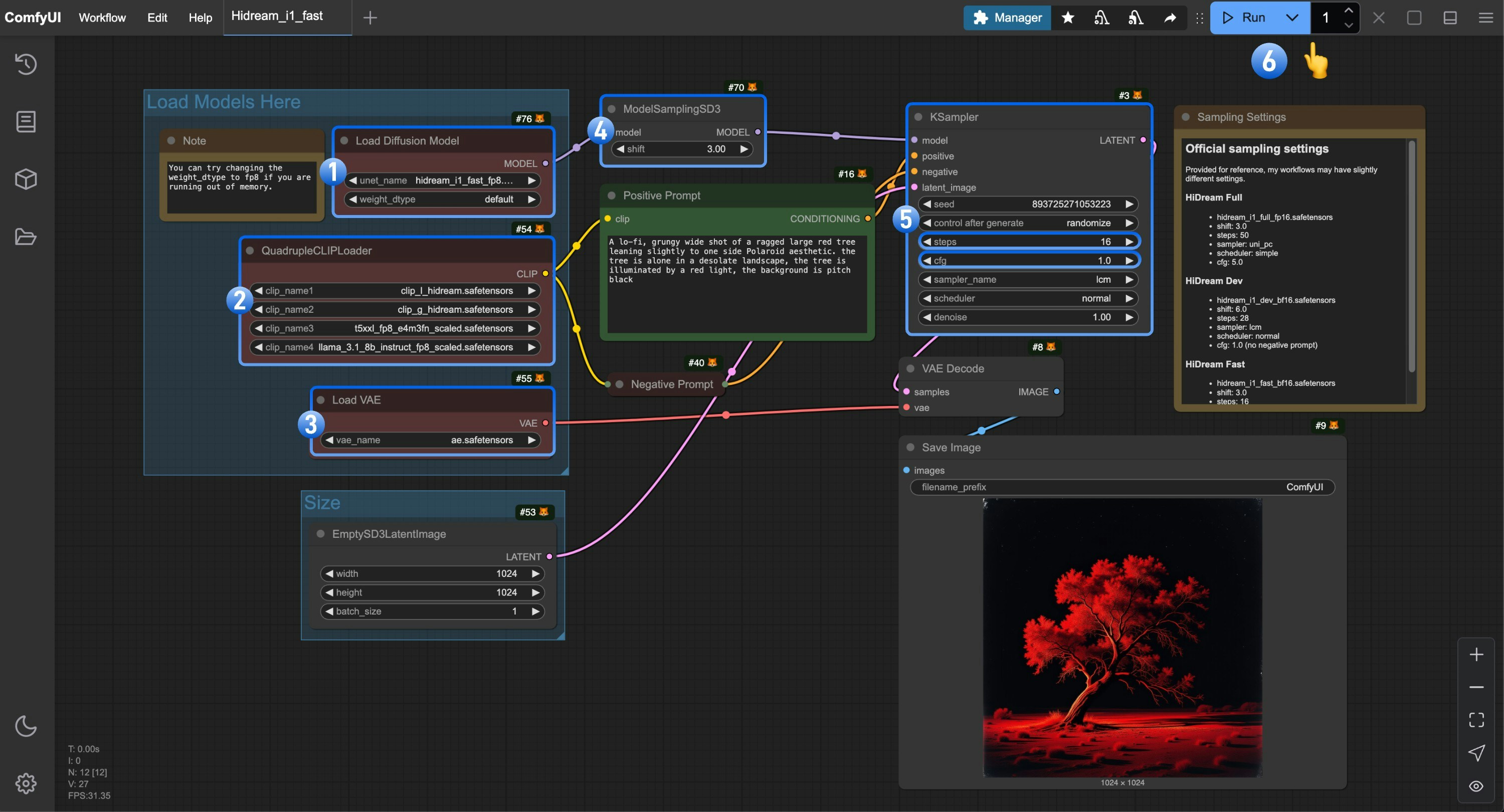
- Make sure the
Load Diffusion Modelnode is using thehidream_i1_fast_fp8.safetensorsfile - Make sure the four corresponding text encoders in
QuadrupleCLIPLoaderare loaded correctly- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensors
- Make sure the
Load VAEnode is using theae.safetensorsfile - For the fast version, you need to set the
shiftparameter inModelSamplingSD3to3.0 - For the
Ksamplernode, you need to make the following settings- Set
stepsto16 - (Important) Set
cfgto1.0 - (Optional) Set
samplertolcm - (Optional) Set
schedulertonormal
- Set
- Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute the image generation
Other Related Resources
GGUF Version Models
You need to use the “Unet Loader (GGUF)” node in City96’s ComfyUI-GGUF to replace the “Load Diffusion Model” node.NF4 Version Models
- HiDream-I1-nf4
- Use the ComfyUI-HiDream-Sampler node to use the NF4 version model.