OpenPose について
OpenPose は、カーネギーメロン大学(CMU)が開発したオープンソースのリアルタイム多人物ポーズ推定システムであり、コンピュータビジョン分野における重要な技術的ブレイクスルーです。このシステムは、1枚の画像内に複数の人物を同時に検出し、以下の情報を抽出できます:- 人体の骨格構造:頭部、肩、肘、手首、股関節、膝、足首など、合計18個のキーポイント
- 顔の表情:微細な表情や顔の輪郭を捉えるための70個の顔面キーポイント
- 手の詳細:指の位置やジェスチャーを正確に表現するための21個の手のキーポイント
- 足の姿勢:立位の姿勢や動作の詳細を記録する6個の足のキーポイント

特に Stable Diffusion 1.5 シリーズの初期モデルでは、OpenPose によって生成された骨格マップを用いることで、人物の動作・四肢・表情の歪みといった問題を効果的に回避できます。
ComfyUI における2パス Pose ControlNet 使用例
1. Pose ControlNet ワークフローの素材
以下のワークフローアイコン画像をダウンロードし、ComfyUI へドラッグ&ドロップすることで、ワークフローを読み込むことができます: 以下の画像をダウンロードしてください。この画像を後続の入力として使用します:
以下の画像をダウンロードしてください。この画像を後続の入力として使用します:
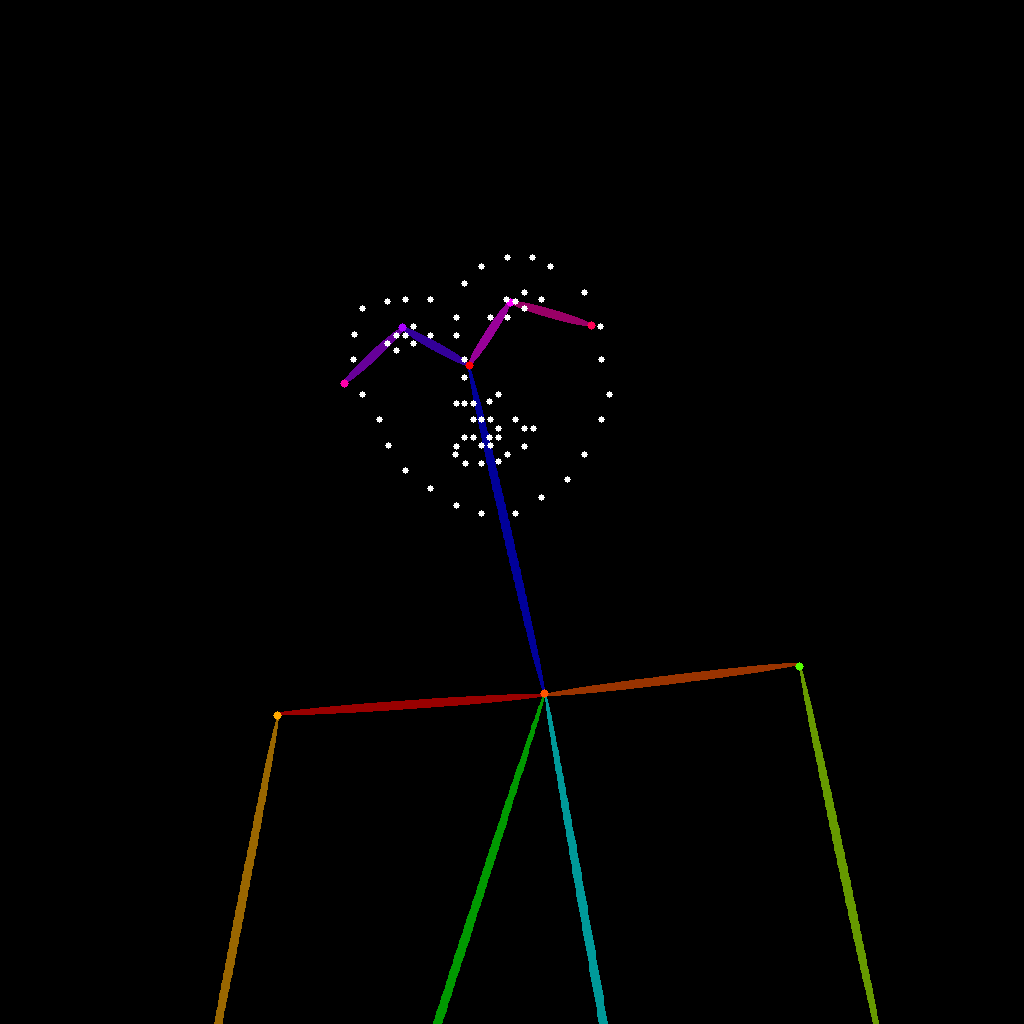
2. 手動によるモデルのインストール
ネットワーク環境によっては、対応するモデルの自動ダウンロードが失敗する場合があります。その場合は、以下のモデルを手動でダウンロードし、指定されたディレクトリに配置してください:
- control_v11p_sd15_openpose_fp16.safetensors
- majicmixRealistic_v7.safetensors
- japaneseStyleRealistic_v20.safetensors
- vae-ft-mse-840000-ema-pruned.safetensors
3. ワークフロー実行のステップ・バイ・ステップ手順
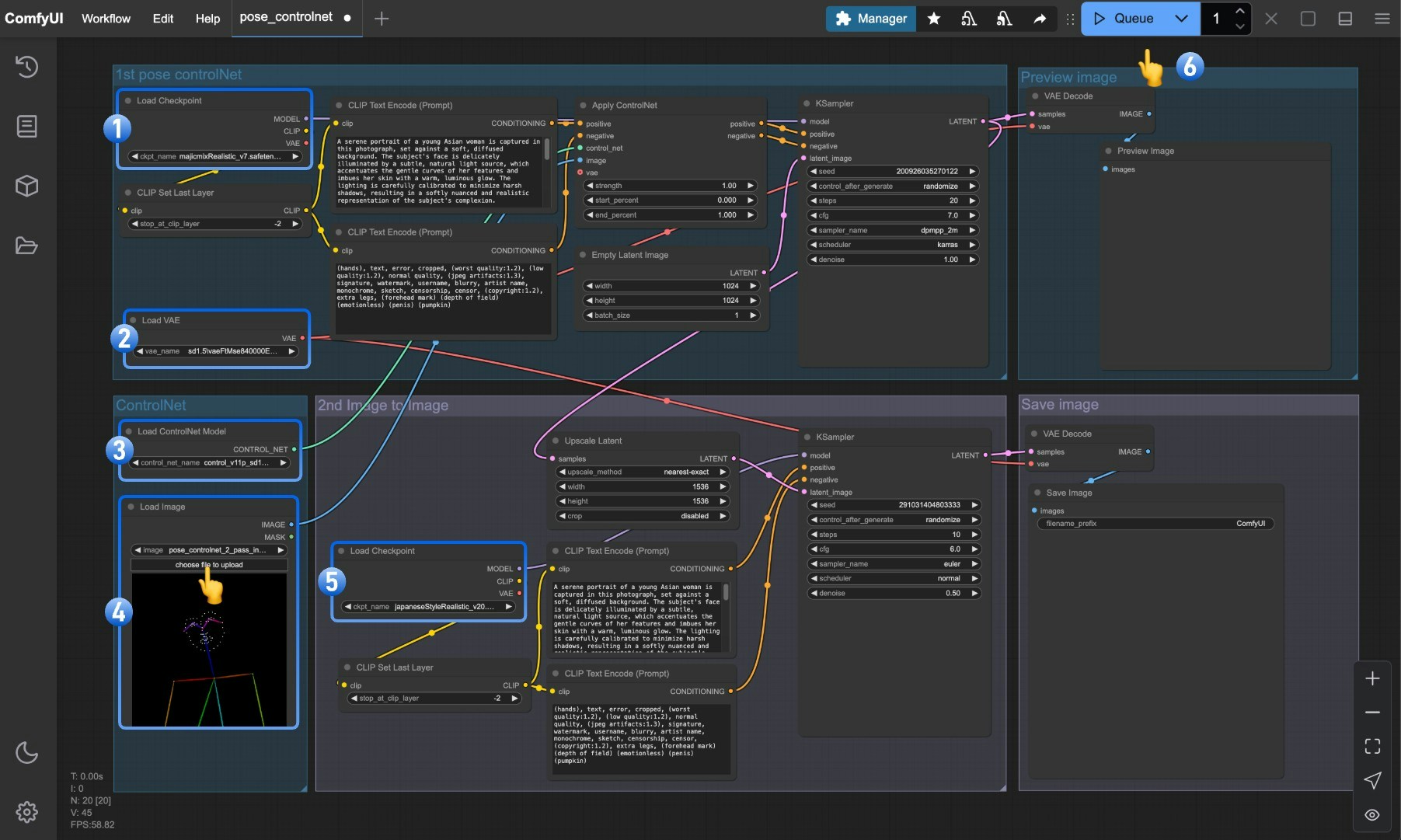
Load Checkpointノードが majicmixRealistic_v7.safetensors を正常に読み込めることを確認しますLoad VAEノードが vae-ft-mse-840000-ema-pruned.safetensors を正常に読み込めることを確認しますLoad ControlNet Modelノードが control_v11p_sd15_openpose_fp16.safetensors を正常に読み込めることを確認しますLoad Imageノード内の「選択」ボタンをクリックし、前述のポーズ入力画像をアップロードするか、独自の OpenPose 骨格マップを使用しますLoad Checkpointノードが japaneseStyleRealistic_v20.safetensors を正常に読み込めることを確認しますQueueボタンをクリックするか、ショートカットキーCtrl (cmd) + Enterを押して画像生成を実行します
Pose ControlNet 2パスワークフローの解説
本ワークフローでは、画像生成プロセスを2つのフェーズに分割する「2パス生成(2-pass generation)」方式を採用しています。第1フェーズ:基本ポーズ画像の生成
第1フェーズでは、majicmixRealistic_v7 モデルと Pose ControlNet を組み合わせて、人物の基本的なポーズ画像を生成します:Load Checkpointノードを用いて、まず majicmixRealistic_v7 モデルを読み込みますLoad ControlNet Modelノードを用いて、ポーズ制御用のモデルを読み込みます- 入力されたポーズ画像を
Apply ControlNetノードに入力し、正のプロンプト条件および負のプロンプト条件と統合します - 最初の
KSamplerノード(通常は20〜30ステップ)で、基本的な人物ポーズ画像を生成します VAE Decodeを通じて、第1フェーズのピクセル空間画像を取得します
第2フェーズ:スタイル最適化とディテール強化
第2フェーズでは、第1フェーズの出力画像を参照として、japaneseStyleRealistic_v20 モデルを用いてスタイル化およびディテールの強化を行います:- 第1フェーズで生成された画像を
Upscale latentノードで処理し、より高解像度の潜在空間(latent space)を作成します - 2つ目の
Load Checkpointノードで、ディテールとスタイルに特化した japaneseStyleRealistic_v20 モデルを読み込みます - 2つ目の
KSamplerノードでは、低めのdenoise強度(通常は0.4〜0.6)を用いて精緻化処理を行い、第1フェーズで得られた基本構造を維持します - 最後に、2つ目の
VAE DecodeおよびSave Imageノードを通じて、高品質かつ高解像度の画像を出力します
2パス画像生成のメリット
単一パス(シングルパス)生成と比較して、2パス画像生成方式には以下のようなメリットがあります:- 高解像度対応:2パス処理により、単一パス生成では実現困難な高解像度画像の生成が可能になります
- スタイルの融合:異なるモデルの長所を組み合わせることが可能で、たとえば第1フェーズでリアリスティックなモデルを、第2フェーズでスタイライズされたモデルを活用できます
- 優れたディテール表現:第2フェーズでは、全体構造を気にすることなく、ディテールの最適化に集中できます
- 精密な制御:ポーズ制御は第1フェーズで完了するため、第2フェーズではスタイルやディテールの洗練に専念できます
- GPU負荷の軽減:2回に分けて生成することで、限られたGPUリソースでも高品質な大サイズ画像を生成できます