- 핵심 아키텍처: Sora와 유사한 DiT(Diffusion Transformer) 아키텍처를 사용하며, 텍스트, 이미지, 모션 정보를 효과적으로 융합해 생성된 비디오 프레임 간의 일관성, 품질 및 정렬성을 향상시킵니다. 통합된 풀 어텐션 메커니즘은 다중 뷰 카메라 전환을 가능하게 하면서도 주제의 일관성을 보장합니다.
- 3D VAE: 맞춤형 3D VAE는 비디오를 압축된 잠재공간으로 변환해 이미지-투-비디오 생성을 더욱 효율적으로 만듭니다.
- 우수한 이미지-비디오-텍스트 정렬성: 이미지와 비디오 생성 모두에 뛰어난 MLLM 텍스트 인코더를 활용해 텍스트 지침을 더 잘 따르고, 세부사항을 포착하며 복잡한 추론을 수행합니다.
모든 워크플로우에 공통되는 모델
다음 모델들은 텍스트-투-비디오와 이미지-투-비디오 워크플로우 모두에 사용됩니다. 아래 모델들을 다운로드하여 지정된 디렉토리에 저장해주세요: 저장 위치:훈위안 텍스트-투-비디오 워크플로우
훈위안 텍스트-투-비디오는 2024년 12월에 오픈소스화되었으며, 중국어와 영어로 된 자연어 설명을 통해 5초짜리 짧은 비디오 생성을 지원합니다.1. 워크플로우
아래 이미지를 다운로드해 ComfyUI로 드래그하여 워크플로우를 로드하세요:
2. 수동 모델 설치
hunyuan_video_t2v_720p_bf16.safetensors를 다운로드해ComfyUI/models/diffusion_models 폴더에 저장하세요.
다음 모델 파일들이 올바른 위치에 있는지 확인하세요:
3. 워크플로우 실행 단계
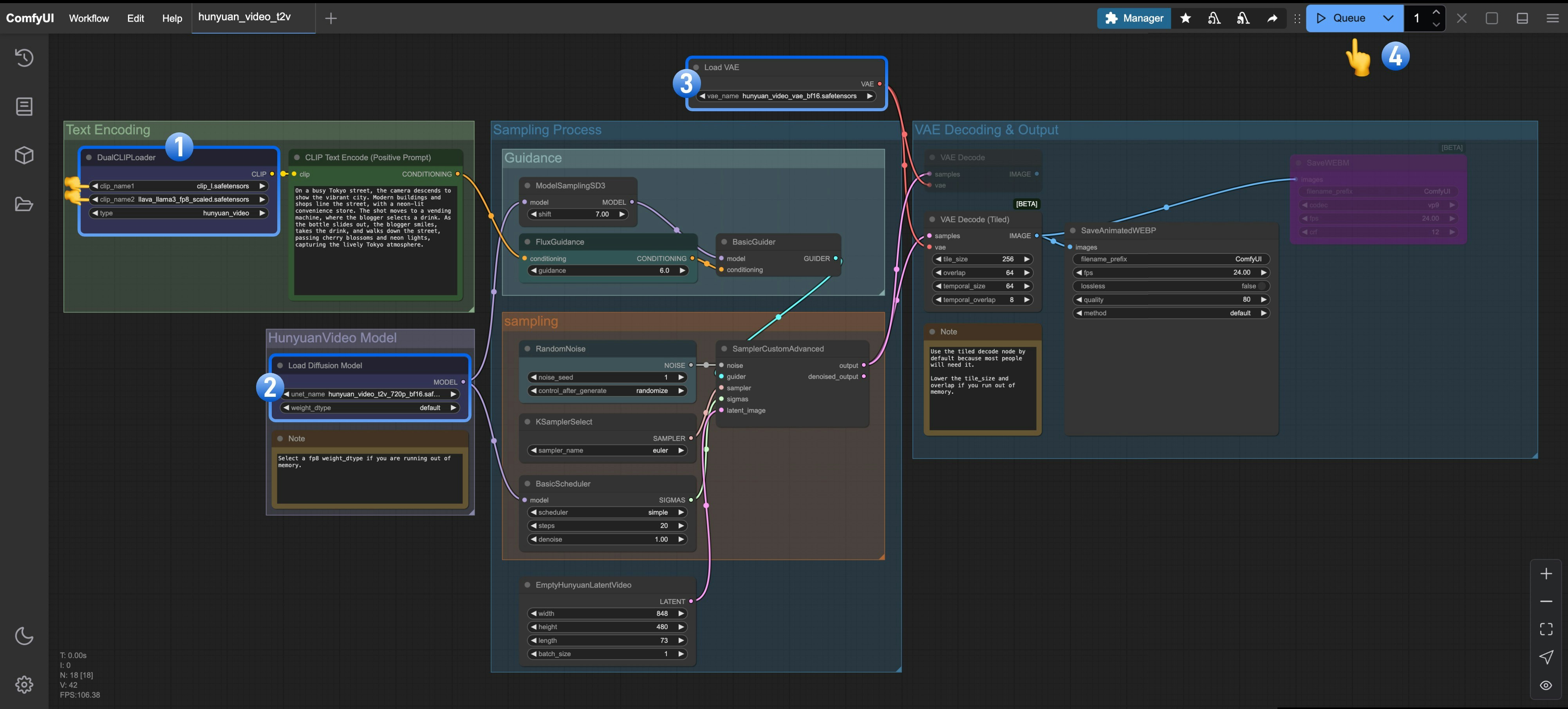
DualCLIPLoader노드가 다음 모델을 로드했는지 확인하세요:- clip_name1: clip_l.safetensors
- clip_name2: llava_llama3_fp8_scaled.safetensors
Load Diffusion Model노드가hunyuan_video_t2v_720p_bf16.safetensors를 로드했는지 확인하세요.Load VAE노드가hunyuan_video_vae_bf16.safetensors를 로드했는지 확인하세요.Queue버튼을 클릭하거나 단축키Ctrl(cmd) + Enter를 사용해 워크플로우를 실행하세요.
훈위안 이미지-투-비디오 워크플로우
훈위안 이미지-투-비디오 모델은 2025년 3월 6일에 훈위안비디오 프레임워크를 기반으로 오픈소스화되었습니다. 이 모델은 정지된 이미지를 부드럽고 고품질의 비디오로 변환하며, 머리카락 성장, 객체 변형 등 특별한 비디오 효과를 맞춤화하기 위한 LoRA 학습 코드도 제공합니다. 현재 훈위안 이미지-투-비디오 모델은 두 가지 버전이 있습니다:- v1 “concat”: 더 나은 모션 유연성 대신 이미지 지침에 덜 충실함
- v2 “replace”: v1 다음날 업데이트된 버전으로, 이미지 지침은 더 나아졌지만 v1보다 다소 덜 역동적인 느낌이 있음
v1 “concat”

v2 “replace”

v1과 v2 버전 공통 모델
다음 파일을 다운로드해ComfyUI/models/clip_vision 디렉토리에 저장하세요:
v1 “concat” 이미지-투-비디오 워크플로우
1. 워크플로우 및 자산
아래 워크플로우 이미지를 다운로드해 ComfyUI로 드래그하여 워크플로우를 로드하세요: 아래 이미지를 다운로드해 이미지-투-비디오 생성의 시작 프레임으로 사용하세요:
아래 이미지를 다운로드해 이미지-투-비디오 생성의 시작 프레임으로 사용하세요:

2. 관련 모델 수동 설치
다음 모델 파일들이 올바른 위치에 있는지 확인하세요:3. 워크플로우 실행 단계
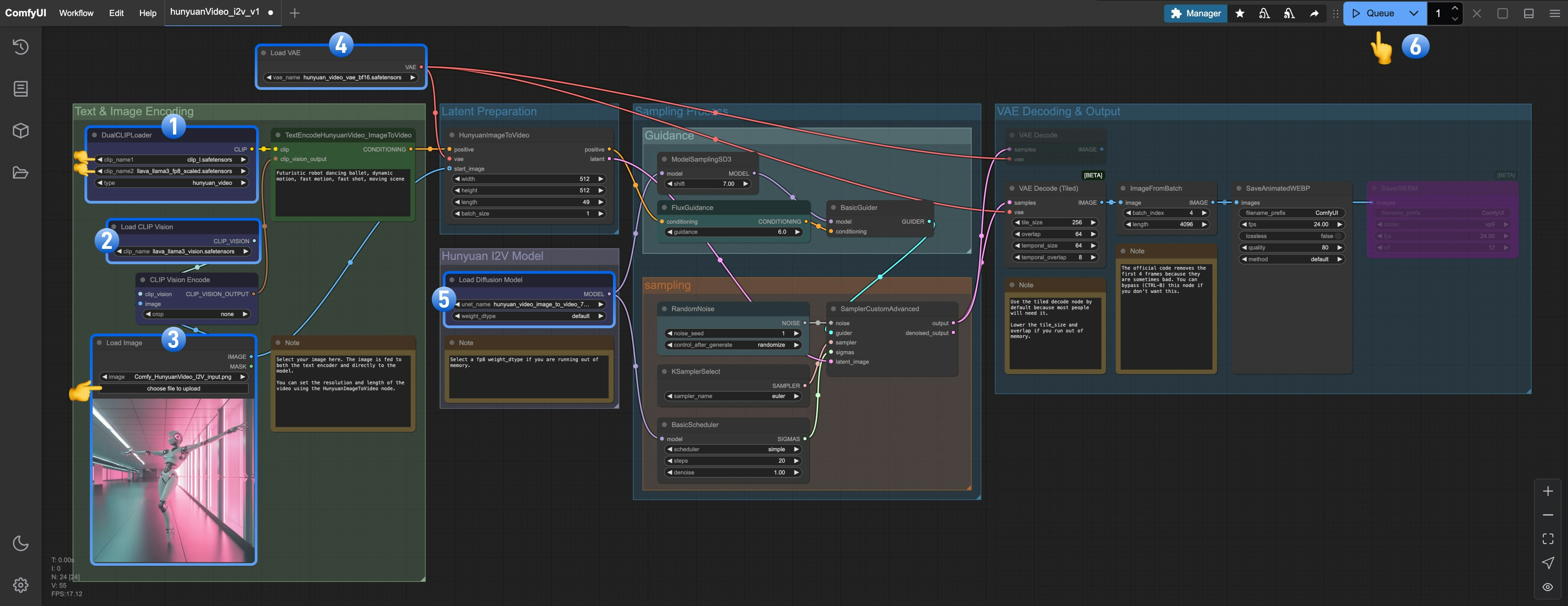
DualCLIPLoader가 다음 모델을 로드했는지 확인하세요:- clip_name1: clip_l.safetensors
- clip_name2: llava_llama3_fp8_scaled.safetensors
Load CLIP Vision가llava_llama3_vision.safetensors를 로드했는지 확인하세요.Load Image Model가hunyuan_video_image_to_video_720p_bf16.safetensors를 로드했는지 확인하세요.Load VAE가vae_name: hunyuan_video_vae_bf16.safetensors를 로드했는지 확인하세요.Load Diffusion Model가hunyuan_video_image_to_video_720p_bf16.safetensors를 로드했는지 확인하세요.Queue버튼을 클릭하거나 단축키Ctrl(cmd) + Enter를 사용해 워크플로우를 실행하세요.
v2 “replace” 이미지-투-비디오 워크플로우
v2 워크플로우는 기본적으로 v1 워크플로우와 동일합니다. 다만 replace 모델을 다운로드해Load Diffusion Model 노드에 사용하면 됩니다.
1. 워크플로우 및 자산
아래 워크플로우 이미지를 다운로드해 ComfyUI로 드래그하여 워크플로우를 로드하세요: 아래 이미지를 다운로드해 이미지-투-비디오 생성의 시작 프레임으로 사용하세요:
아래 이미지를 다운로드해 이미지-투-비디오 생성의 시작 프레임으로 사용하세요:

2. 관련 모델 수동 설치
다음 모델 파일들이 올바른 위치에 있는지 확인하세요:3. 워크플로우 실행 단계
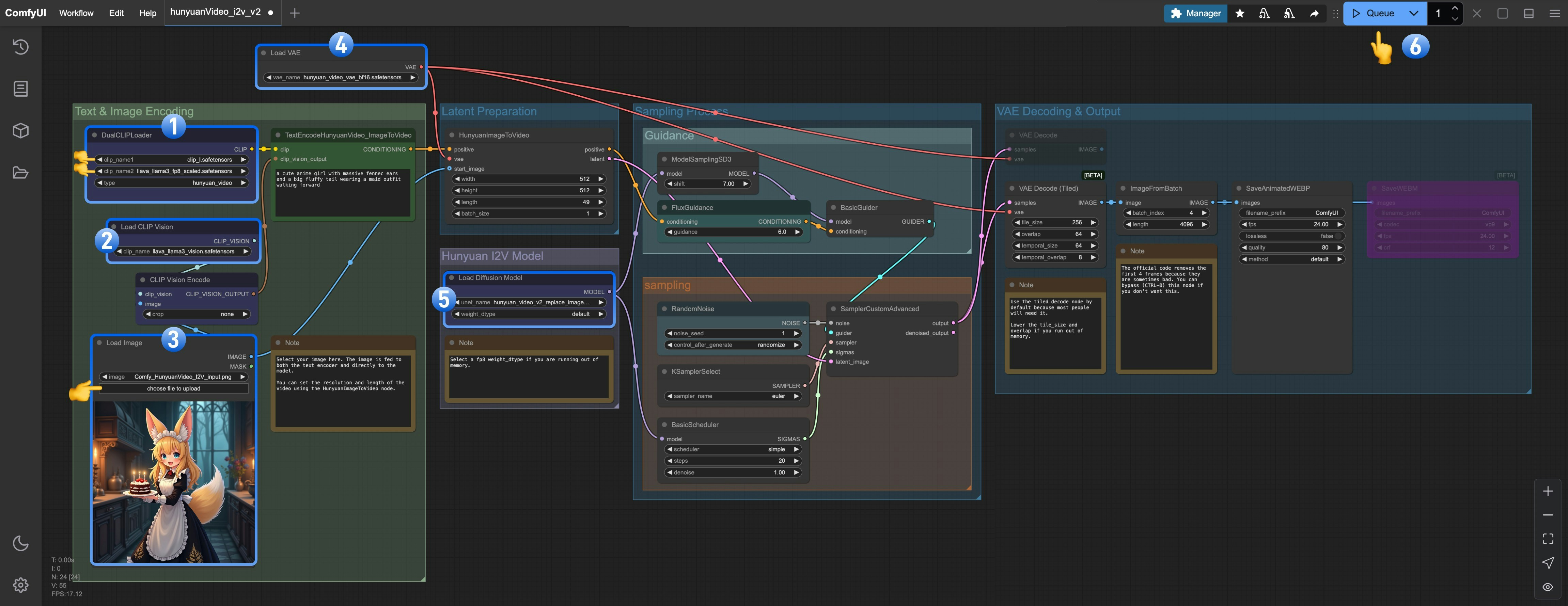
DualCLIPLoader노드가 다음 모델을 로드했는지 확인하세요:- clip_name1: clip_l.safetensors
- clip_name2: llava_llama3_fp8_scaled.safetensors
Load CLIP Vision노드가llava_llama3_vision.safetensors를 로드했는지 확인하세요.Load Image Model노드가hunyuan_video_image_to_video_720p_bf16.safetensors를 로드했는지 확인하세요.Load VAE노드가hunyuan_video_vae_bf16.safetensors를 로드했는지 확인하세요.Load Diffusion Model노드가hunyuan_video_v2_replace_image_to_video_720p_bf16.safetensors를 로드했는지 확인하세요.Queue버튼을 클릭하거나 단축키Ctrl(cmd) + Enter를 사용해 워크플로우를 실행하세요.
직접 해보세요
다음은 저희가 제공하는 몇 가지 이미지와 프롬프트입니다. 해당 콘텐츠를 참고하거나 조정해 자신만의 비디오를 만들어보세요.


