- 高精度なテキスト編集:Qwen-Image-Edit は中国語および英語のバイリンガルテキスト編集をサポートしており、画像内のテキストを直接追加・削除・修正できます。この際、元のテキストのサイズ、フォント、スタイルを保持したまま編集が可能です。
- 意味/外観の二重編集:Qwen-Image-Edit は、低レベルの視覚的外観編集(例:スタイル転送、要素の追加/削除/変更など)だけでなく、高レベルの視覚的意味編集(例:IPキャラクター作成、物体の回転など)もサポートします。
- 多様なベンチマークにおける優れた性能:複数の公開ベンチマークでの評価結果によると、Qwen-Image-Edit は画像編集タスクにおいてSOTA(State-of-the-Art)の性能を達成しており、強力な画像生成基盤モデルとして位置付けられています。
ComfyOrg Qwen-Image-Edit ライブ配信(録画)
Qwen-Image-Edit ComfyUI ネイティブワークフローの例
1. ワークフローファイル
ComfyUI を更新後、テンプレートからワークフローファイルを取得するか、下記のワークフローを ComfyUI へドラッグ&ドロップして読み込むことができます。
JSON形式ワークフローをダウンロード
ComfyUI Cloud 上で実行
以下の画像を入力画像としてダウンロードしてください。
2. モデルのダウンロード
すべてのモデルは、Comfy-Org/Qwen-Image_ComfyUI または Comfy-Org/Qwen-Image-Edit_ComfyUI から入手できます。 Diffusion モデル LoRA テキストエンコーダ VAE モデルの保存場所3. ワークフローの実行手順
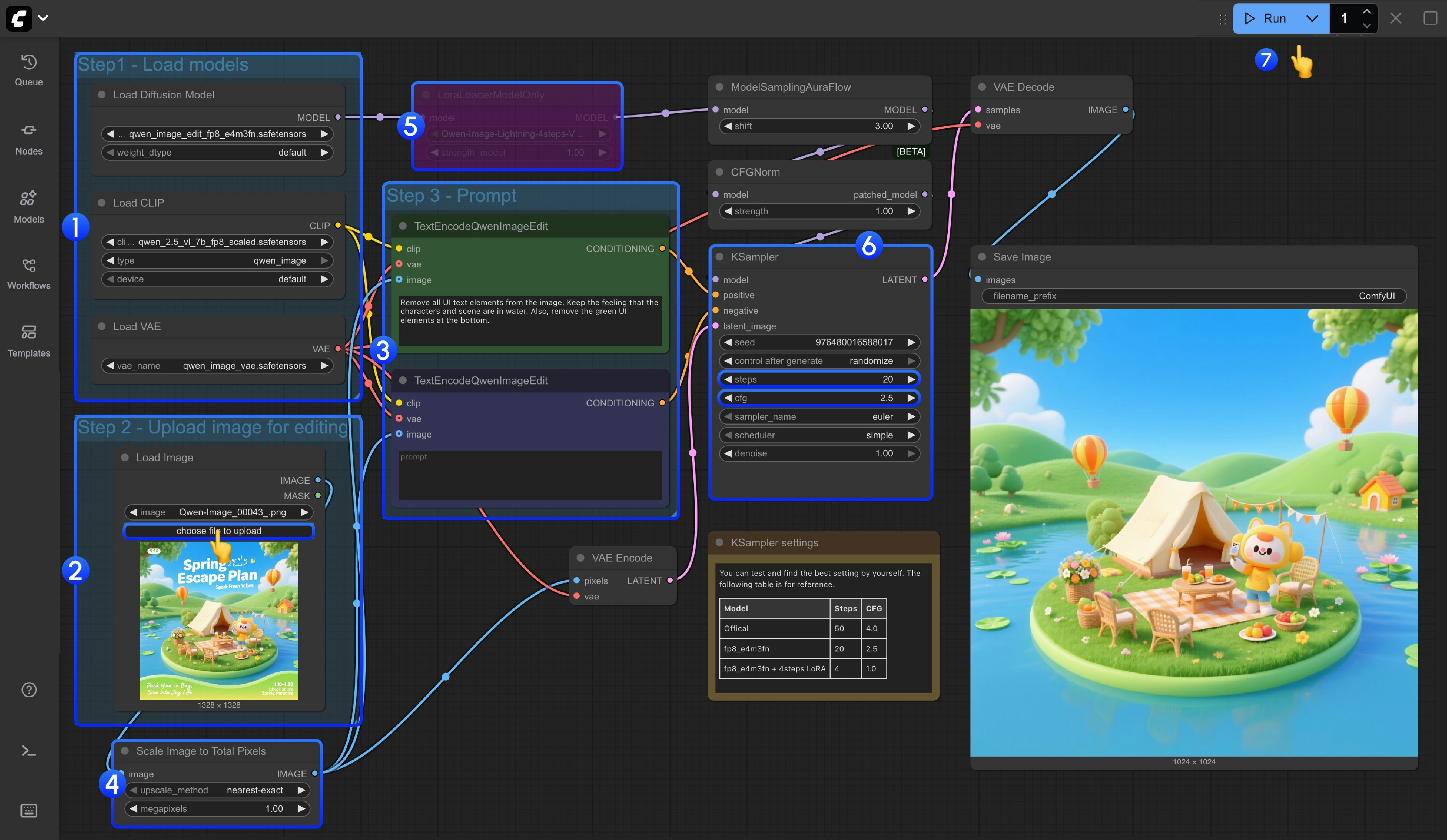
- モデルの読み込み
Load Diffusion Modelノードがqwen_image_edit_fp8_e4m3fn.safetensorsを読み込んでいることを確認してください。Load CLIPノードがqwen_2.5_vl_7b_fp8_scaled.safetensorsを読み込んでいることを確認してください。Load VAEノードがqwen_image_vae.safetensorsを読み込んでいることを確認してください。
- 画像の読み込み
Load Imageノードで編集対象の画像をアップロードしていることを確認してください。
- プロンプトの設定
CLIP Text Encoderノード内でプロンプトを設定してください。
Scale Image to Total Pixelsノードは、入力画像を合計で約100万ピクセルになるよう自動的にスケーリングします。- 主に、2048×2048などの過大な解像度の入力画像によって出力画像の品質が低下することを防ぐための処理です。
- 入力画像のサイズについて十分に把握している場合は、
Ctrl+Bキーでこのノードを無効化(バイパス)できます。
- 画像生成を高速化するために4ステップ版 Lighting LoRA を利用したい場合、
LoraLoaderModelOnlyノードを選択し、Ctrl+Bキーを押して有効化してください。 Ksamplerノードのstepsおよびcfg設定については、ノード直下にメモが追加されています。最適なパラメータ設定を試行する際にご活用ください。Queueボタンをクリックするか、ショートカットキーCtrl(macOSではCmd)+ Enterを押してワークフローを実行してください。