- 優れた多言語テキストレンダリング:英語、中国語、韓国語、日本語など、複数言語での高精度テキスト生成をサポートし、フォントのディテールやレイアウトの一貫性を維持します
- 多様なアートスタイル対応:写真のようなリアリスティックなシーンから印象派の絵画、アニメ風の美意識、ミニマリストデザインまで、さまざまなクリエイティブプロンプトに柔軟に対応します
- Qwen-Image-DiffSynth-ControlNets/model_patches:Canny、Depth、Inpaintモデルを含む
- qwen_image_union_diffsynth_lora.safetensors:Canny、Depth、Pose、Lineart、Softedge、Normal、Openposeをサポートする画像構造制御用LoRA
- InstantX ControlNet:近日公開予定
ComfyOrg Qwen-Imageライブストリーム
ComfyUIにおけるQwen-Image ― Lightning & LoRAs
ComfyUIにおけるQwen-Image ControlNet ― DiffSynth
Qwen-Imageネイティブワークフローの例
Comfy Cloudで実行 本ドキュメントに添付されたワークフローでは、以下の3種類の異なるモデルが使用されています:- Qwen-Imageオリジナルモデル(fp8_e4m3fn)
- 8ステップ高速化版:Qwen-Imageオリジナルモデル(fp8_e4m3fn)+lightx2v製8ステップLoRA
- 蒸留版:Qwen-Image蒸留モデル(fp8_e4m3fn)
GPU:RTX4090D(24GB)
1. ワークフローファイル
ComfyUIを更新後、テンプレートからワークフローファイルを検索するか、以下のワークフローをComfyUIにドラッグ&ドロップして読み込むことができます。
Qwen-Image公式モデル用ワークフロー(JSON形式)をダウンロード
蒸留版蒸留モデル用ワークフロー(JSON形式)をダウンロード
2. モデルのダウンロード
ComfyUIで利用可能なモデル- Qwen-Image_bf16(40.9 GB)
- Qwen-Image_fp8(20.4 GB)
- 蒸留版(非公式、15ステップのみ必要)
- 蒸留版のオリジナル作者は、CFG値1.0で15ステップでの使用を推奨しています。
- テストによると、この蒸留版はCFG値1.0で10ステップでも良好な性能を発揮します。生成したい画像のタイプに応じて、eulerまたはres_multistepを選択できます。
3. ワークフローの操作手順
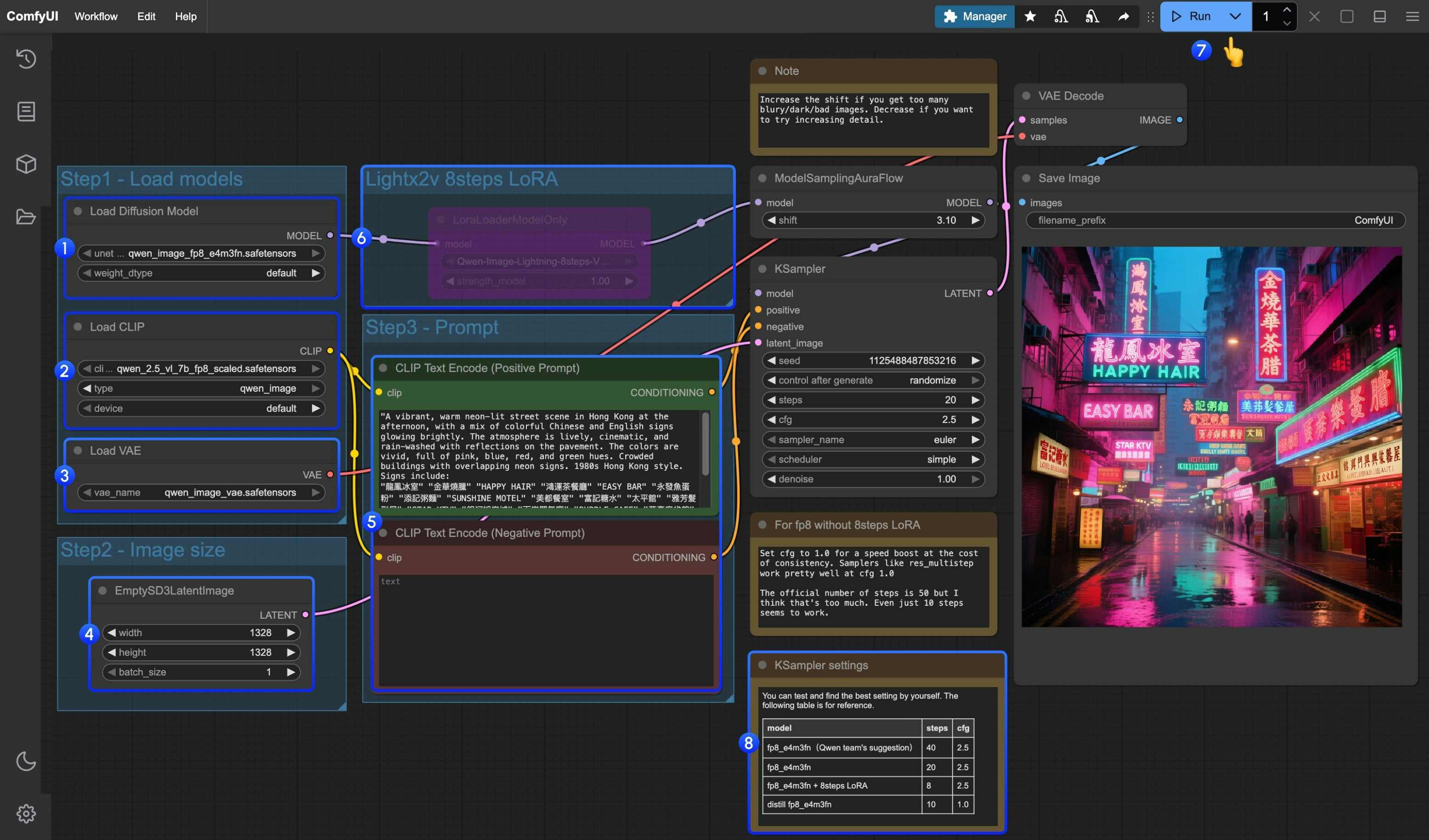
Load Diffusion Modelノードがqwen_image_fp8_e4m3fn.safetensorsを正しく読み込んでいることを確認してくださいLoad CLIPノードがqwen_2.5_vl_7b_fp8_scaled.safetensorsを正しく読み込んでいることを確認してくださいLoad VAEノードがqwen_image_vae.safetensorsを正しく読み込んでいることを確認してくださいEmptySD3LatentImageノードの画像サイズ設定が正しいことを確認してくださいCLIP Text Encoderノードでプロンプトを設定してください。現在、少なくとも英語、中国語、韓国語、日本語、イタリア語などがサポートされています- lightx2v製8ステップ高速化LoRAを有効化する場合は、該当ノードを選択し
Ctrl + Bで有効化し、手順8で説明する通りKSamplerの設定を修正してください Queueボタンをクリックするか、ショートカットCtrl(cmd) + Enterでワークフローを実行してください- モデルのバージョンやワークフローに応じて、KSamplerのパラメーターを適切に調整してください
蒸留モデルとlightx2v製8ステップ高速化LoRAは、同時に使用できない可能性があります。両者を組み合わせた動作を確認するために、さまざまな組み合わせを試すことができます。
Qwen Image InstantX ControlNetワークフロー
これはControlNetモデルであるため、通常のControlNetとして使用できます。 Comfy Cloudで実行1. ワークフローおよび入力画像
以下の画像をダウンロードし、ComfyUIにドラッグ&ドロップしてワークフローを読み込んでください
JSON形式ワークフローをダウンロード
以下の画像を入力としてダウンロードしてください
2. モデルのリンク
- InstantX ControlNet
ComfyUI/models/controlnet/フォルダーに保存してください
- Lotus Depthモデル
- vae-ft-mse-840000-ema-pruned.safetensors または任意のSD1.5互換VAE
深度マップの生成には、comfyui_controlnet_auxなどのカスタムノードも使用できます。
3. ワークフローの操作手順
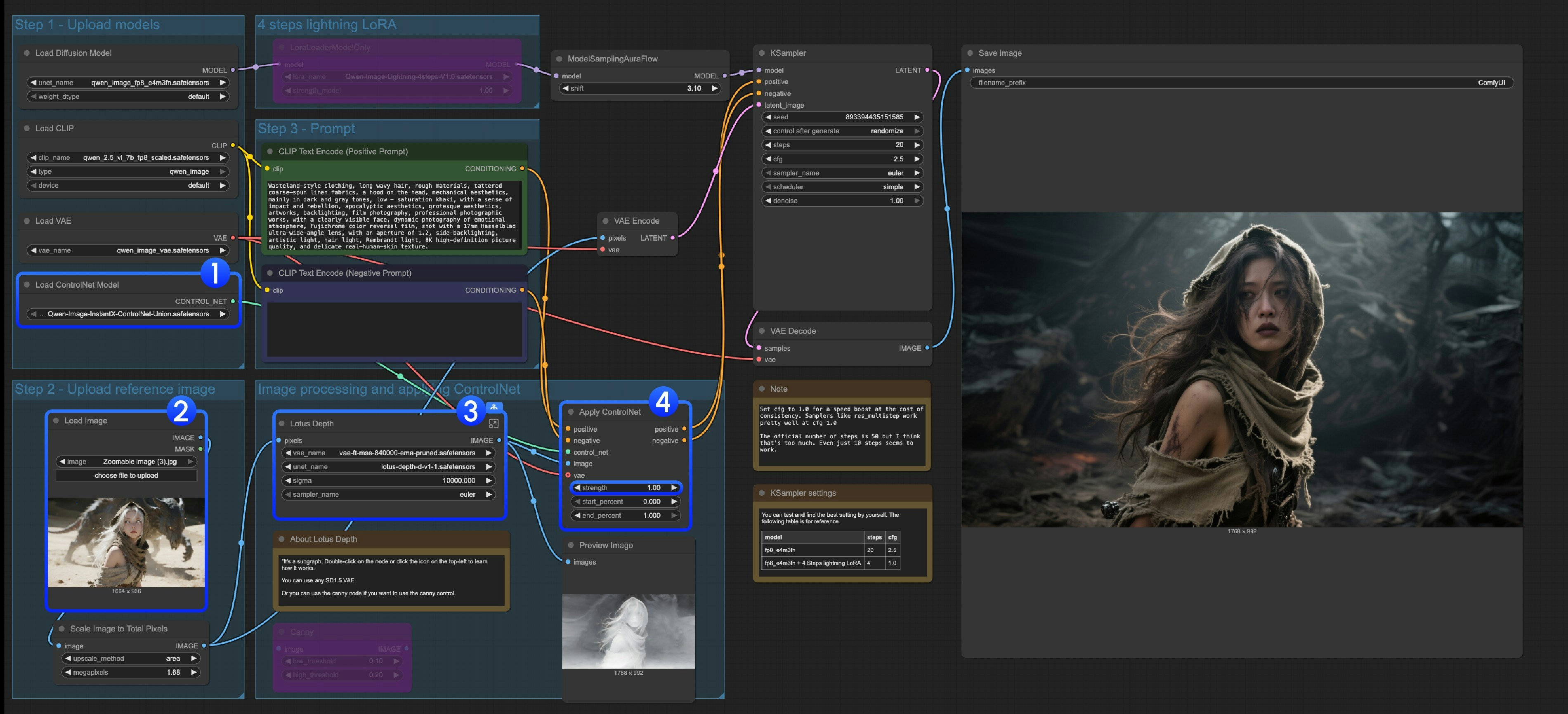
Load ControlNet ModelノードがQwen-Image-InstantX-ControlNet-Union.safetensorsを正しく読み込んでいることを確認してください- 入力画像をアップロードしてください
- このサブグラフはLotus Depthモデルを使用しています。テンプレートからLotus Depthを検索するか、サブグラフを編集して詳細を確認し、すべてのモデルが正しく読み込まれていることを確認してください
Runボタンをクリックするか、ショートカットCtrl(cmd) + Enterでワークフローを実行してください
Qwen Image ControlNet DiffSynth-ControlNetsモデルパッチワークフロー
Comfy Cloudで実行 このモデルは実際にはControlNetではなく、Canny、Depth、Inpaintの3種類の異なる制御モードをサポートする「モデルパッチ」です。 オリジナルモデルのURL:DiffSynth-Studio/Qwen-Image ControlNetComfy Org再ホストURL:Qwen-Image-DiffSynth-ControlNets/model_patches
1. ワークフローおよび入力画像
以下の画像をダウンロードし、ComfyUIにドラッグ&ドロップして対応するワークフローを読み込んでください
JSON形式ワークフローをダウンロード
以下の画像を入力としてダウンロードしてください:
2. モデルのリンク
その他のモデルはQwen-Image基本ワークフローと同一です。以下のモデルのみをダウンロードし、ComfyUI/models/model_patchesフォルダーに保存してください。
- qwen_image_canny_diffsynth_controlnet.safetensors
- qwen_image_depth_diffsynth_controlnet.safetensors
- qwen_image_inpaint_diffsynth_controlnet.safetensors
3. ワークフローの使用方法
現在、diffsynthにはCanny、Depth、Inpaintの3種類のパッチモデルがあります。 ControlNet関連のワークフローを初めて使用する場合、制御用画像は事前にサポートされる画像形式に前処理されなければ、モデルによって認識・使用されない点に注意が必要です。
- Canny:処理済みのCannyエッジ、線画の輪郭
- Depth:空間関係を示す前処理済みの深度マップ
- Inpaint:再描画が必要な領域をマスクで指定する必要があります
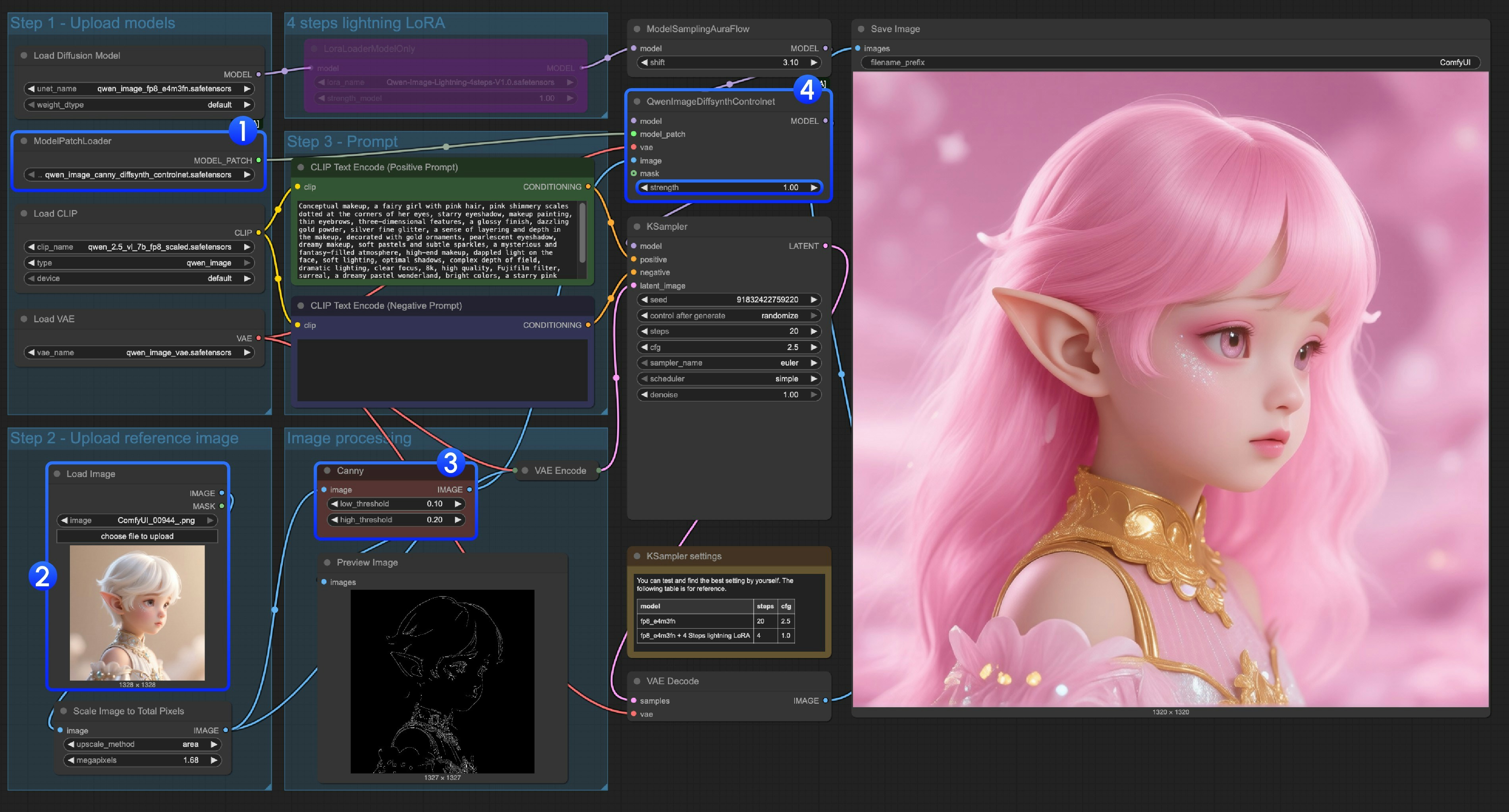
qwen_image_canny_diffsynth_controlnet.safetensorsが正しく読み込まれていることを確認してください- 後続処理のために入力画像をアップロードしてください
- Cannyノードはネイティブの前処理ノードであり、設定したパラメーターに従って入力画像を前処理し、生成を制御します
- 必要に応じて、
QwenImageDiffsynthControlnetノードのstrengthを調整して、線画制御の強度を制御できます Runボタンをクリックするか、ショートカットCtrl(cmd) + Enterでワークフローを実行してください
qwen_image_depth_diffsynth_controlnet.safetensorsを使用する場合は、画像を深度マップに前処理し、「image processing」部分を置き換える必要があります。この用途については、本ドキュメント内のInstantX処理方法を参照してください。その他の部分はCannyモデルの使用方法と同様です。
InpaintモデルのControlNet使用手順
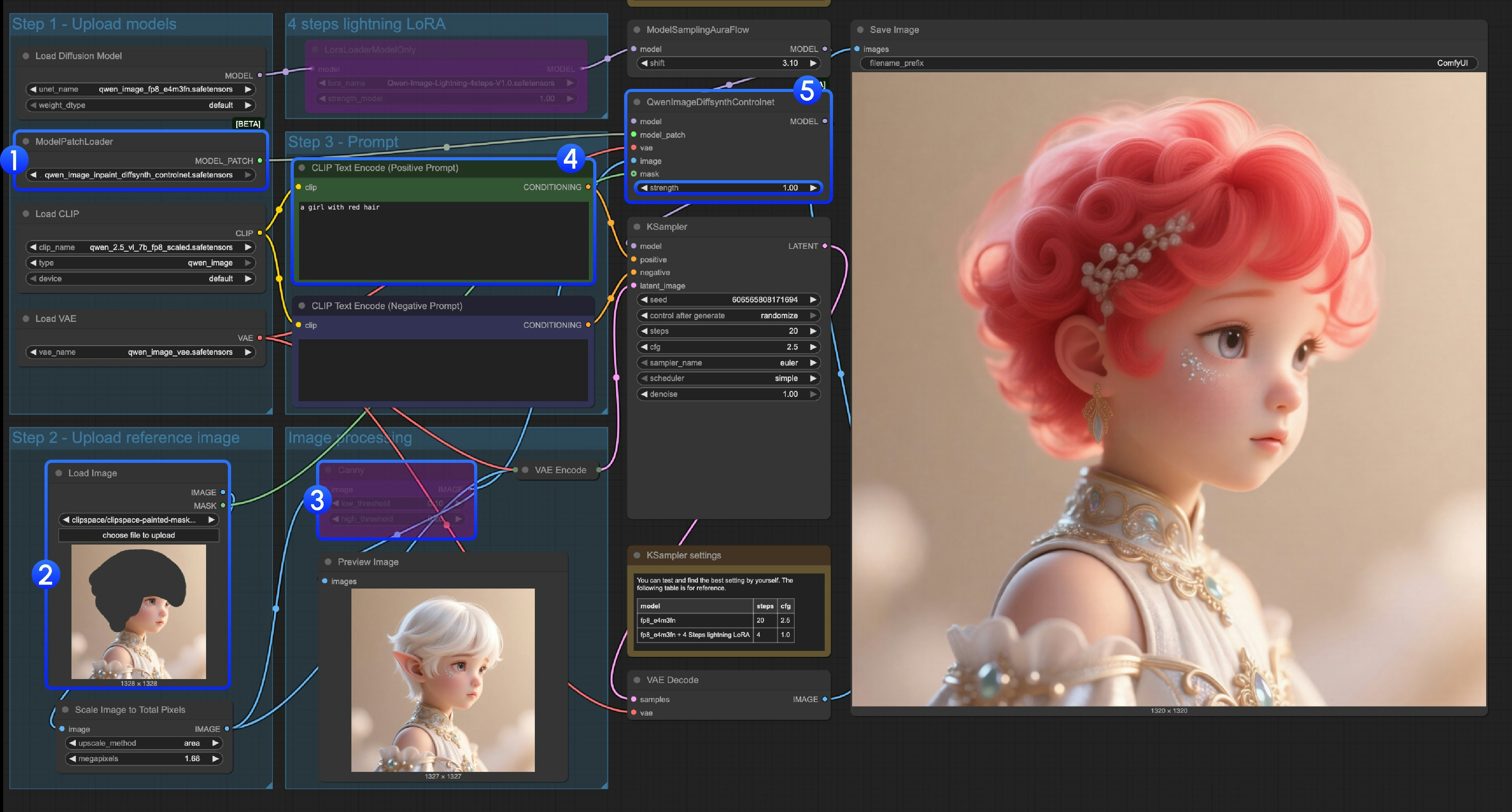
ModelPatchLoaderがqwen_image_inpaint_diffsynth_controlnet.safetensorsを正しく読み込んでいることを確認してください- 画像をアップロードし、マスクエディターでマスクを描画します。対応する
Load Imageノードのmask出力をQwenImageDiffsynthControlnetのmask入力に接続することで、適切なマスクが読み込まれることを保証してください Ctrl-Bショートカットを使用して、ワークフロー内の元のCannyノードをバイパスモードに設定し、Cannyノードによる処理を無効化しますCLIP Text Encoderで、マスク領域を変更したい内容を入力してください- 必要に応じて、
QwenImageDiffsynthControlnetノードのstrengthを調整して、対応する制御強度を制御できます Runボタンをクリックするか、ショートカットCtrl(cmd) + Enterでワークフローを実行してください
Qwen Image Union ControlNet LoRAワークフロー
Comfy Cloudで実行 オリジナルモデルのURL:DiffSynth-Studio/Qwen-Image-In-Context-Control-Union Comfy Org再ホストURL:qwen_image_union_diffsynth_lora.safetensors:Canny、Depth、Pose、Lineart、Softedge、Normal、Openposeをサポートする画像構造制御用LoRA1. ワークフローおよび入力画像
以下の画像をダウンロードし、ComfyUIにドラッグ&ドロップしてワークフローを読み込んでください
JSON形式ワークフローをダウンロード
以下の画像を入力としてダウンロードしてください
2. モデルのリンク
以下のモデルをダウンロードしてください。これはLoRAモデルであるため、ComfyUI/models/loras/フォルダーに保存する必要があります。
- qwen_image_union_diffsynth_lora.safetensors:Canny、Depth、Pose、Lineart、Softedge、Normal、Openposeをサポートする画像構造制御用LoRA
3. ワークフローの操作手順
このモデルは、Canny、Depth、Pose、Lineart、Softedge、Normal、Openposeの制御を統合的にサポートするLoRAです。多くの画像前処理用ネイティブノードが完全には対応していないため、comfyui_controlnet_auxなどのツールを活用して、その他の画像前処理を完了させる必要があります。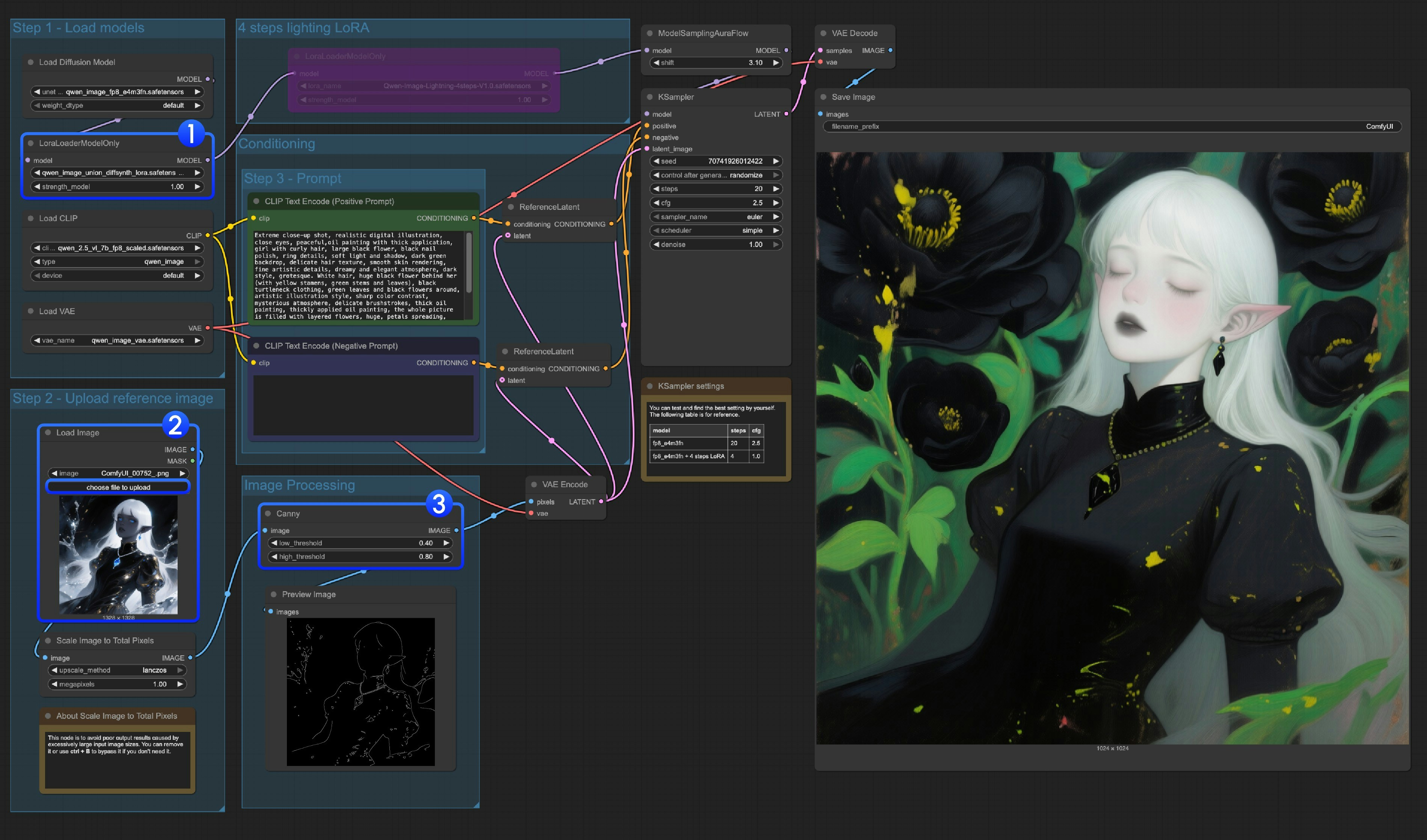
LoraLoaderModelOnlyがqwen_image_union_diffsynth_lora.safetensorsを正しく読み込んでいることを確認してください- 入力画像をアップロードしてください
- 必要に応じて、
Cannyノードのパラメーターを調整できます。入力画像によって最適なパラメーター設定が異なるため、より多くのディテールまたはより少ないディテールを得るために、対応するパラメーター値を調整してみてください Runボタンをクリックするか、ショートカットCtrl(cmd) + Enterでワークフローを実行してください
その他の制御タイプについても、同様に画像処理部分を置き換える必要があります。