- コアアーキテクチャ: Sora と同様の DiT (Diffusion Transformer) アーキテクチャを採用し、テキスト、画像、動作情報を効果的に融合させることで、生成された動画フレーム間の一貫性、品質、整合性を向上させます。統一されたフルアテンション機構により、被写体の一貫性を保ちながらマルチビューのカメラ遷移を実現します。
- 3D VAE: カスタム 3D VAE は動画をコンパクトな潜在空間に圧縮し、画像から動画の生成をより効率的にします。
- 優れた画像・動画・テキストの整合性: 画像と動画生成の両方に優れた MLLM テキストエンコーダーを利用し、テキスト指示への追従、詳細の捕捉、複雑な推論をより良く行います。
すべてのワークフローで共通のモデル
以下のモデルは、テキストから動画および画像から動画の両方のワークフローで使用されます。ダウンロードして、指定されたディレクトリに保存してください: 保存場所:Hunyuan テキストから動画ワークフロー
Hunyuan Text-to-Video は 2024 年 12 月にオープンソース化され、中国語と英語の両方での自然言語記述を通じて 5 秒間のショート動画生成をサポートしています。1. ワークフロー
下の画像をダウンロードし、ComfyUI にドラッグしてワークフローを読み込んでください:
2. モデルの手動インストール
hunyuan_video_t2v_720p_bf16.safetensors をダウンロードし、ComfyUI/models/diffusion_models フォルダに保存してください。
これらのモデルファイルがすべて正しい場所に存在することを確認してください:
3. ワークフローの実行手順
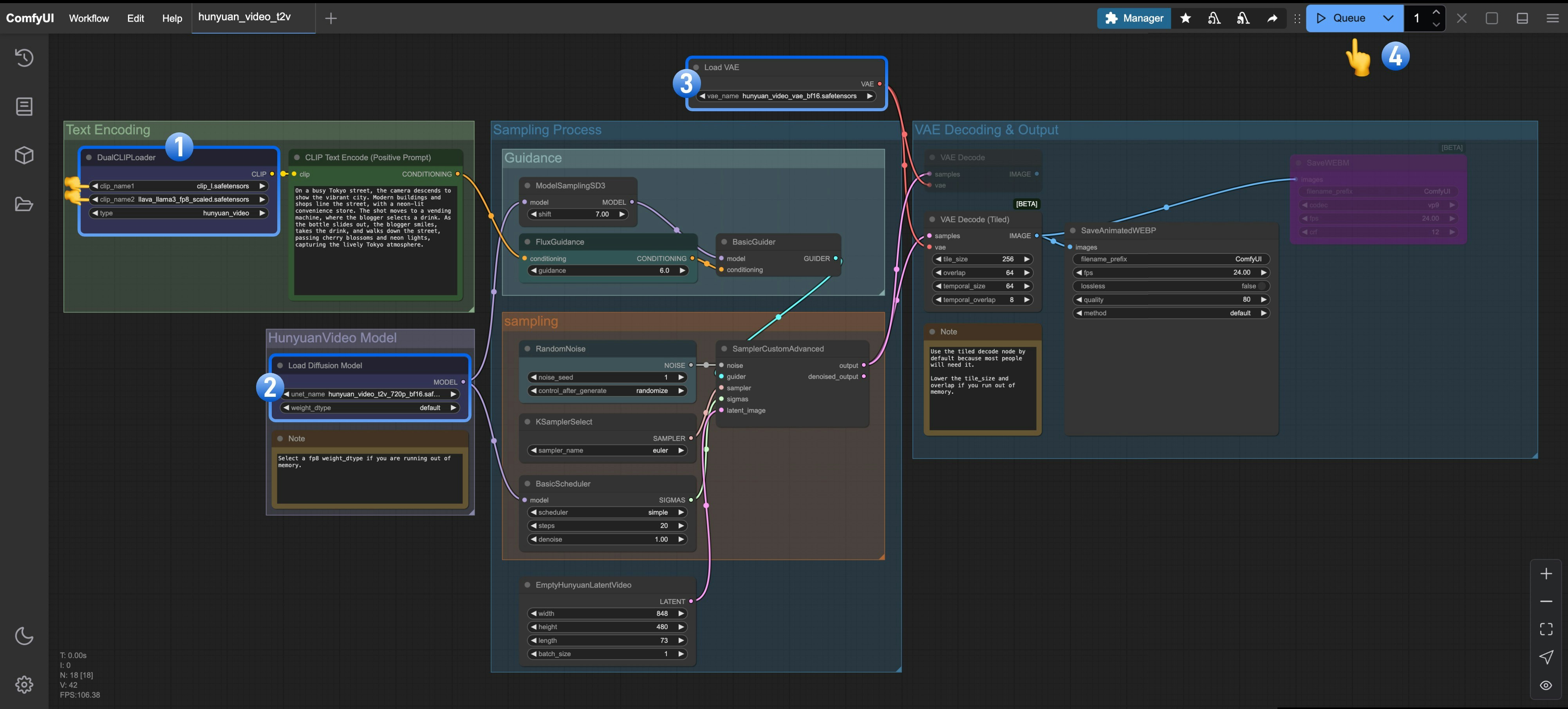
DualCLIPLoaderノードで以下のモデルがロードされていることを確認してください:- clip_name1: clip_l.safetensors
- clip_name2: llava_llama3_fp8_scaled.safetensors
Load Diffusion Modelノードでhunyuan_video_t2v_720p_bf16.safetensorsがロードされていることを確認してくださいLoad VAEノードでhunyuan_video_vae_bf16.safetensorsがロードされていることを確認してくださいQueueボタンをクリックするか、ショートカットCtrl(cmd) + Enterを使用してワークフローを実行します
Hunyuan 画像から動画ワークフロー
Hunyuan Image-to-Video モデルは 2025 年 3 月 6 日にオープンソース化され、HunyuanVideo フレームワークに基づいています。静止画像を滑らかで高品質な動画に変換し、髪の毛の成長や物体の変形などの特別な動画効果をカスタマイズするための LoRA 訓練コードも提供しています。 現在、Hunyuan Image-to-Video モデルには 2 つのバージョンがあります:- v1 “concat”: 動きの流暢さは優れていますが、画像ガイドへの準拠度は低いです
- v2 “replace”: v1 の翌日に更新されたバージョンで、画像ガイドは優れていますが、v1 に比べてダイナミクスが劣るようです
v1”concat”

v2”replace”

v1 および v2 バージョンで共通のモデル
以下のファイルをダウンロードし、ComfyUI/models/clip_vision ディレクトリに保存してください:
V1”concat”画像から動画ワークフロー
1. ワークフローおよびアセット
下のワークフロー画像をダウンロードし、ComfyUI にドラッグしてワークフローを読み込んでください: 下の画像をダウンロードしてください。これは画像から動画生成の起始フレームとして使用します:
下の画像をダウンロードしてください。これは画像から動画生成の起始フレームとして使用します:

2. 関連モデルの手動インストール
これらのモデルファイルがすべて正しい場所に存在することを確認してください:3. ワークフローの実行手順
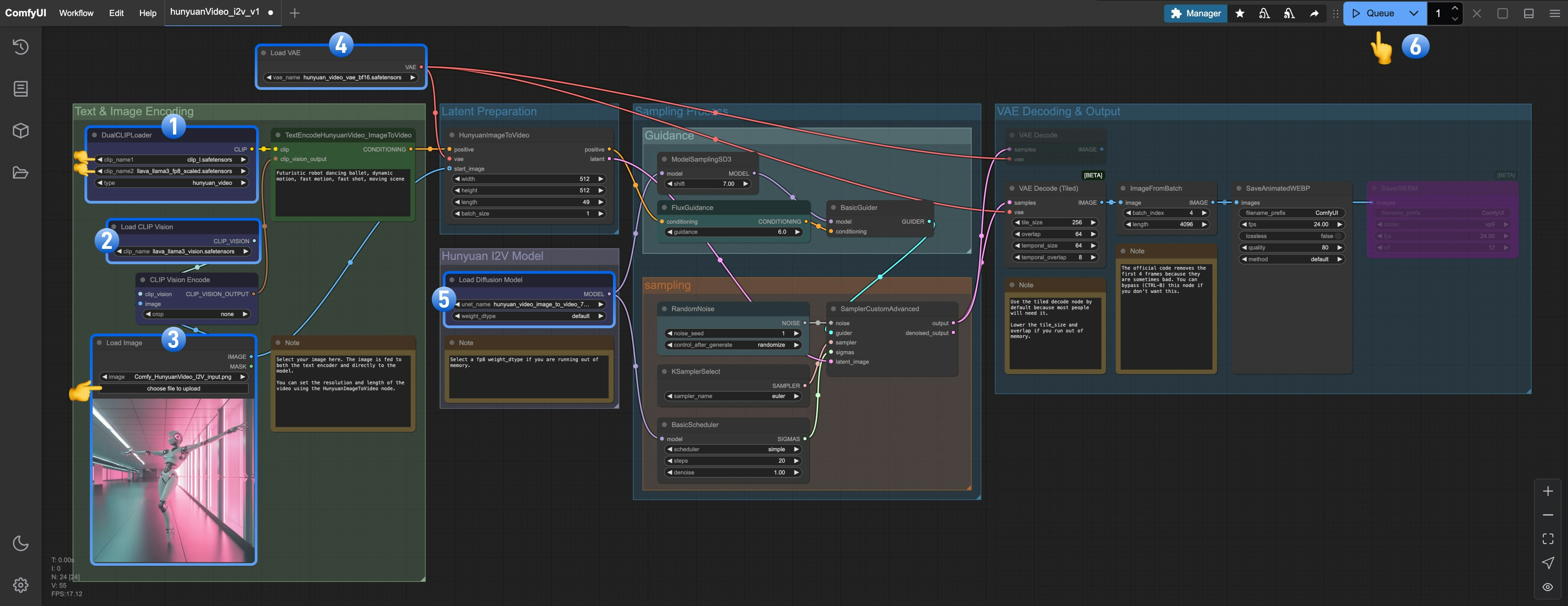
DualCLIPLoaderで以下のモデルがロードされていることを確認してください:- clip_name1: clip_l.safetensors
- clip_name2: llava_llama3_fp8_scaled.safetensors
Load CLIP Visionでllava_llama3_vision.safetensorsがロードされていることを確認してくださいLoad Image Modelでhunyuan_video_image_to_video_720p_bf16.safetensorsがロードされていることを確認してくださいLoad VAEでvae_name: hunyuan_video_vae_bf16.safetensorsがロードされていることを確認してくださいLoad Diffusion Modelでhunyuan_video_image_to_video_720p_bf16.safetensorsがロードされていることを確認してくださいQueueボタンをクリックするか、ショートカットCtrl(cmd) + Enterを使用してワークフローを実行します
v2”replace”画像から動画ワークフロー
v2 ワークフローは本質的に v1 ワークフローと同じです。replace モデルをダウンロードし、Load Diffusion Model ノードで使用するだけです。
1. ワークフローおよびアセット
下のワークフロー画像をダウンロードし、ComfyUI にドラッグしてワークフローを読み込んでください: 下の画像をダウンロードしてください。これは画像から動画生成の起始フレームとして使用します:
下の画像をダウンロードしてください。これは画像から動画生成の起始フレームとして使用します:

2. 関連モデルの手動インストール
これらのモデルファイルがすべて正しい場所に存在することを確認してください:3. ワークフローの実行手順
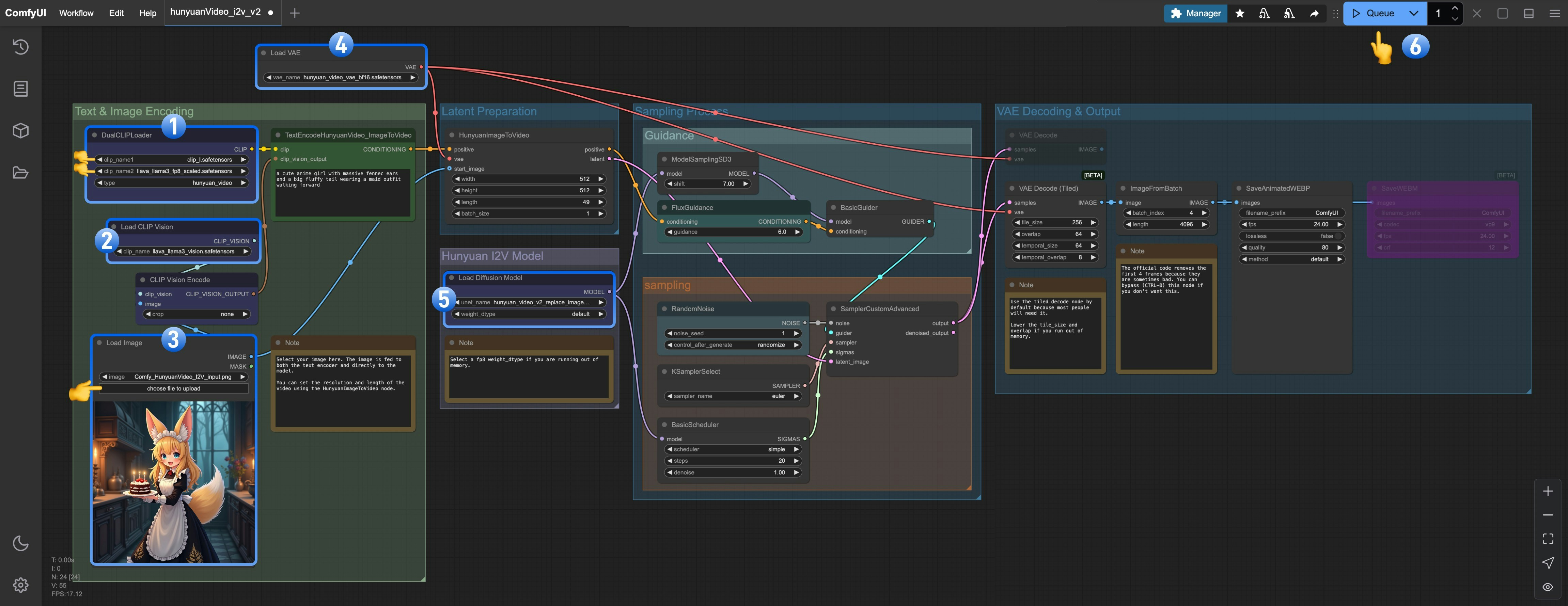
DualCLIPLoaderノードで以下のモデルがロードされていることを確認してください:- clip_name1: clip_l.safetensors
- clip_name2: llava_llama3_fp8_scaled.safetensors
Load CLIP Visionノードでllava_llama3_vision.safetensorsがロードされていることを確認してくださいLoad Image Modelノードでhunyuan_video_image_to_video_720p_bf16.safetensorsがロードされていることを確認してくださいLoad VAEノードでhunyuan_video_vae_bf16.safetensorsがロードされていることを確認してくださいLoad Diffusion Modelノードでhunyuan_video_v2_replace_image_to_video_720p_bf16.safetensorsがロードされていることを確認してくださいQueueボタンをクリックするか、ショートカットCtrl(cmd) + Enterを使用してワークフローを実行します
自分で試してみる
以下に、いくつかの画像とプロンプトを提供します。そのコンテンツに基づいて、または調整を加えて、独自の動画を作成してください。


