ユーザーは開始フレームと終了フレームの2枚の画像のみを提供すれば、モデルが自動的に中間の遷移フレームを生成し、論理的かつ自然な流れを持つ720p高精細動画を出力します。 主な技術的特長
- 高精度な始終フレーム制御:始終フレームの一致率は98%に達し、開始・終了シーンによって動画の境界を定義し、中間の動的変化を知的に補完することで、シーン遷移やオブジェクトの形態変化などの効果を実現します。
- 安定・滑らかな動画生成:CLIPのセマンティック特徴およびクロスアテンション機構を活用し、同様のモデルと比較して動画のジャッター率を37%低減。自然で滑らかな遷移を保証します。
- 多機能なクリエイティブ能力:中国語・英語字幕の動的埋め込み、アニメ/リアル/ファンタジーなど複数スタイルの生成に対応し、さまざまなクリエイティブニーズに応えます。
- 720p高精細出力:後処理を必要とせず、直接1280×720解像度の動画を生成。SNSや商用用途に最適です。
- オープンソースエコシステム対応:モデル重み、ソースコード、訓練フレームワークがすべてオープンソース化されており、主要なAIプラットフォームへのデプロイをサポートします。
- DiTアーキテクチャ:拡散モデルおよびDiffusion Transformerアーキテクチャに基づき、Full Attention機構を組み合わせて時空間依存性のモデリングを最適化し、動画の一貫性を確保します。
- 3D因果的変分エンコーダ:Wan-VAE技術により、高精細フレームを1/128サイズに圧縮しつつ、微細な動的ディテールを保持。メモリ使用量を大幅に削減します。
- 3段階トレーニング戦略:480P解像度での事前学習から始め、段階的に720Pへとアップグレード。フェーズごとの最適化により、生成品質と計算効率のバランスを図ります。
- GitHubリポジトリ: GitHub
- Hugging Faceモデルページ: Hugging Face
- ModelScopeコミュニティ: ModelScope
Wan2.1 FLF2V 720P ComfyUIネイティブワークフロー例
1. ワークフローファイルおよび関連入力ファイルのダウンロード
以下のWebPファイルをダウンロードし、ComfyUIにドラッグ&ドロップして対応するワークフローを読み込んでください。このワークフローには、必要なモデルのダウンロード情報が既に埋め込まれています。 以下の2枚の画像をダウンロードしてください。これらを動画の開始フレームおよび終了フレームとして使用します。
以下の2枚の画像をダウンロードしてください。これらを動画の開始フレームおよび終了フレームとして使用します。


2. 手動によるモデルインストール
本ガイドで使用するすべてのモデルは、こちらから入手できます。 diffusion_models:ご使用のハードウェア環境に応じて、以下のいずれかのバージョンを選択してください。 Text encoders:以下のいずれか1つのバージョンをダウンロードしてください。 VAE CLIP Vision ファイル保存先3. ワークフロー実行手順(ステップ・バイ・ステップ)
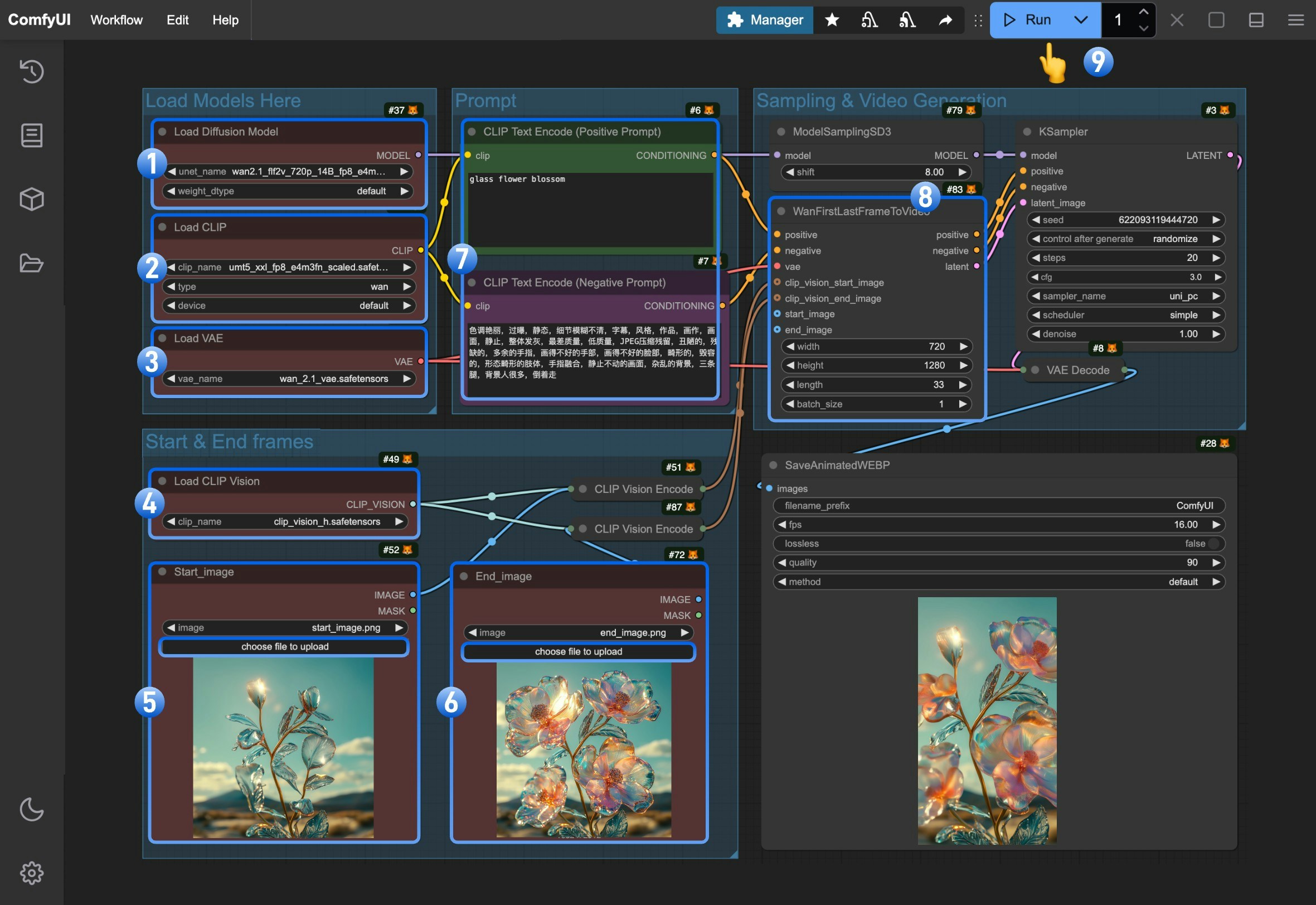
Load Diffusion Modelノードがwan2.1_flf2v_720p_14B_fp16.safetensorsまたはwan2.1_flf2v_720p_14B_fp8_e4m3fn.safetensorsを正しく読み込んでいることを確認してください。Load CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsを正しく読み込んでいることを確認してください。Load VAEノードがwan_2.1_vae.safetensorsを正しく読み込んでいることを確認してください。Load CLIP Visionノードがclip_vision_h.safetensorsを正しく読み込んでいることを確認してください。- 開始フレーム画像を
Start_imageノードにアップロードしてください。 - 終了フレーム画像を
End_imageノードにアップロードしてください。 - (任意)ポジティブプロンプトおよびネガティブプロンプトを編集できます(中国語および英語の両方がサポートされています)。
- (重要)
WanFirstLastFrameToVideoノードでは、デフォルトで720×1280のサイズが使用されています。これは720Pモデルであるため、小さいサイズでは良好な出力が得られません。高品質な生成を行うには、720×1280に近いサイズをご使用ください。 Runボタンをクリックするか、ショートカットキーCtrl(Macの場合はCmd) + Enterを押して動画生成を実行してください。