主な特徴
- 統合的なモーション制御:物体、局所領域、カメラモーションなど、複数のモーションタイプに対する軌道制御をサポート。
- インタラクティブな軌道エディタ:画像上に自由に軌道を描画・編集できる視覚的ツール。
- Wan2.1互換性:公式Wan2.1実装をベースとしており、実行環境およびモデル構造と互換性があります。
- 豊富な可視化ツール:入力軌道、出力動画、および軌道オーバーレイの可視化をサポート。
WAN ATI 軌道制御ワークフローの例
1. ワークフローのダウンロード
以下の動画をダウンロードし、ComfyUIにドラッグ&ドロップすることで、対応するワークフローを読み込みます。 以下のような画像を入力として使用します:
2. モデルのダウンロード
ワークフローからモデルファイルを正常にダウンロードできていない場合、以下のリンクから手動でダウンロードしてみてください。 Diffusionモデル VAE テキストエンコーダー(以下のいずれか1つを選択) clip_vision ファイル保存先3. ワークフロー実行のステップバイステップ手順
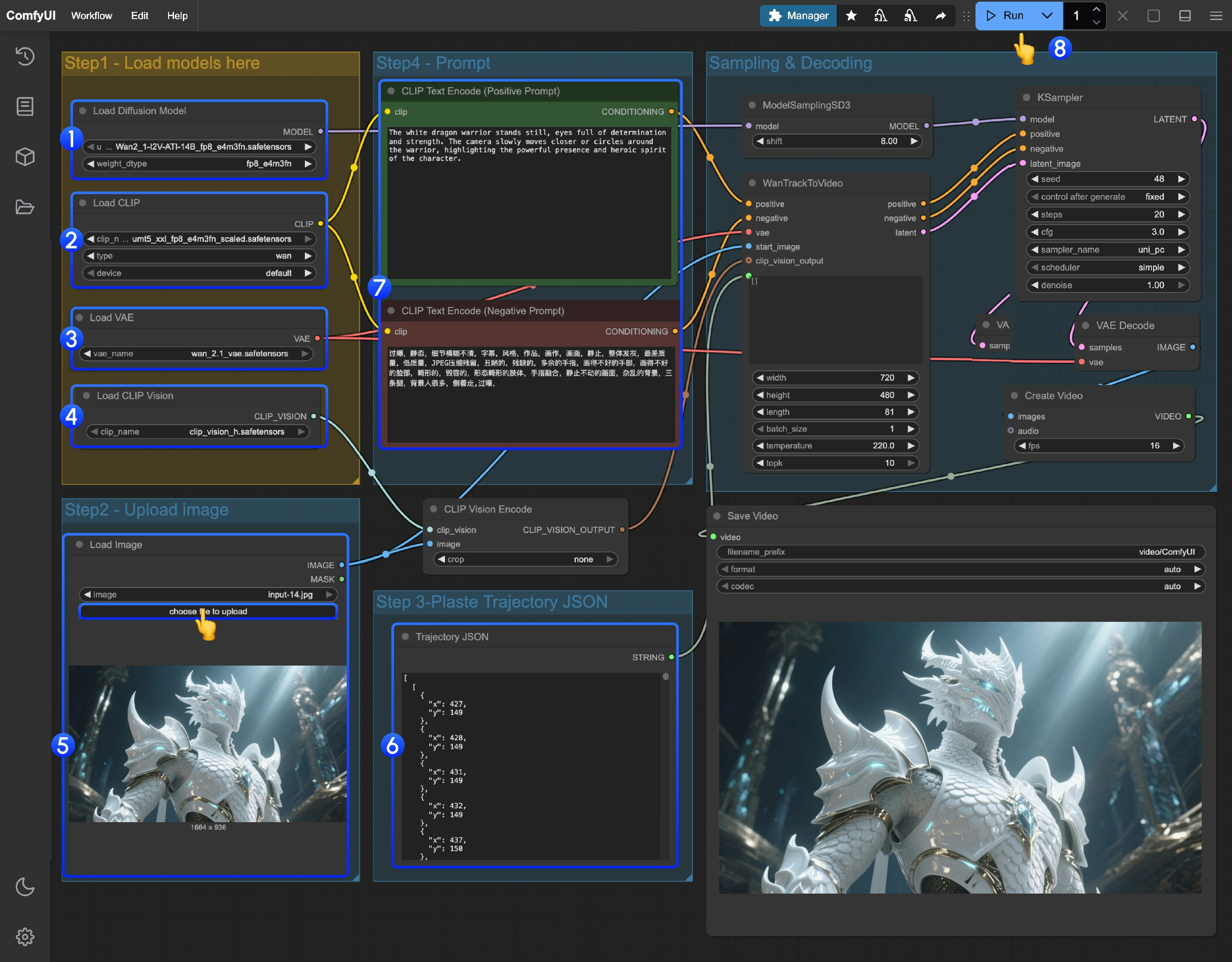
Load Diffusion ModelノードがWan2_1-I2V-ATI-14B_fp8_e4m3fn.safetensorsモデルを正しく読み込んでいることを確認してください。Load CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルを正しく読み込んでいることを確認してください。Load VAEノードがwan_2.1_vae.safetensorsモデルを正しく読み込んでいることを確認してください。Load CLIP Visionノードがclip_vision_h.safetensorsモデルを正しく読み込んでいることを確認してください。Load Imageノードに提供された入力画像をアップロードしてください。- 軌道編集:現時点ではComfyUIには対応する軌道エディタがまだ実装されていません。以下のリンクから軌道編集を完了できます。
- プロンプト(ポジティブ/ネガティブ)を変更したい場合は、番号
5のCLIP Text Encoderノードで編集してください。 Runボタンをクリックするか、ショートカットキーCtrl(Macの場合はCmd) + Enterを押して動画生成を実行してください。