- マルチモーダル制御: Canny(線画)、Depth(深度)、OpenPose(人体ポーズ)、MLSD(幾何学的エッジ)、および軌跡制御を含む複数の制御条件をサポート
- 高品質動画生成: Wan2.2 アーキテクチャに基づき、映画レベルの品質の動画を出力
- 多言語サポート: 中国語や英語を含む多言語プロンプトをサポート
- 🤗Wan2.2-Fun-A14B-Control
- コードリポジトリ:VideoX-Fun
ComfyOrg Wan2.2 Fun InP & Control YouTube ライブストリーム録画
Wan2.2 Fun Control 動画生成ワークフロー例
このワークフローは 2 つのバージョンを提供します:- lightx2v による Wan2.2-Lightning 4 ステップ LoRA を使用したバージョン:動画のダイナミクスにいくつかの損失が生じる可能性がありますが、速度は速くなります
- 加速 LoRA を使用しない fp8_scaled バージョン
4 ステップ LoRA を使用すると初次利用者のエクスペリエンスが向上しますが、動画のダイナミクスに損失が生じる可能性があるため、デフォルトでは加速 LoRA バージョンを有効にしています。別のワークフローを有効にしたい場合は、それを選択し、Ctrl+B を使用して有効にしてください。
1. ワークフローと素材のダウンロード
以下の動画または JSON ファイルをダウンロードし、ComfyUI にドラッグしてワークフローを読み込んでくださいJSON ワークフローをダウンロード
入力素材として以下の画像および動画をダウンロードしてください。
ここでは前処理済みの動画を使用しています。
2. モデル
以下のモデルは Wan_2.2_ComfyUI_Repackaged で見つかります Diffusion Model- wan2.2_fun_control_high_noise_14B_fp8_scaled.safetensors
- wan2.2_fun_control_low_noise_14B_fp8_scaled.safetensors
- wan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors
- wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
3. ワークフローガイド
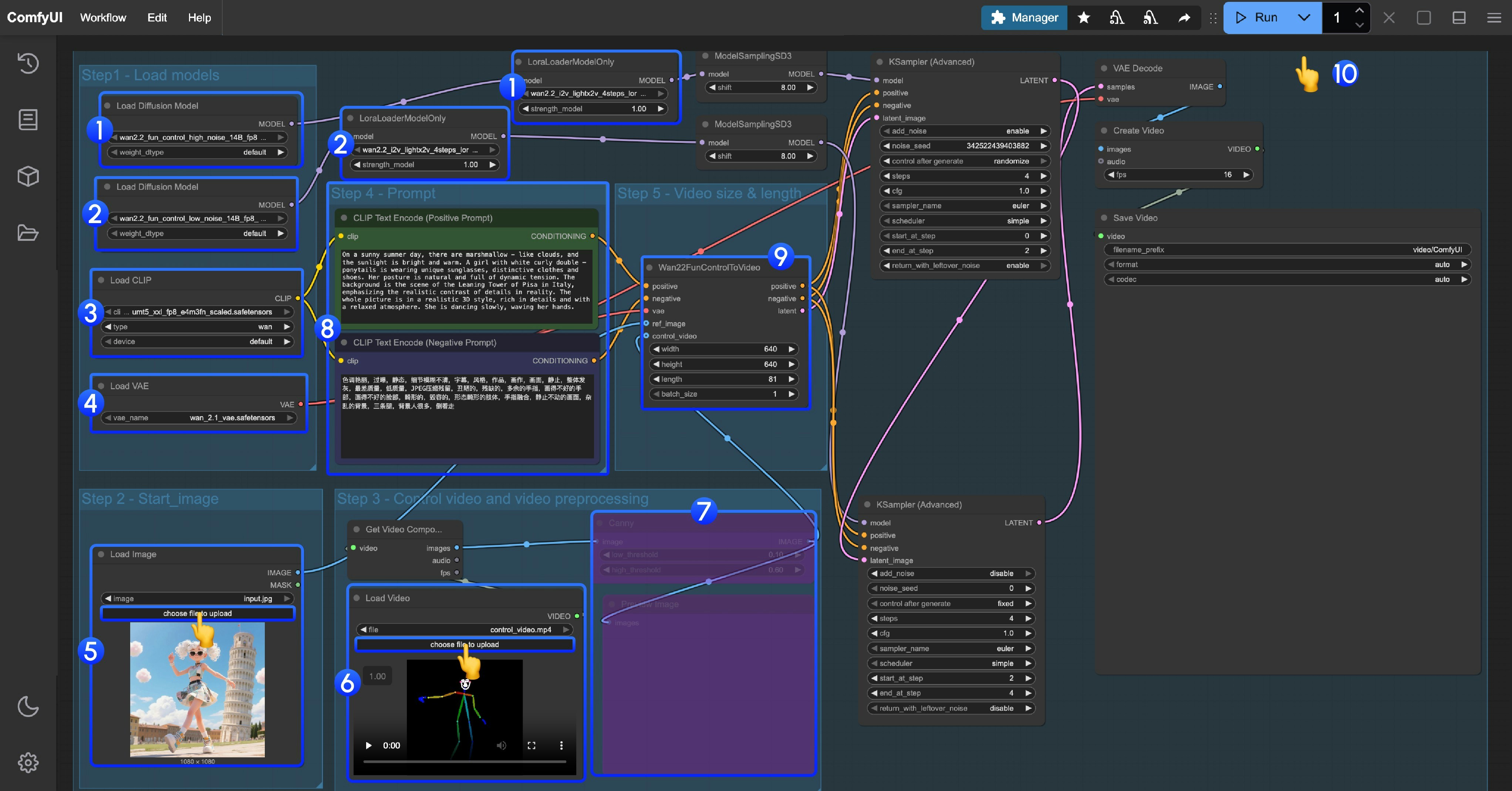
このワークフローは LoRA を使用します。対応する Diffusion モデルと LoRA が一致していることを確認してください - high noise と low noise のモデルと LoRA は対応して使用する必要があります。
- High noise モデルと LoRA の読み込み
Load Diffusion Modelノードがwan2.2_fun_control_high_noise_14B_fp8_scaled.safetensorsモデルを読み込むことを確認LoraLoaderModelOnlyノードがwan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensorsを読み込むことを確認
- Low noise モデルと LoRA の読み込み
Load Diffusion Modelノードがwan2.2_fun_control_low_noise_14B_fp8_scaled.safetensorsモデルを読み込むことを確認LoraLoaderModelOnlyノードがwan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensorsを読み込むことを確認
Load CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルを読み込むことを確認Load VAEノードがwan_2.1_vae.safetensorsモデルを読み込むことを確認Load Imageノードで開始フレームをアップロード- 2 つ目の
Load videoノードでポーズ制御動画を読み込みます。提供された動画は前処理済みで、直接使用できます - 前処理済みのポーズ動画を提供しているため、対応する動画画像前処理ノードを無効にする必要があります。選択して
Ctrl + Bを使用して無効にできます - プロンプトを変更 - 中国語と英語の両方を使用できます
Wan22FunControlToVideoで動画の次元を変更します。デフォルトは 640×640 解像度に設定されており、VRAM が少ないユーザーの処理時間が長くなりすぎないようにしていますRunボタンをクリック、またはショートカットCtrl(cmd) + Enterを使用して動画生成を実行