- 音声駆動型動画生成: 静止画像と音声を同期した動画に変換
- 映画級の高品質出力: 自然な表情や動きを伴う高精細動画を生成
- 分単位の動画生成: 長尺動画の作成をサポート
- 多様なフォーマット対応: 全身および上半身のキャラクターに対応
- 高度なモーション制御: テキストによる指示で動作や背景環境を生成可能
Wan2.2 S2V モデル: Hugging Face
Wan2.2 S2V の ComfyUI ネイティブワークフロー
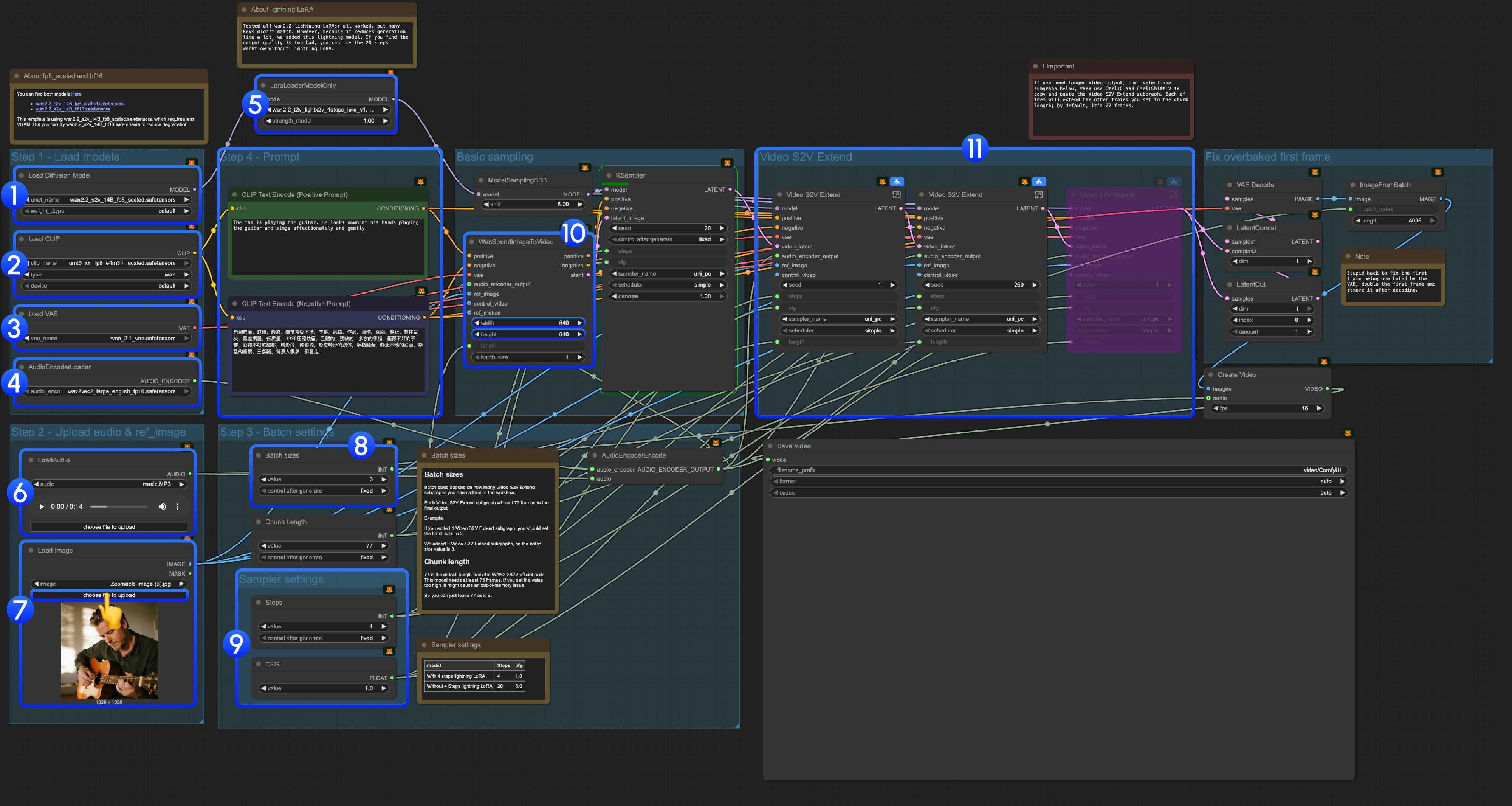
1. ワークフローファイルのダウンロード
以下のワークフローファイルをダウンロードし、ComfyUI へドラッグ&ドロップしてワークフローを読み込んでください。JSON ワークフローをダウンロード
Comfy Cloud で実行
以下の画像および音声ファイルを入力としてダウンロードしてください:
入力音声をダウンロード
2. モデルのダウンロードリンク
すべてのモデルは、当社のリポジトリ から入手できます。 diffusion_models audio_encoders vae text_encoders3. ワークフローの操作手順
3.1 Lightning LoRA について
3.2 fp8_scaled および bf16 モデルについて
両方のモデルは、こちらのページ から入手可能です: 本テンプレートではwan2.2_s2v_14B_fp8_scaled.safetensors を使用しており、VRAM 使用量が少ないのが特徴です。ただし、品質劣化を抑えるために wan2.2_s2v_14B_bf16.safetensors を試すことも可能です。
3.3 ステップごとの操作手順
ステップ 1:モデルの読み込み-
Diffusion モデルの読み込み:
wan2.2_s2v_14B_fp8_scaled.safetensorsまたはwan2.2_s2v_14B_bf16.safetensorsを読み込みます- 提供されているワークフローでは VRAM 使用量が少ない
wan2.2_s2v_14B_fp8_scaled.safetensorsを使用しています - ただし、品質劣化を抑えたい場合は
wan2.2_s2v_14B_bf16.safetensorsを試すことができます
- 提供されているワークフローでは VRAM 使用量が少ない
-
CLIP の読み込み:
umt5_xxl_fp8_e4m3fn_scaled.safetensorsを読み込みます -
VAE の読み込み:
wan_2.1_vae.safetensorsを読み込みます -
AudioEncoderLoader:
wav2vec2_large_english_fp16.safetensorsを読み込みます -
LoraLoaderModelOnly:
wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors(Lightning LoRA)を読み込みます- Wan2.2 のすべての Lightning LoRA をテストしましたが、これは Wan2.2 S2V 専用に学習された LoRA ではないため、多くのキー値が一致しません。ただし、生成時間を大幅に短縮できるため、本テンプレートに含めています。今後も最適化を継続していきます
- この LoRA を使用すると、動きの自然さおよび画質に著しい劣化が生じます
- 出力品質が不十分と感じた場合は、元の 20 ステップワークフローをお試しください
- LoadAudio: 提供済みの音声ファイル、またはユーザー自身の音声ファイルをアップロードします
- Load Image: 参照用の画像をアップロードします
-
バッチサイズ: 追加する「Video S2V Extend」サブグラフノードの数に応じて設定します
- 各「Video S2V Extend」サブグラフは、最終出力に 77 フレームを追加します
- 例:「Video S2V Extend」サブグラフを 2 個追加した場合、バッチサイズは 3 に設定します(これは全サンプリング反復回数を意味します)
- Chunk Length: デフォルト値の 77 のままにしてください
-
サンプラー設定: Lightning LoRA の使用有無に応じて異なる設定を選択します
- 4 ステップ Lightning LoRA を使用する場合:
steps: 4,cfg: 1.0 - 4 ステップ Lightning LoRA を使用しない場合:
steps: 20,cfg: 6.0
- 4 ステップ Lightning LoRA を使用する場合:
- サイズ設定: 出力動画の解像度を設定します
-
Video S2V Extend: 動画拡張用のサブグラフノードです。デフォルトのサンプリングフレーム数は 77 であり、本モデルは 16fps であるため、各拡張により
77 / 16 = 4.8125秒の動画が生成されます- 入力音声の長さに合わせて「Video S2V Extend」サブグラフノードの数を計算する必要があります。例:入力音声が 14 秒の場合、必要な総フレーム数は
14 × 16 = 224、各拡張は 77 フレームであるため、必要なノード数は224 / 77 ≈ 2.9→ 切り上げて 3 個となります
- 入力音声の長さに合わせて「Video S2V Extend」サブグラフノードの数を計算する必要があります。例:入力音声が 14 秒の場合、必要な総フレーム数は
-
Ctrl + Enterキーを押すか、[実行] ボタンをクリックしてワークフローを実行します