VACE について
VACE 14B は、アリババ Tongyi Wanxiang チームが公開したオープンソースの統合型動画編集モデルです。このモデルは、複数のタスクを統合した機能、高解像度処理のサポート、および柔軟なマルチモーダル入力機構を備えており、動画制作の効率性と品質を大幅に向上させます。 本モデルは Apache-2.0 ライセンスの下でオープンソース化されており、個人利用および商用利用が可能です。 以下に、その主な特徴および技術的ハイライトを総合的に解説します:- マルチモーダル入力:テキスト、画像、動画、マスク、制御信号など、複数の入力形式をサポート
- 統合アーキテクチャ:単一のモデルで複数のタスクをサポートし、機能を自由に組み合わせ可能
- モーション転送:参照動画に基づいて連続的かつ自然な動作を生成
- 局所的置換:マスクを用いて動画内の特定領域を置換
- 動画拡張:動作の補完や背景の延長を実行
- 背景置換:被写体を保持したまま、環境の背景を変更
関連するモデル重みおよびコードリポジトリ:
モデルのダウンロードおよびワークフローへの読み込み
本ドキュメントで紹介するすべてのワークフローは同一のテンプレートを使用しているため、まずモデルのダウンロードおよび読み込み手順を説明し、その後、異なるノードを Bypass(無効化)することで、各種入力の有効/無効を切り替えて、異なるワークフローを実現できます。なお、具体的なサンプルワークフローの情報内には既にモデルのダウンロード情報が埋め込まれているため、サンプルワークフローをダウンロードする際に同時にモデルも取得できます。
モデルのダウンロード
diffusion_modelswan2.1_vace_14B_fp16.safetensors
wan2.1_vace_1.3B_fp16.safetensors VAE Text encoders からいずれか 1 つのバージョンを選択してダウンロードしてください: ファイルの保存先:
モデルの読み込み
本ドキュメントで扱うワークフローでは、使用するモデルが共通であり、ワークフロー自体も同一であるため、各ワークフローにおいて異なる入力を有効/無効にするためにノードの Bypass を切り替えるだけです。以下の画像を参考に、それぞれのワークフローで対応するモデルが正しく読み込まれていることを確認してください。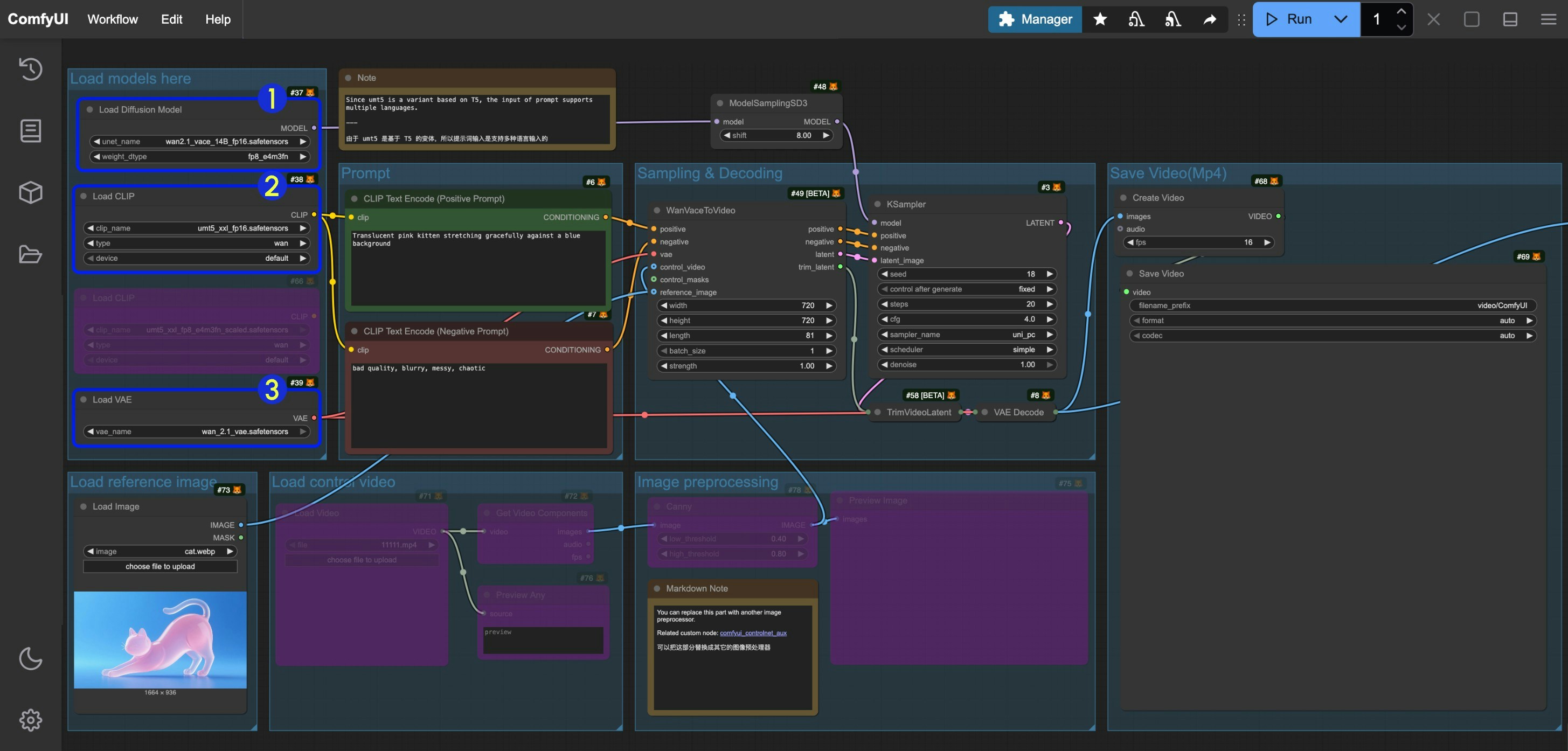
Load Diffusion Modelノードがwan2.1_vace_14B_fp16.safetensorsを読み込んでいることを確認してくださいLoad CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsまたはumt5_xxl_fp16.safetensorsを読み込んでいることを確認してくださいLoad VAEノードがwan_2.1_vae.safetensorsを読み込んでいることを確認してください
ノードの Bypass 状態を切り替える方法
ノードが Bypass 状態に設定されている場合、そのノードを通過するデータはノードの処理を受けず、そのまま出力されます。ノードをワークフローから削除せずに一時的に無効化したい場合などに、Bypass 状態を設定することがよくあります。 以下は、ノードの Bypass 状態を切り替える3つの方法です: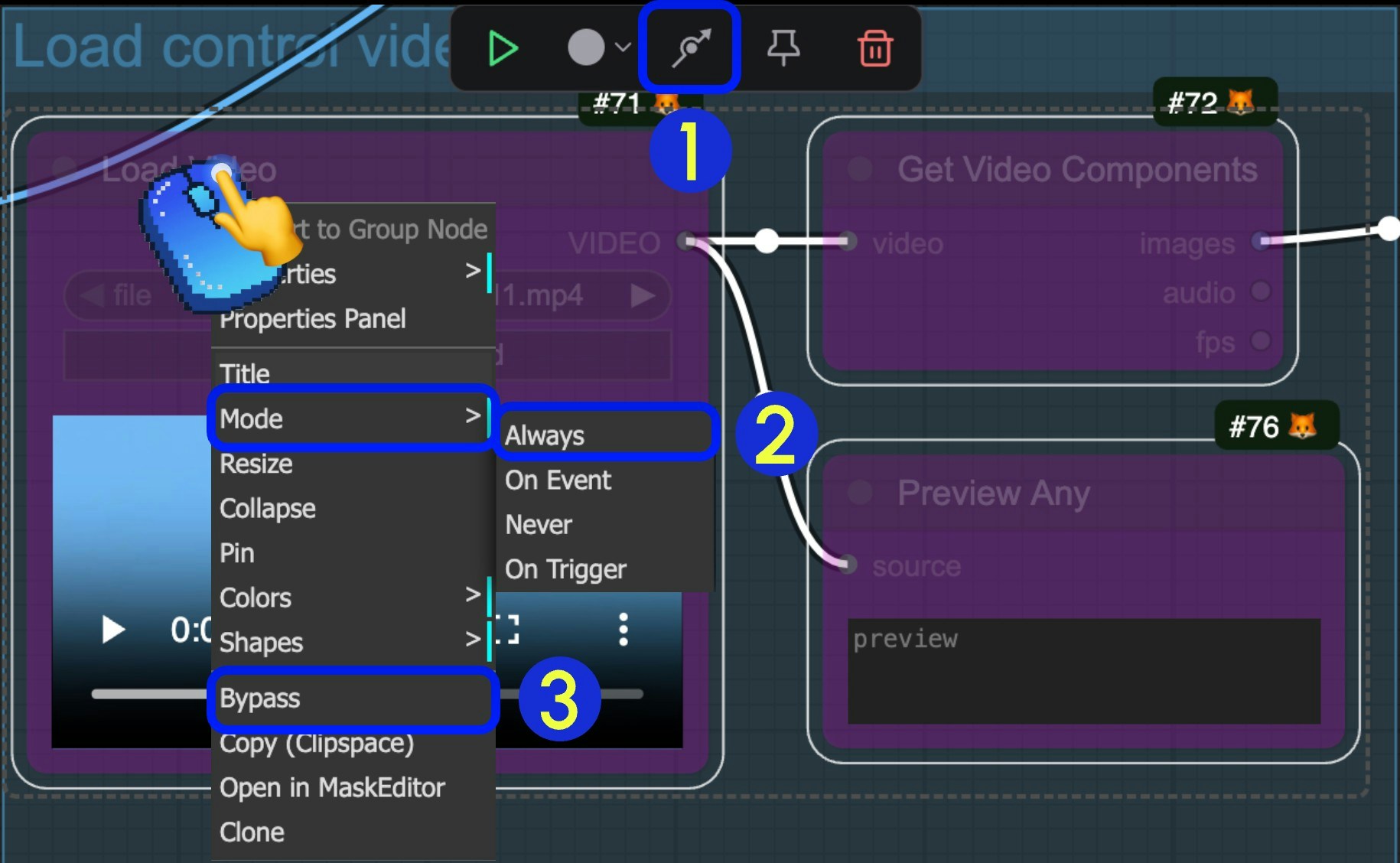
- ノードを選択した状態で、選択ツールボックスの「インジケーター」セクションにある矢印アイコンをクリックすると、ノードの Bypass 状態をすばやく切り替えることができます
- ノードを選択した状態で、ノードを右クリックし、
モード(Mode)→常に(Always)を選択して、Always モードに切り替えます - ノードを選択した状態で、ノードを右クリックし、
Bypass(バイパス)オプションを選択して、Bypass 状態を切り替えます
VACE テキストから動画へ(Text-to-Video)ワークフロー
1. ワークフローのダウンロード
以下の動画をダウンロードし、ComfyUI にドラッグ&ドロップすることで、対応するワークフローを読み込んでください。2. ステップ・バイ・ステップでワークフローを完了する
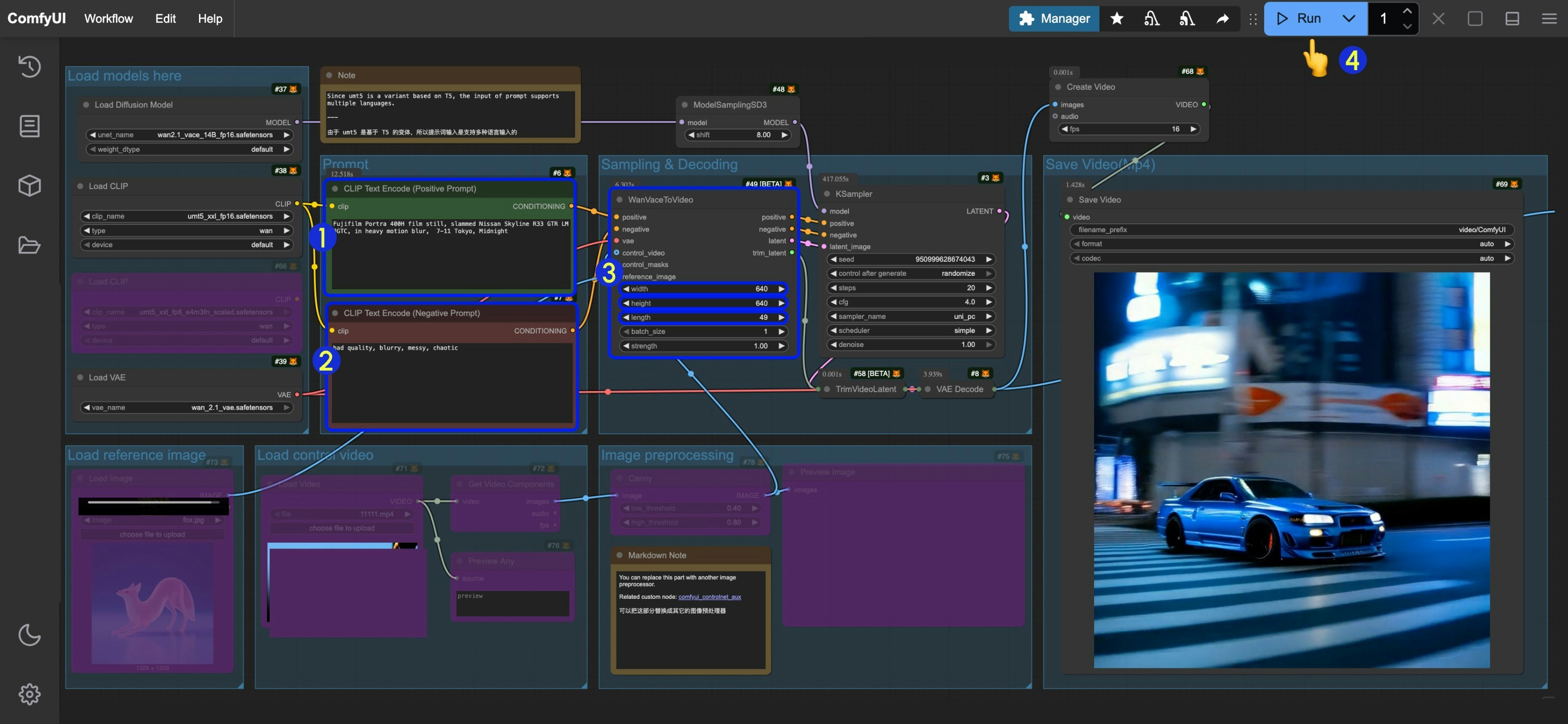
CLIP Text Encode (Positive Prompt)ノードにポジティブプロンプトを入力してください- `