このモデルには以下の 2 つのバージョンがあります:
- 14B(140 億パラメータ)
- 1.3B(13 億パラメータ)
テキストから動画を生成する「テキスト→動画(T2V)」や画像から動画を生成する「画像→動画(I2V)」など、複数のタスクに対応しています。
このモデルは既存のオープンソースモデルを性能面で上回るだけでなく、特に軽量版はわずか 8GB の VRAM で実行可能であり、導入ハードルを大幅に低減しています。
Wan2.1 ComfyUI ネイティブワークフローのサンプル
モデルのインストール
このガイドで言及されるすべてのモデルは、こちら から入手できます。以下は、このガイドのサンプルで使用する共通のモデルであり、事前にダウンロードしておくことを推奨します: Text encoders からいずれか 1 つのバージョンを選択してダウンロードしてください: VAE CLIP Vision ファイルの保存先ディレクトリ構成:diffusion モデルについては、本ガイドでは fp16 精度のモデルを使用します。これは bf16 版と比較して性能が優れているためです。他の精度のモデルが必要な場合は、こちら からダウンロードしてください。
Wan2.1 テキスト→動画(T2V)ワークフロー
ワークフローを開始する前に、wan2.1_t2v_1.3B_fp16.safetensors をダウンロードし、ComfyUI/models/diffusion_models/ ディレクトリに保存してください。
他の T2V 精度バージョンが必要な場合は、こちら からダウンロードしてください。
1. ワークフローファイルのダウンロード
以下のファイルをダウンロードし、ComfyUI にドラッグ&ドロップして、対応するワークフローを読み込んでください:
2. ワークフローをステップごとに実行
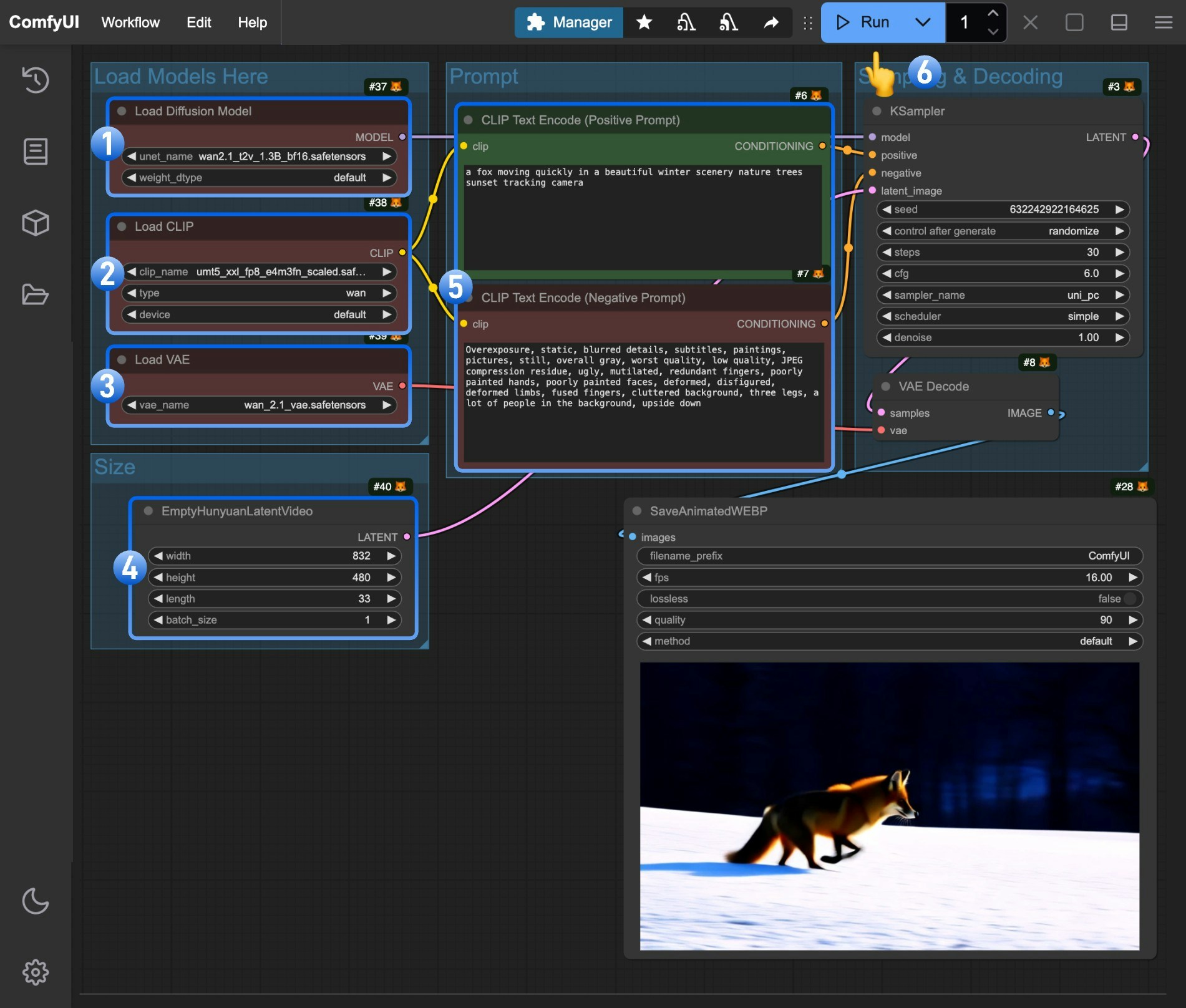
Load Diffusion Modelノードがwan2.1_t2v_1.3B_fp16.safetensorsモデルを正しく読み込んでいることを確認してくださいLoad CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルを正しく読み込んでいることを確認してくださいLoad VAEノードがwan_2.1_vae.safetensorsモデルを正しく読み込んでいることを確認してください- (任意)必要に応じて、
EmptyHunyuanLatentVideoノードで動画の解像度を変更できます - (任意)プロンプト(ポジティブ/ネガティブ)を変更したい場合は、番号
5のCLIP Text Encoderノードで編集してください Runボタンをクリックするか、ショートカットキーCtrl(Mac の場合 Cmd) + Enterを押して動画生成を実行してください
Wan2.1 画像→動画(I2V)ワークフロー
Wan Video では 480P と 720P のモデルが別々に提供されているため、本ガイドではそれぞれの解像度について個別にサンプルを示します。モデルが異なることに加え、若干のパラメーター設定の違いもあります。480P バージョン
1. ワークフローおよび入力画像
以下の画像をダウンロードし、ComfyUI にドラッグ&ドロップして対応するワークフローを読み込んでください: 入力として以下の画像を使用します:
入力として以下の画像を使用します:

2. モデルのダウンロード
wan2.1_i2v_480p_14B_fp16.safetensors をダウンロードし、ComfyUI/models/diffusion_models/ ディレクトリに保存してください。
3. ワークフローをステップごとに実行
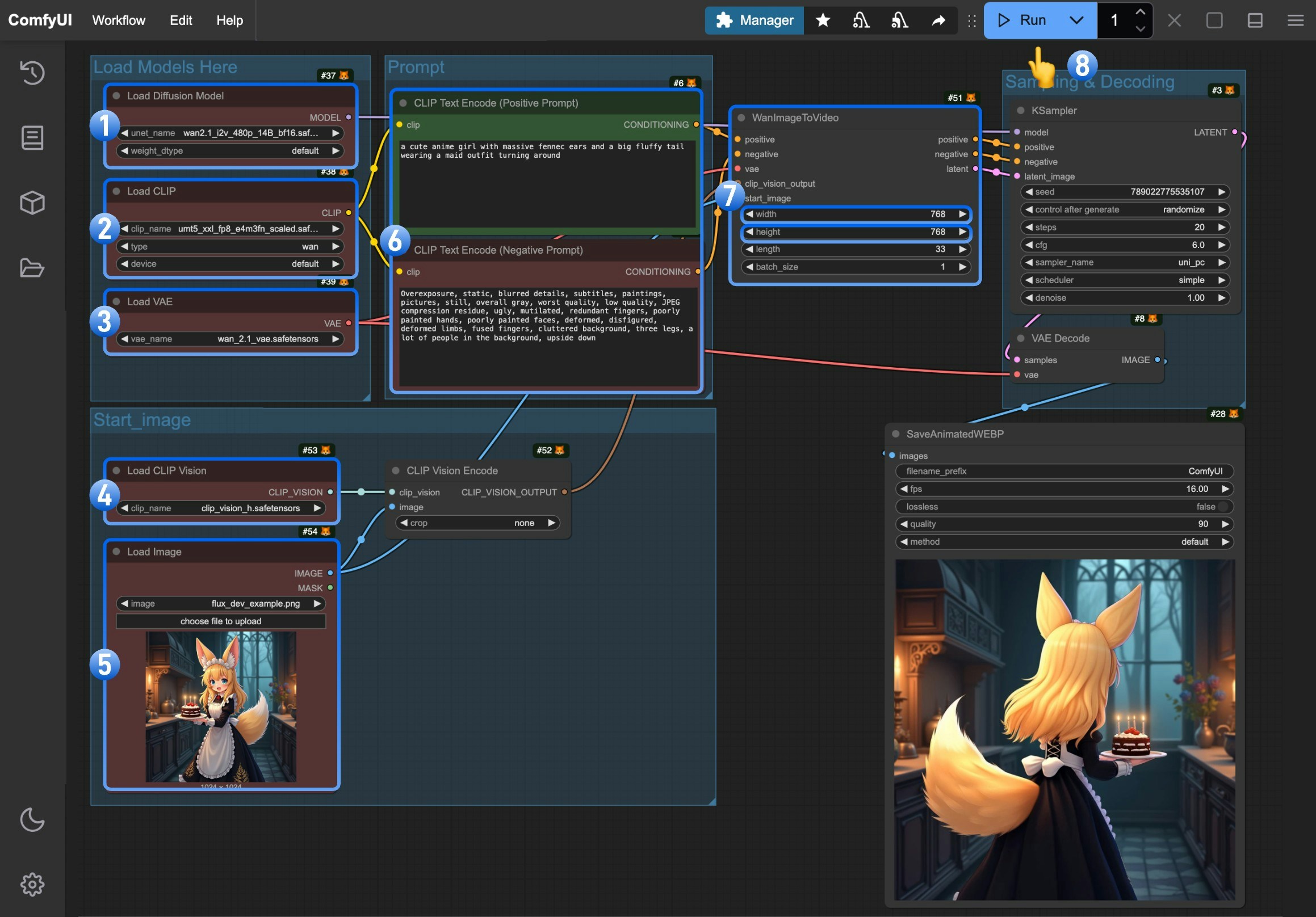
Load Diffusion Modelノードがwan2.1_i2v_480p_14B_fp16.safetensorsモデルを正しく読み込んでいることを確認してくださいLoad CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルを正しく読み込んでいることを確認してくださいLoad VAEノードがwan_2.1_vae.safetensorsモデルを正しく読み込んでいることを確認してくださいLoad CLIP Visionノードがclip_vision_h.safetensorsモデルを正しく読み込んでいることを確認してくださいLoad Imageノードで提供された入力画像をアップロードしてください- (任意)生成したい動画の説明文を
CLIP Text Encoderノードに入力してください - (任意)必要に応じて、
WanImageToVideoノードで動画の解像度を変更できます Runボタンをクリックするか、ショートカットキーCtrl(Mac の場合 Cmd) + Enterを押して動画生成を実行してください
720P バージョン
1. ワークフローおよび入力画像
以下の画像をダウンロードし、ComfyUI にドラッグ&ドロップして対応するワークフローを読み込んでください: 入力として以下の画像を使用します:
入力として以下の画像を使用します:

2. モデルのダウンロード
wan2.1_i2v_720p_14B_fp16.safetensors をダウンロードし、ComfyUI/models/diffusion_models/ ディレクトリに保存してください。
3. ワークフローをステップごとに実行
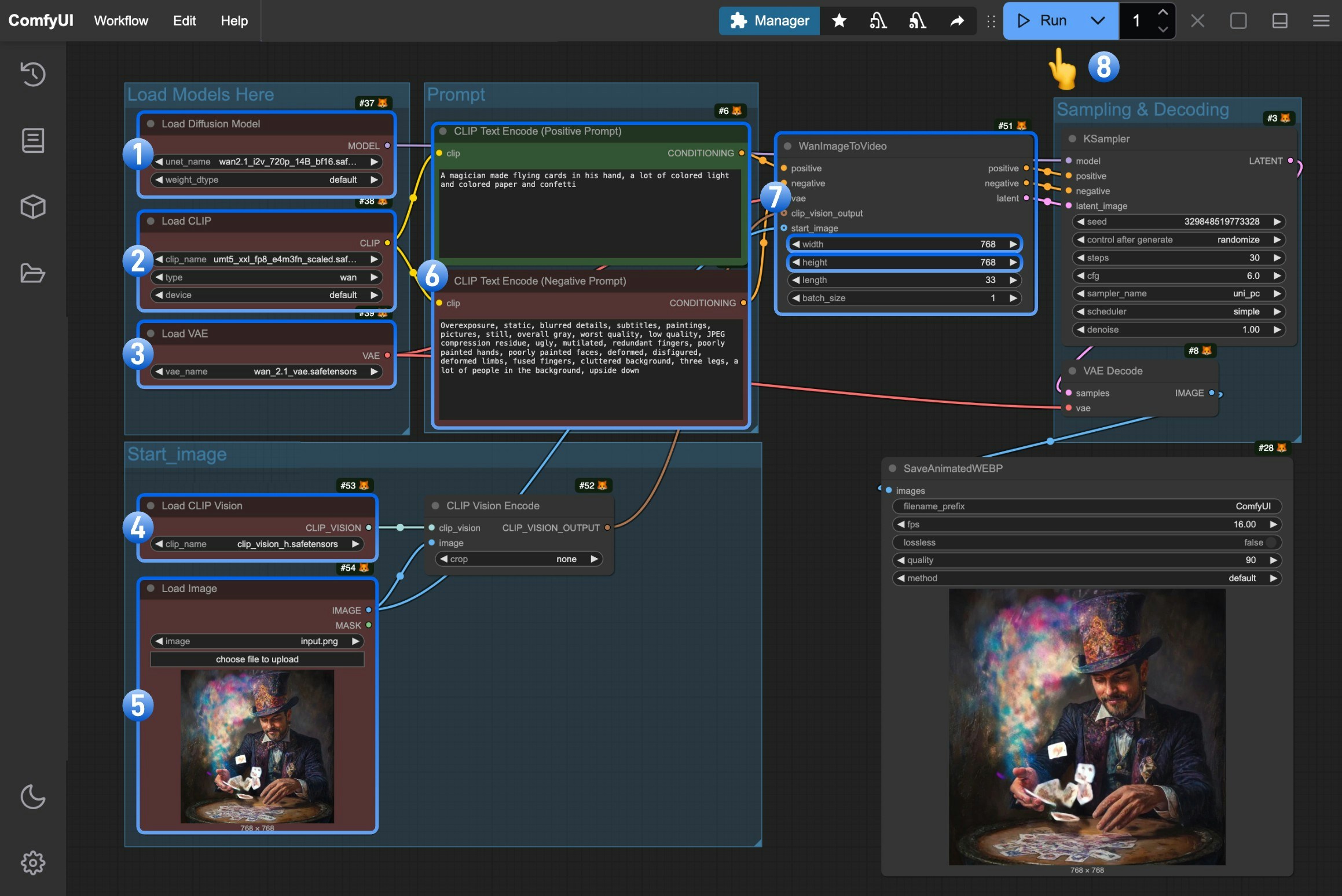
Load Diffusion Modelノードがwan2.1_i2v_720p_14B_fp16.safetensorsモデルを正しく読み込んでいることを確認してくださいLoad CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルを正しく読み込んでいることを確認してくださいLoad VAEノードがwan_2.1_vae.safetensorsモデルを正しく読み込んでいることを確認してくださいLoad CLIP Visionノードがclip_vision_h.safetensorsモデルを正しく読み込んでいることを確認してくださいLoad Imageノードで提供された入力画像をアップロードしてください- (任意)生成したい動画の説明文を
CLIP Text Encoderノードに入力してください - (任意)必要に応じて、
WanImageToVideoノードで動画の解像度を変更できます Runボタンをクリックするか、ショートカットキーCtrl(Mac の場合 Cmd) + Enterを押して動画生成を実行してください