- 우수한 다국어 텍스트 렌더링: 영어, 중국어, 한국어, 일본어 등 다양한 언어에서 고정밀 텍스트 생성을 지원하며, 글꼴 세부 정보와 레이아웃 일관성을 유지합니다.
- 다양한 예술적 스타일: 포토리얼리즘 장면부터 인상파 그림, 애니메이션 스타일부터 미니멀리즘 디자인까지 다양한 창작 프롬프트에 유연하게 적응합니다.
- Qwen-Image-DiffSynth-ControlNets/model_patches: 캐니, 딥스, 인페인트 모델 포함
- qwen_image_union_diffsynth_lora.safetensors: 이미지 구조 제어 LoRA, 캐니, 딥스, 포즈, 라인아트, 소프트엣지, 노말, 오픈포즈 지원
- InstantX ControlNet: 추후 업데이트 예정
ComfyOrg Qwen-Image 라이브 스트림
Qwen-Image in ComfyUI - Lightning & LoRAs
Qwen-Image ControlNet in ComfyUI - DiffSynth
Qwen-Image 네이티브 워크플로우 예시
Comfy Cloud에서 실행하기 이 문서에 첨부된 워크플로우에는 세 가지 다른 모델이 사용됩니다:- Qwen-Image 원본 모델 fp8_e4m3fn
- 8단계 가속 버전: Qwen-Image 원본 모델 fp8_e4m3fn에 lightx2v 8단계 LoRA 적용
- 증류 버전: Qwen-Image 증류 모델 fp8_e4m3fn
1. 워크플로우 파일
ComfyUI를 업데이트한 후, 템플릿에서 워크플로우 파일을 찾거나 아래 워크플로우를 ComfyUI로 드래그해 불러올 수 있습니다.
Qwen-Image 공식 모델용 워크플로우 다운로드
증류 버전증류 모델용 워크플로우 다운로드
2. 모델 다운로드
ComfyUI에서 사용 가능한 모델- Qwen-Image_bf16 (40.9 GB)
- Qwen-Image_fp8 (20.4 GB)
- 증류 버전 (비공식, 15단계만 필요)
- 증류 버전의 원저자는 cfg 1.0에서 15단계 사용을 권장합니다.
- 테스트 결과, 이 증류 버전은 cfg 1.0에서 10단계에서도 우수한 성능을 보입니다. 원하는 이미지 유형에 따라 오일러 또는 res_multistep 중 선택할 수 있습니다.
3. 워크플로우 지침
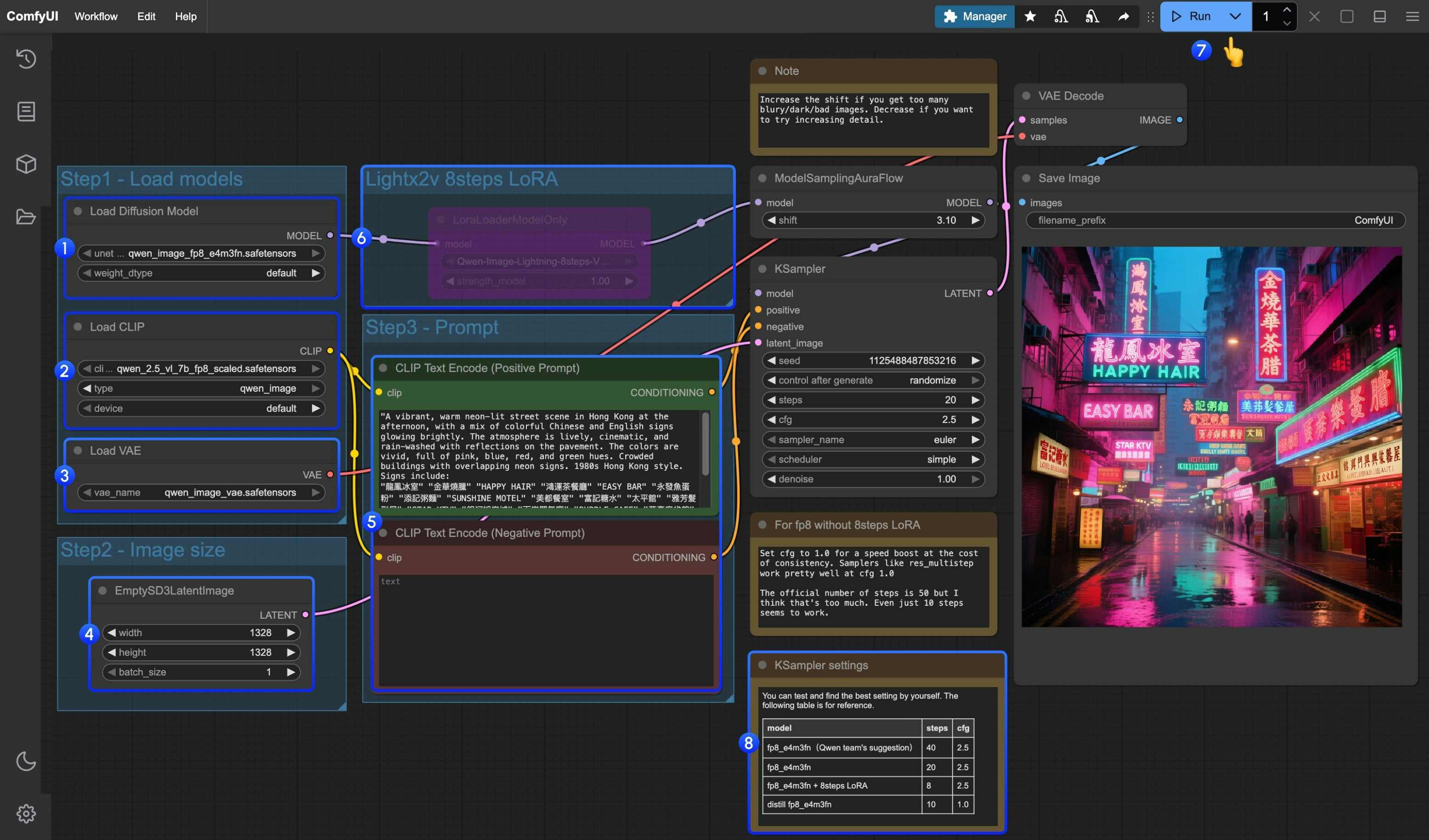
Load Diffusion Model노드가qwen_image_fp8_e4m3fn.safetensors를 로드했는지 확인하세요.Load CLIP노드가qwen_2.5_vl_7b_fp8_scaled.safetensors를 로드했는지 확인하세요.Load VAE노드가qwen_image_vae.safetensors를 로드했는지 확인하세요.EmptySD3LatentImage노드가 정확한 이미지 크기로 설정되었는지 확인하세요.CLIP Text Encoder노드에 프롬프트를 설정하세요. 현재 영어, 중국어, 한국어, 일본어, 이탈리아어 등을 지원합니다.- 8단계 가속 LoRA를 lightx2v로 활성화하려면 해당 노드를 선택하고
Ctrl + B를 눌러 활성화하고, 8번 단계에서 설명한 대로 Ksampler 설정을 수정하세요. Queue버튼을 클릭하거나, 단축키Ctrl(cmd) + Enter를 사용해 워크플로우를 실행하세요.- 모델 버전과 워크플로우에 따라 KSampler 매개변수를 적절히 조정하세요.
증류 모델과 lightx2v의 8단계 가속 LoRA는 동시에 사용되지 않는 것으로 보입니다. 서로 다른 조합을 실험해 함께 사용할 수 있는지 확인해보세요.
Qwen Image InstantX ControlNet 워크플로우
이것은 ControlNet 모델이므로 일반 ControlNet처럼 사용할 수 있습니다. Comfy Cloud에서 실행하기1. 워크플로우 및 입력 이미지
아래 이미지를 다운로드해 ComfyUI로 드래그해 워크플로우를 불러오세요.
JSON 형식 워크플로우 다운로드
아래 이미지를 입력으로 다운로드하세요.
2. 모델 링크
- InstantX Controlnet
ComfyUI/models/controlnet/ 폴더에 저장하세요.
- Lotus Depth 모델
- vae-ft-mse-840000-ema-pruned.safetensors 또는 어떤 SD1.5 VAE도 가능합니다.
comfyui_controlnet_aux와 같은 커스텀 노드를 사용해 깊이맵을 생성할 수도 있습니다.
3. 워크플로우 지침
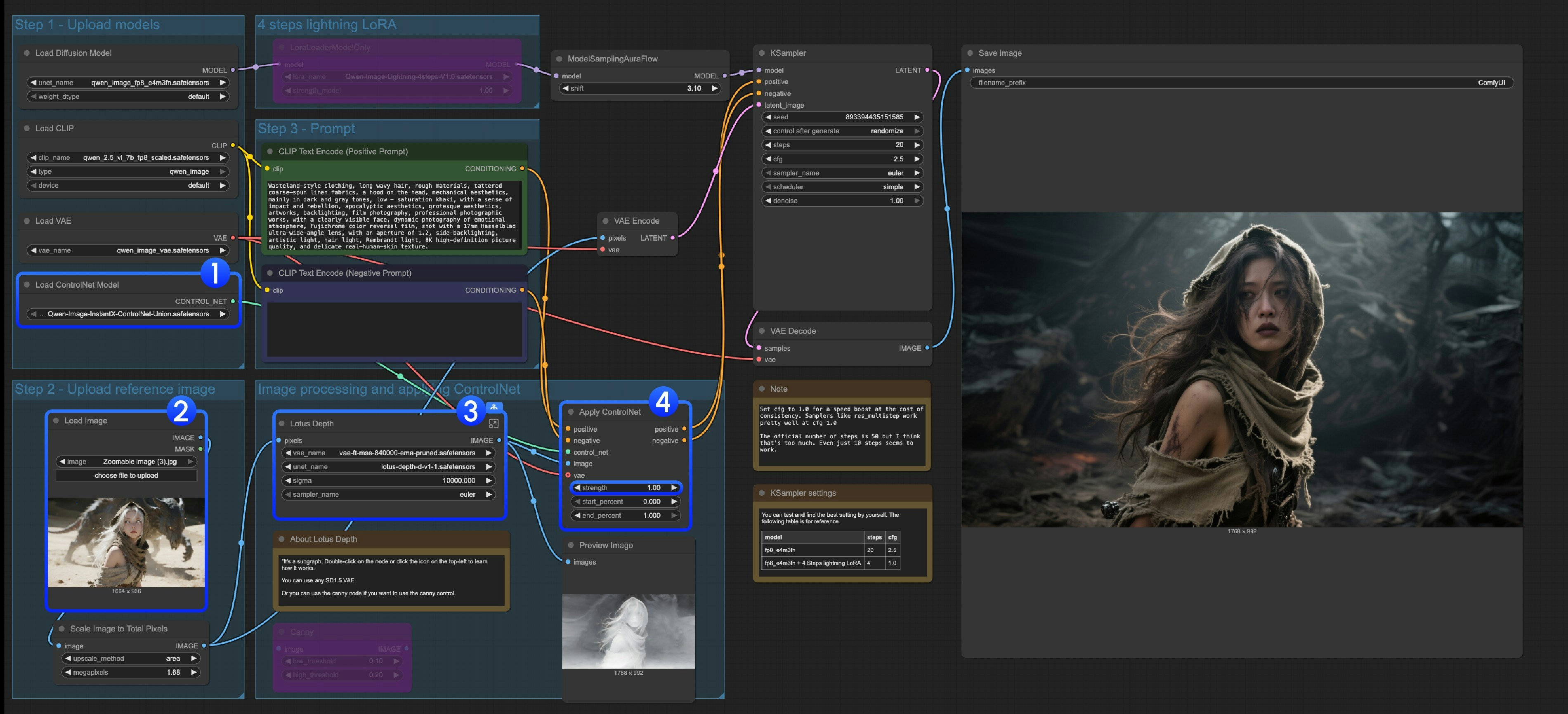
Load ControlNet Model노드가Qwen-Image-InstantX-ControlNet-Union.safetensors모델을 정확히 로드했는지 확인하세요.- 입력 이미지를 업로드하세요.
- 이 서브그래프는 Lotus Depth 모델을 사용합니다. 템플릿에서 찾거나 서브그래프를 편집해 더 자세히 알아볼 수 있으며, 모든 모델이 정확히 로드되었는지 확인하세요.
Run버튼을 클릭하거나, 단축키Ctrl(cmd) + Enter를 사용해 워크플로우를 실행하세요.
Qwen Image ControlNet DiffSynth-ControlNets 모델 패치 워크플로우
Comfy Cloud에서 실행하기 이 모델은 실제로 ControlNet이 아니라, 캐니, 딥스, 인페인트 등 세 가지 다른 제어 모드를 지원하는 모델 패치입니다. 원본 모델 주소: DiffSynth-Studio/Qwen-Image ControlNetComfy Org 재호스팅 주소: Qwen-Image-DiffSynth-ControlNets/model_patches
1. 워크플로우 및 입력 이미지
아래 이미지를 다운로드해 ComfyUI로 드래그해 해당 워크플로우를 불러오세요.
JSON 형식 워크플로우 다운로드
아래 이미지를 입력으로 다운로드하세요:
2. 모델 링크
다른 모델은 Qwen-Image 기본 워크플로우와 동일합니다. 아래 모델만 다운로드해ComfyUI/models/model_patches 폴더에 저장하면 됩니다.
- qwen_image_canny_diffsynth_controlnet.safetensors
- qwen_image_depth_diffsynth_controlnet.safetensors
- qwen_image_inpaint_diffsynth_controlnet.safetensors
3. 워크플로우 사용 지침
현재 diffsynth는 캐니, 딥스, 인페인트 세 가지 패치 모델을 제공합니다. ControlNet 관련 워크플로우를 처음 사용한다면, 제어 이미지는 모델이 인식하고 사용하기 전에 지원되는 이미지 형식으로 사전 처리되어야 한다는 점을 이해해야 합니다.
- 캐니: 처리된 캐니 에지, 라인아트 윤곽선
- 딥스: 공간 관계를 나타내는 사전 처리된 깊이맵
- 인페인트: 마스크를 사용해 다시 그려야 할 영역을 표시해야 합니다.
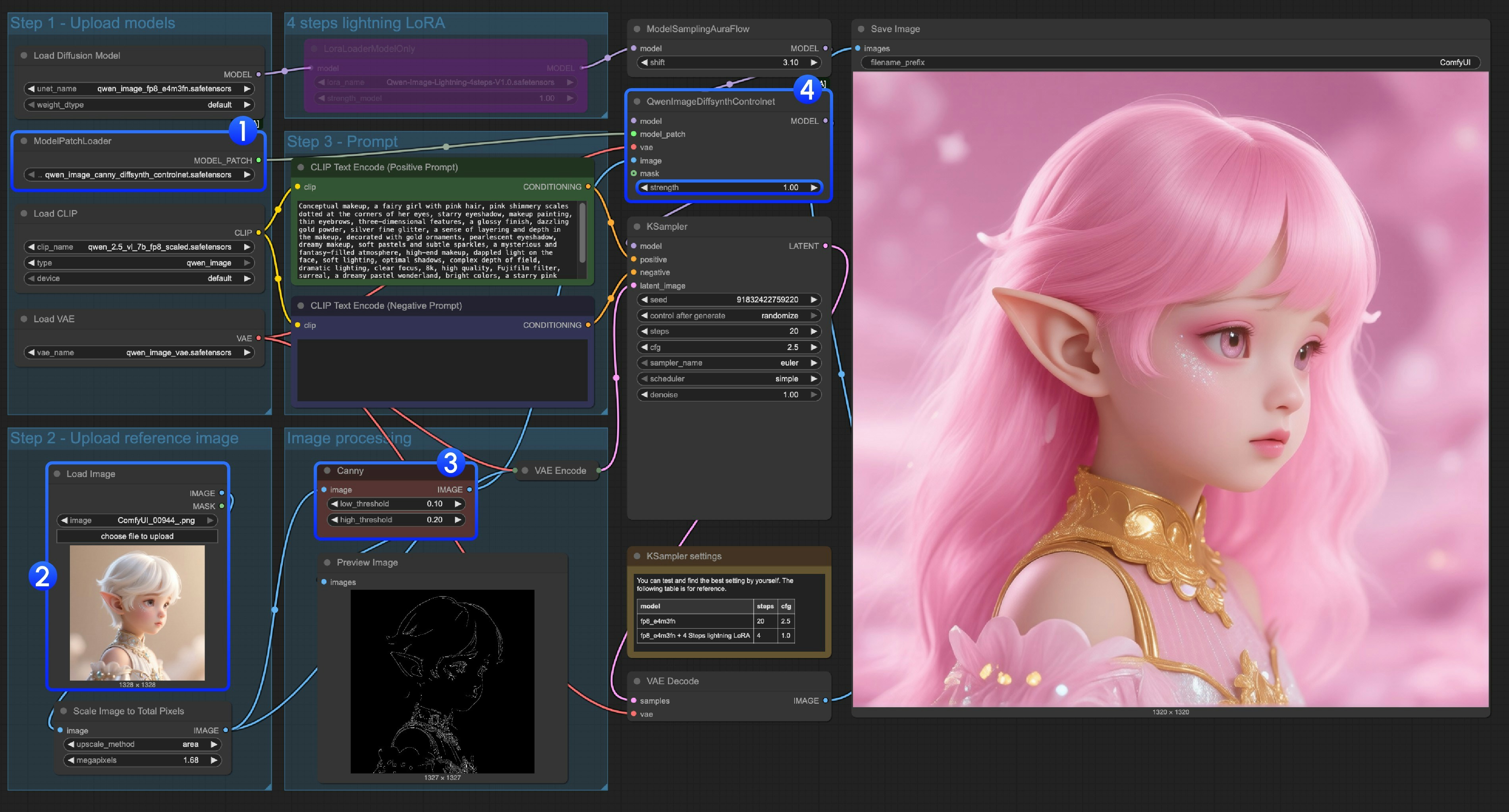
qwen_image_canny_diffsynth_controlnet.safetensors가 로드되었는지 확인하세요.- 이후 처리를 위해 입력 이미지를 업로드하세요.
- 캐니 노드는 원본 사전 처리 노드로, 설정한 매개변수에 따라 입력 이미지를 처리해 생성을 제어합니다.
- 필요하다면
QwenImageDiffsynthControlnet노드의strength를 수정해 라인아트 제어 강도를 조정할 수 있습니다. Run버튼을 클릭하거나, 단축키Ctrl(cmd) + Enter를 사용해 워크플로우를 실행하세요.
qwen_image_depth_diffsynth_controlnet.safetensors를 사용하려면 이미지를 깊이맵으로 사전 처리하고 image processing 부분을 교체해야 합니다. 이 사용법은 이 문서의 InstantX 처리 방법을 참고하세요. 다른 부분은 캐니 모델 사용법과 비슷합니다.
인페인트 모델 ControlNet 사용 지침
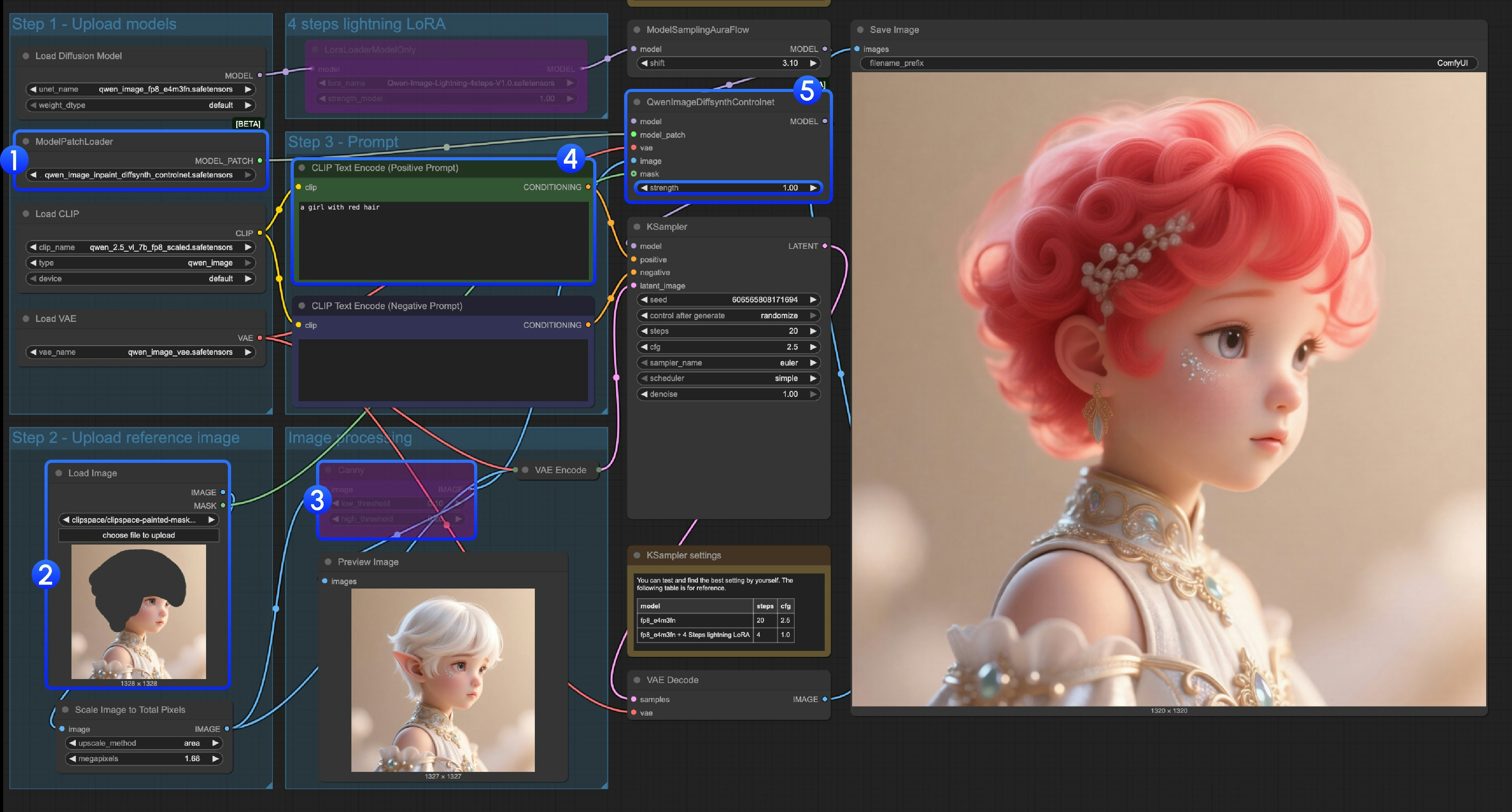
ModelPatchLoader가qwen_image_inpaint_diffsynth_controlnet.safetensors모델을 로드했는지 확인하세요.- 이미지를 업로드하고 Mask Editor를 사용해 마스크를 그립니다. 해당
Load Image노드의mask출력을QwenImageDiffsynthControlnet의mask입력에 연결해 정확한 마스크가 로드되도록 해야 합니다. Ctrl-B단축키를 사용해 워크플로우의 원래 캐니를 바이패스 모드로 설정해 해당 캐니 노드의 처리를 무효화하세요.CLIP Text Encoder에서 마스크로 변경하고 싶은 내용을 입력하세요.- 필요하다면
QwenImageDiffsynthControlnet노드의strength를 수정해 해당 제어 강도를 조정할 수 있습니다. Run버튼을 클릭하거나, 단축키Ctrl(cmd) + Enter를 사용해 워크플로우를 실행하세요.
Qwen Image Union ControlNet LoRA 워크플로우
Comfy Cloud에서 실행하기 원본 모델 주소: DiffSynth-Studio/Qwen-Image-In-Context-Control-Union Comfy Org 재호스팅 주소: qwen_image_union_diffsynth_lora.safetensors: 캐니, 딥스, 포즈, 라인아트, 소프트엣지, 노말, 오픈포즈 지원 이미지 구조 제어 LoRA1. 워크플로우 및 입력 이미지
아래 이미지를 다운로드해 ComfyUI로 드래그해 워크플로우를 불러오세요.
JSON 형식 워크플로우 다운로드
아래 이미지를 입력으로 다운로드하세요.
2. 모델 링크
아래 모델을 다운로드하세요. 이 모델은 LoRA 모델이므로ComfyUI/models/loras/ 폴더에 저장해야 합니다.
- qwen_image_union_diffsynth_lora.safetensors: 캐니, 딥스, 포즈, 라인아트, 소프트엣지, 노말, 오픈포즈 지원 이미지 구조 제어 LoRA
3. 워크플로우 지침
이 모델은 캐니, 딥스, 포즈, 라인아트, 소프트엣지, 노말, 오픈포즈 제어를 지원하는 통합 제어 LoRA입니다. 많은 이미지 사전 처리 원본 노드가 완벽히 지원되지 않으므로, comfyui_controlnet_aux와 같은 도구를 사용해 다른 이미지 사전 처리를 완료해야 합니다.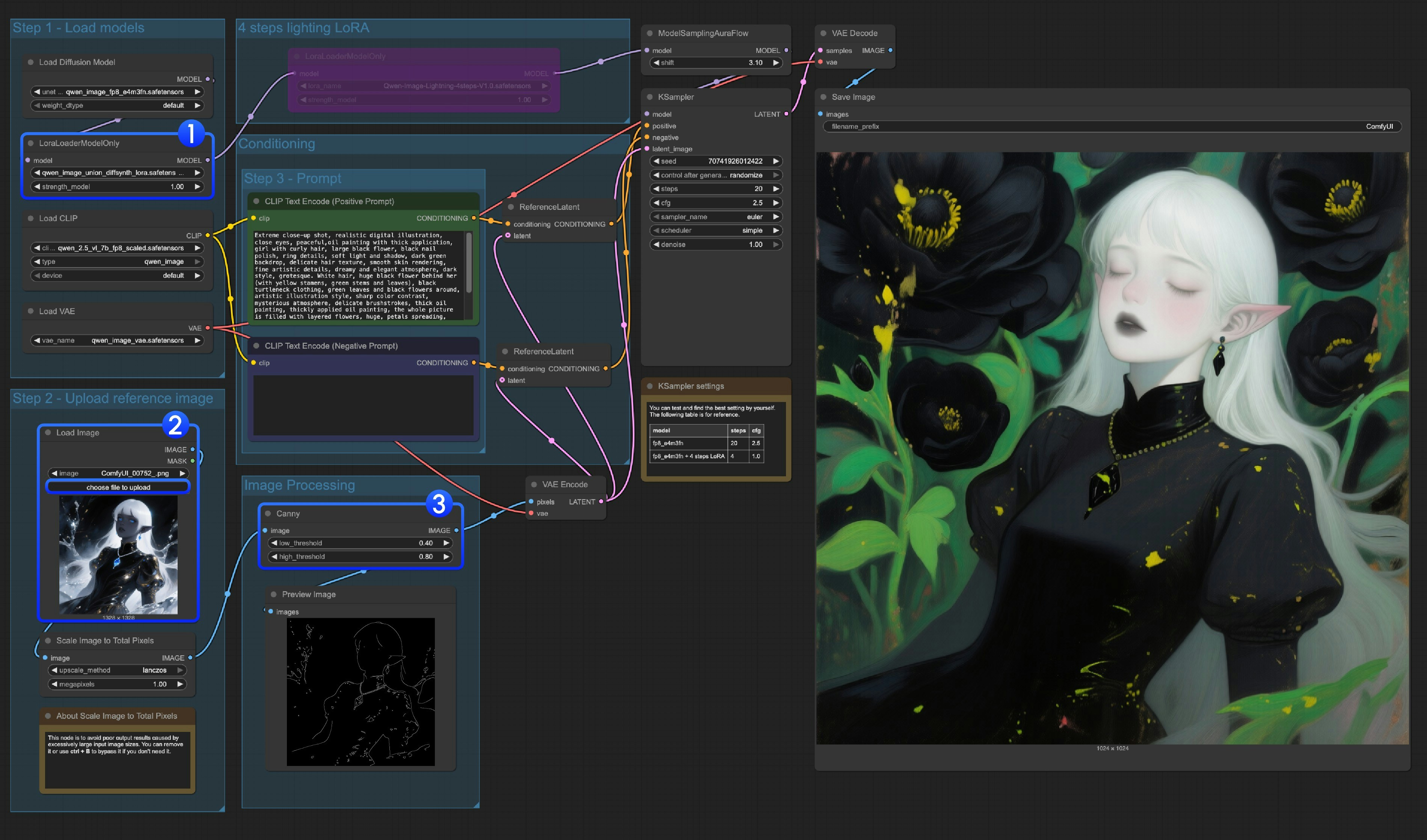
LoraLoaderModelOnly가qwen_image_union_diffsynth_lora.safetensors모델을 정확히 로드했는지 확인하세요.- 입력 이미지를 업로드하세요.
- 필요하다면
Canny노드의 매개변수를 조정할 수 있습니다. 입력 이미지에 따라 더 나은 이미지 사전 처리 결과를 얻으려면 각각의 매개변수 값을 조정해보세요. Run버튼을 클릭하거나, 단축키Ctrl(cmd) + Enter를 사용해 워크플로우를 실행하세요.
다른 종류의 제어를 사용하려면 이미지 처리 부분도 교체해야 합니다.