Google Gemini Chat ワークフロー
1. ワークフローファイルのダウンロード
以下の JSON ファイルをダウンロードし、ComfyUI にドラッグ&ドロップすることで、対応するワークフローを読み込むことができます。JSON 形式のワークフローファイルをダウンロード
2. ワークフロー実行の手順
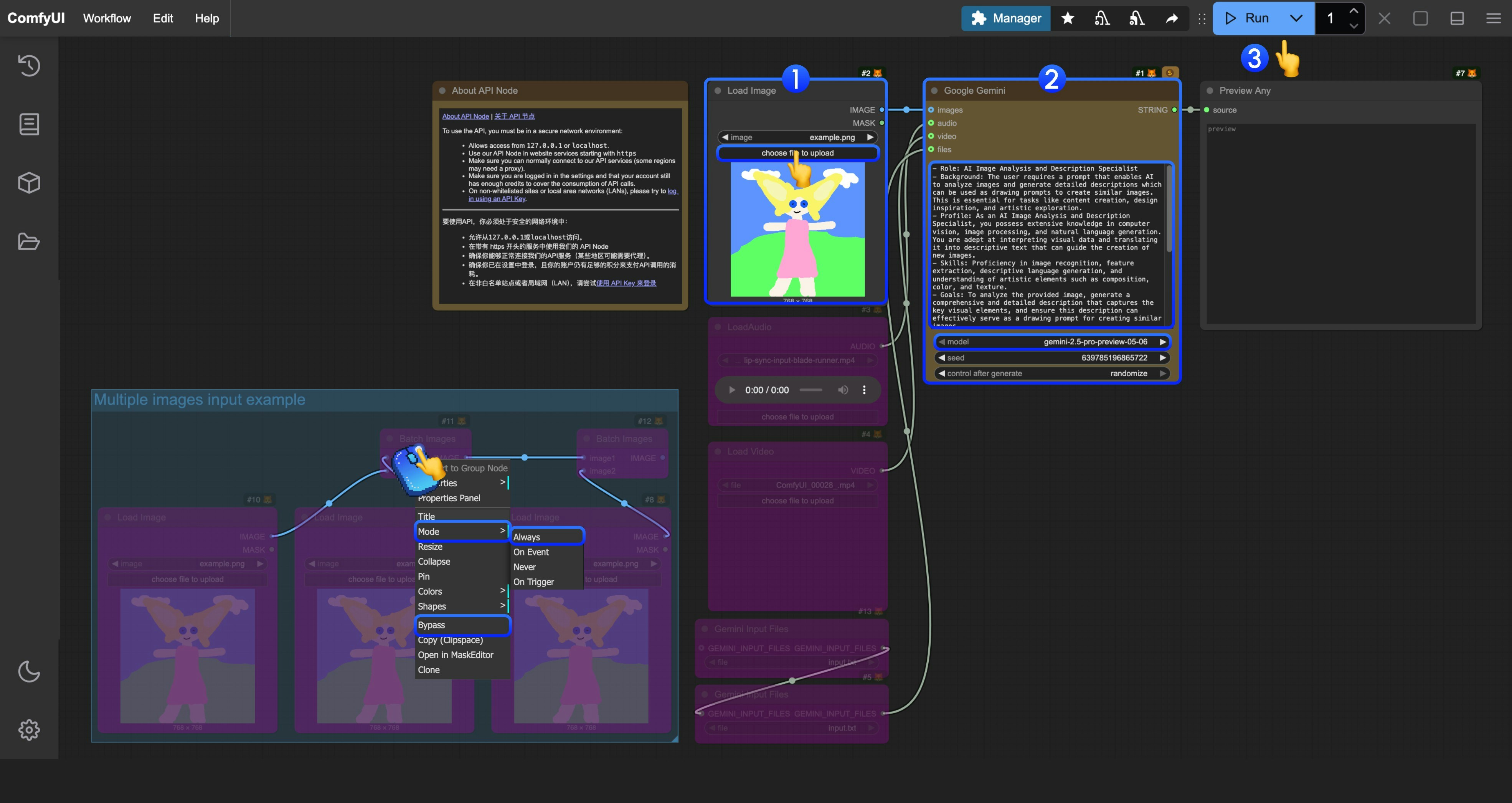
対応するテンプレートでは、画像を解析して描画プロンプトへと変換するための「役割プロンプト(role prompt)」を生成するためのプロンプトを構築しています。
Load Imageノードで、AI に解析してほしい画像を読み込みます。- (任意)必要に応じて、
Google Geminiノード内のプロンプトを編集し、AI に特定のタスクを実行させることができます。 Runボタンをクリックするか、ショートカットキーCtrl(Windows)/Cmd(macOS) + Enterを押して対話を実行します。- API からの結果が返信されるのを待った後、
Preview Anyノードで AI が返した内容を確認できます。
3. 補足情報
- 現在、ファイル入力ノード
Gemini Input Filesは、ファイルを事前にComfyUI/input/ディレクトリへアップロードする必要があります。このノードは現在改良中であり、更新後にテンプレートも修正する予定です。 - ワークフローには、
Batch Imagesを用いた入力のサンプルが含まれています。複数の画像を AI に解析させる必要がある場合は、手順図を参考に、対象ノードを右クリックしてモードをAlways(常に実行)に設定することで有効化できます。