- 오디오 기반 비디오 생성: 정적 이미지와 오디오를 동기화된 비디오로 변환
- 영화급 품질: 자연스러운 표정과 움직임으로 영화 수준의 비디오 생성
- 분 단위 생성: 장편 비디오 제작 지원
- 다양한 형식 지원: 전신 및 반신 캐릭터와 호환
- 향상된 모션 제어: 텍스트 지침으로 액션과 환경 생성
Wan2.2 S2V ComfyUI 네이티브 워크플로우
1. 워크플로우 파일 다운로드
다음 워크플로우 파일을 다운로드하여 ComfyUI에 끌어다 놓으면 워크플로우가 로드됩니다.JSON 워크플로우 다운로드
Comfy Cloud에서 실행
다음 이미지와 오디오를 입력으로 다운로드하세요:
입력 오디오 다운로드
2. 모델 링크
모델들은 우리 리포지토리에서 확인하실 수 있습니다. diffusion_models audio_encoders vae text_encoders3. 워크플로우 지침
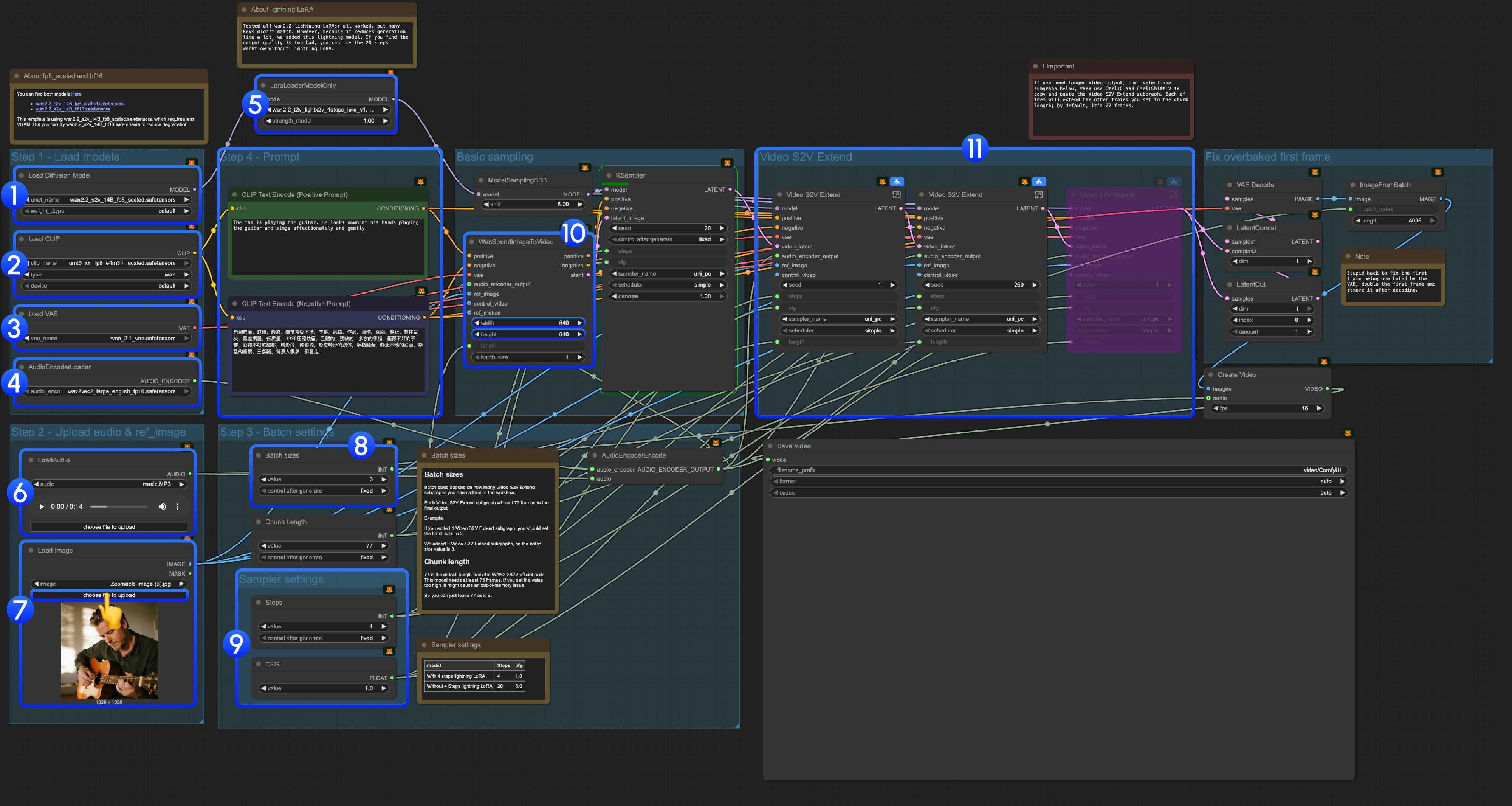
3.1 Lightning LoRA 소개
3.2 fp8_scaled 및 bf16 모델 소개
두 모델 모두 여기에서 확인하실 수 있습니다: 이 템플릿에서는wan2.2_s2v_14B_fp8_scaled.safetensors를 사용하며, 이 모델은 더 적은 VRAM을 필요로 합니다. 하지만 품질 저하를 줄이기 위해 wan2.2_s2v_14B_bf16.safetensors를 시도해볼 수도 있습니다.
3.3 단계별 작동 지침
Step 1: 모델 로드-
Diffusion 모델 로드:
wan2.2_s2v_14B_fp8_scaled.safetensors또는wan2.2_s2v_14B_bf16.safetensors로드- 제공된 워크플로우에서는
wan2.2_s2v_14B_fp8_scaled.safetensors를 사용하며, 이 모델은 더 적은 VRAM을 필요로 합니다. - 하지만 품질 저하를 줄이기 위해
wan2.2_s2v_14B_bf16.safetensors를 시도해볼 수도 있습니다.
- 제공된 워크플로우에서는
-
CLIP 로드:
umt5_xxl_fp8_e4m3fn_scaled.safetensors로드 -
VAE 로드:
wan_2.1_vae.safetensors로드 -
AudioEncoderLoader:
wav2vec2_large_english_fp16.safetensors로드 -
LoraLoaderModelOnly:
wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors(Lightning LoRA) 로드- 우리는 모든 wan2.2 lightning LoRA를 테스트했습니다. 이는 Wan2.2 S2V용으로 특별히 훈련된 LoRA가 아니므로 많은 핵심 값이 맞지 않지만, 생성 시간을 크게 줄여주기 때문에 추가했습니다. 앞으로 이 템플릿을 계속 최적화할 예정입니다.
- 이를 사용하면 상당한 동적 및 품질 손실이 발생합니다.
- 출력 품질이 너무 낮다고 느껴진다면 원래 20단계 워크플로우를 시도해볼 수 있습니다.
- LoadAudio: 제공된 오디오 파일이나 직접 업로드한 오디오를 로드하세요.
- Load Image: 참조 이미지를 업로드하세요.
-
배치 크기: 추가하는 Video S2V Extend 서브그래프 노드 수에 따라 설정하세요.
- 각 Video S2V Extend 서브그래프는 최종 출력에 77프레임을 추가합니다.
- 예를 들어: Video S2V Extend 서브그래프를 2개 추가했다면 배치 크기는 3이어야 하며, 이는 전체 샘플링 반복 횟수를 의미합니다.
- Chunk Length: 기본값인 77을 유지하세요.
-
샘플러 설정: Lightning LoRA 사용 여부에 따라 다른 설정을 선택하세요.
- 4단계 Lightning LoRA 사용 시: steps: 4, cfg: 1.0
- 4단계 Lightning LoRA 미사용 시: steps: 20, cfg: 6.0
- 크기 설정: 출력 비디오의 크기를 설정하세요.
-
Video S2V Extend: 비디오 확장 서브그래프 노드들입니다. 기본 프레임 수가 77이고, 이 모델은 16fps이므로 각 확장은 77 / 16 = 4.8125초의 비디오를 생성합니다.
- 비디오 확장 서브그래프 노드 수를 입력 오디오 길이와 맞추려면 계산이 필요합니다. 예를 들어: 입력 오디오가 14초라면 총 필요한 프레임 수는 14×16=224이며, 각 비디오 확장은 77프레임이므로 224/77 = 2.9, 즉 3개의 비디오 확장 서브그래프 노드가 필요합니다.
- Ctrl-Enter를 누르거나 실행 버튼을 클릭하여 워크플로우를 실행하세요.