Wan 2.2는 WAN AI가 출시한 차세대 멀티모달 생성 모델입니다. 이 모델은 혁신적인 MoE(전문가 혼합) 아키텍처를 채택했으며, 고노이즈 및 저노이즈 전문가 모델로 구성되어 있습니다. 노이즈 제거 단계에 따라 전문가 모델을 나눌 수 있어 더 높은 품질의 비디오 콘텐츠를 생성할 수 있습니다.
Wan 2.2는 세 가지 핵심 기능을 갖추고 있습니다: 영화 수준의 미적 제어, 전문 영화 산업의 미적 기준을 깊이 통합해 조명, 색감, 구도 등 다차원적 시각적 제어를 지원합니다; 대규모 복합 동작, 다양한 복잡한 동작을 쉽게 복원하고 동작의 부드러움과 제어성을 강화합니다; 정밀한 의미적 준수, 복잡한 장면과 다중 객체 생성에 뛰어나 사용자의 창의적 의도를 더욱 잘 살려냅니다.
이 모델은 텍스트 기반 비디오 생성, 이미지 기반 비디오 생성 등 여러 생성 모드를 지원하며, 콘텐츠 제작, 예술 창작, 교육 및 훈련 등 다양한 응용 분야에 적합합니다.
Wan2.2 프롬프트 가이드
모델 주요 특징
- 영화 수준의 미적 제어: 전문적인 카메라 언어, 조명, 색상, 구도 등 다차원적 시각적 제어 지원
- 대규모 복합 동작: 다양한 복잡한 동작을 부드럽게 복원하고, 동작의 제어성과 자연스러움을 향상시킵니다
- 정밀한 의미적 준수: 복잡한 장면 이해, 다중 객체 생성, 창의적 의도를 더욱 잘 살려냅니다
- 효율적인 압축 기술: 고압축률 VAE를 적용한 5B 버전, 메모리 최적화, 혼합 학습 지원
Wan2.2 오픈소스 모델 버전
Wan2.2 시리즈 모델은 Apache 2.0 오픈소스 라이선스를 기반으로 하며 상업적 사용을 지원합니다. Apache 2.0 라이선스는 원본 저작권 표시와 라이선스 텍스트를 유지하는 한, 상업적 목적을 포함해 이러한 모델을 자유롭게 사용, 수정, 배포할 수 있도록 합니다.ComfyOrg Wan2.2 라이브 스트림
ComfyUI Wan2.2 사용법에 대해 라이브 스트림을 진행했으니, 이를 통해 사용 방법을 확인하실 수 있습니다.
이 튜토리얼에서는 🤗 Comfy-Org/Wan_2.2_ComfyUI_Repackaged 버전을 사용하겠습니다.
Wan2.2 TI2V 5B 하이브리드 버전 워크플로우 예시
1. 워크플로우 파일 다운로드
ComfyUI를 최신 버전으로 업데이트하신 후, 메뉴워크플로우 -> 템플릿 탐색 -> 비디오를 통해 “Wan2.2 5B 비디오 생성”을 찾아 워크플로우를 로드하세요.
JSON 워크플로우 파일 다운로드
Comfy Cloud에서 실행
2. 모델 수동 다운로드
디퓨전 모델 VAE 텍스트 인코더3. 단계 따라하기
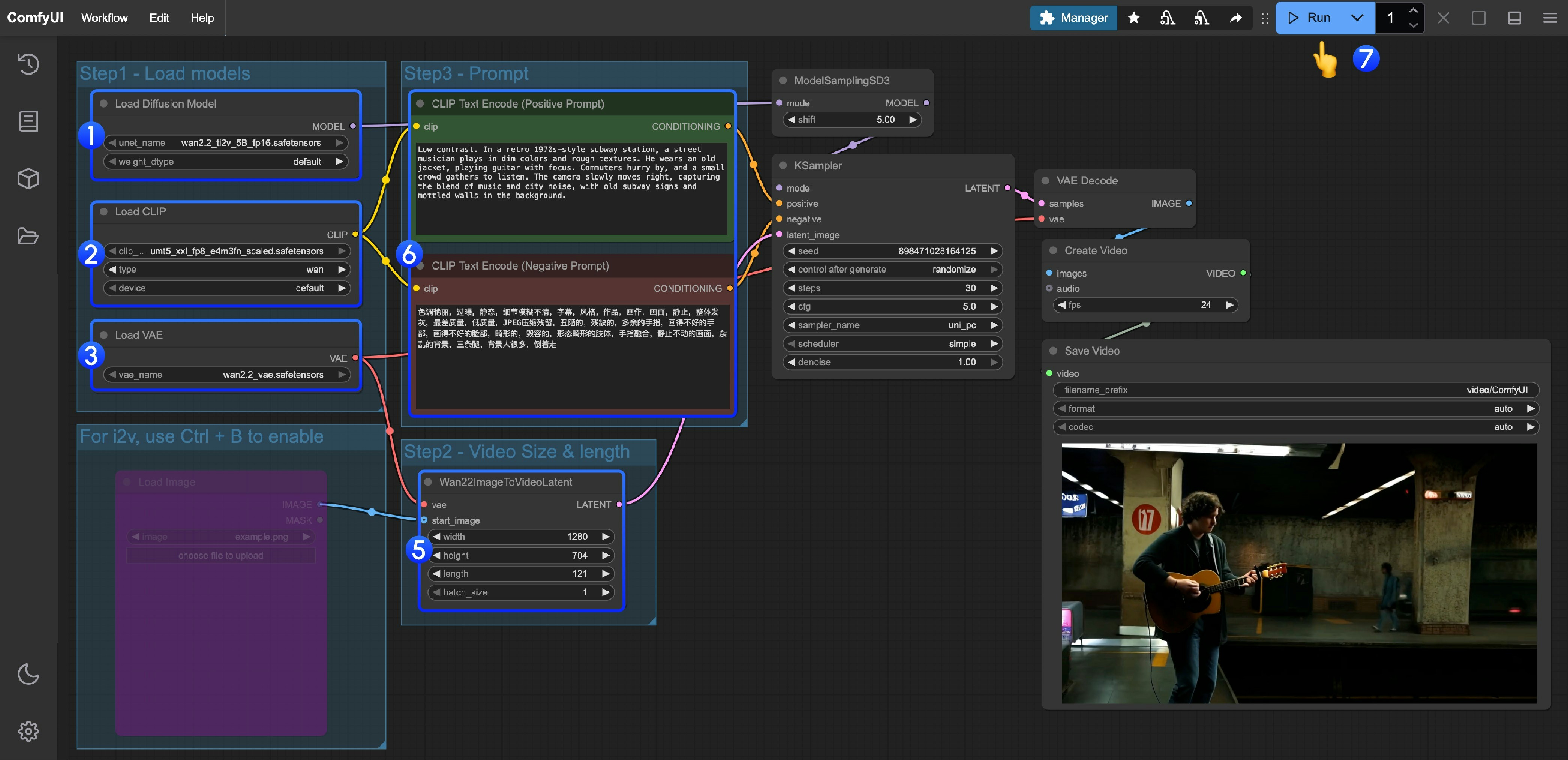
Load Diffusion Model노드가wan2.2_ti2v_5B_fp16.safetensors모델을 로드하도록 설정하세요.Load CLIP노드가umt5_xxl_fp8_e4m3fn_scaled.safetensors모델을 로드하도록 설정하세요.Load VAE노드가wan2.2_vae.safetensors모델을 로드하도록 설정하세요.- (선택) 이미지 기반 비디오 생성이 필요하다면, Ctrl+B 단축키를 사용해
Load image노드를 활성화하여 이미지를 업로드할 수 있습니다. - (선택)
Wan22ImageToVideoLatent노드에서 크기 설정과 전체 비디오 프레임 수(length)를 조정할 수 있습니다. - (선택) 프롬프트(긍정 및 부정)를 수정해야 한다면, 5단계의
CLIP Text Encoder노드에서 직접 수정하세요. Run버튼을 클릭하거나, 단축키Ctrl(cmd) + Enter를 사용해 비디오 생성을 실행하세요.
Wan2.2 14B T2V 텍스트 기반 비디오 생성 워크플로우 예시
1. 워크플로우 파일
ComfyUI를 최신 버전으로 업데이트하신 후, 메뉴워크플로우 -> 템플릿 탐색 -> 비디오를 통해 “Wan2.2 14B T2V”를 찾아 워크플로우를 로드하세요.
또는 ComfyUI를 최신 버전으로 업데이트한 후, 아래 비디오를 다운로드해 ComfyUI로 드래그하여 워크플로우를 로드하세요.
JSON 워크플로우 파일 다운로드
Comfy Cloud에서 실행
2. 모델 수동 다운로드
디퓨전 모델 VAE 텍스트 인코더3. 단계 따라하기
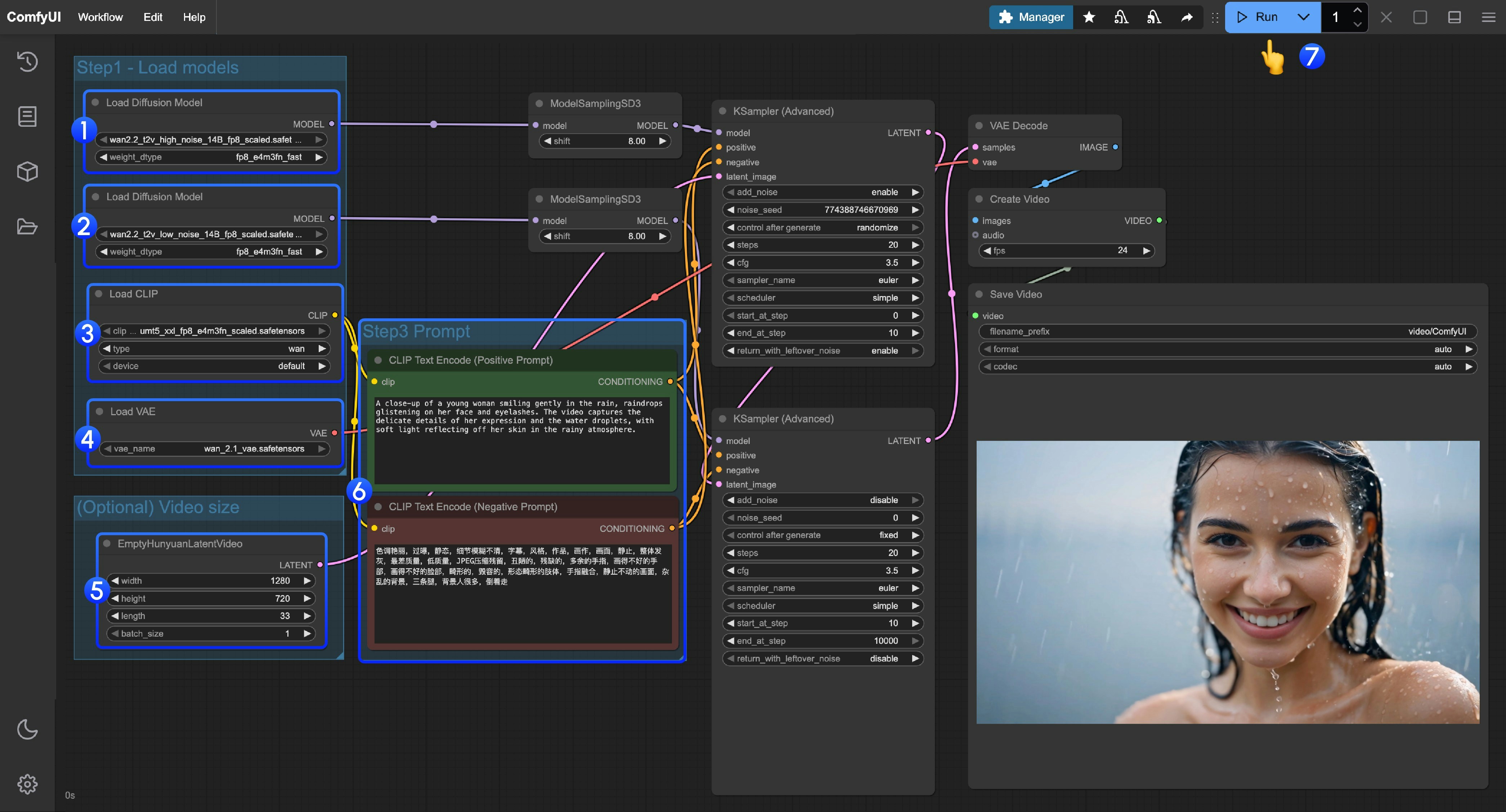
- 첫 번째
Load Diffusion Model노드가wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors모델을 로드하도록 설정하세요. - 두 번째
Load Diffusion Model노드가wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors모델을 로드하도록 설정하세요. Load CLIP노드가umt5_xxl_fp8_e4m3fn_scaled.safetensors모델을 로드하도록 설정하세요.Load VAE노드가wan_2.1_vae.safetensors모델을 로드하도록 설정하세요.- (선택)
EmptyHunyuanLatentVideo노드에서 크기 설정과 전체 비디오 프레임 수(length)를 조정할 수 있습니다. - (선택) 프롬프트(포지티브 및 네거티브)를 수정해야 한다면, 5단계의
CLIP Text Encoder노드에서 직접 수정하세요. Run버튼을 클릭하거나, 단축키Ctrl(cmd) + Enter를 사용해 비디오 생성을 실행하세요.
Wan2.2 14B I2V 이미지 기반 비디오 생성 워크플로 예시
1. 워크플로 파일
ComfyUI를 최신 버전으로 업데이트하신 후, 메뉴워크플로우 -> 템플릿 탐색 -> 비디오를 통해 “Wan2.2 14B I2V”를 찾아 워크플로를 로드하세요.
또는 ComfyUI를 최신 버전으로 업데이트한 후, 아래 비디오를 다운로드해 ComfyUI로 드래그하여 워크플로를 로드하세요.
JSON 워크플로 파일 다운로드
Comfy Cloud에서 실행
다음 이미지를 입력으로 사용할 수 있습니다:
2. 모델 수동 다운로드
디퓨전 모델 VAE 텍스트 인코더3. 단계 따라하기
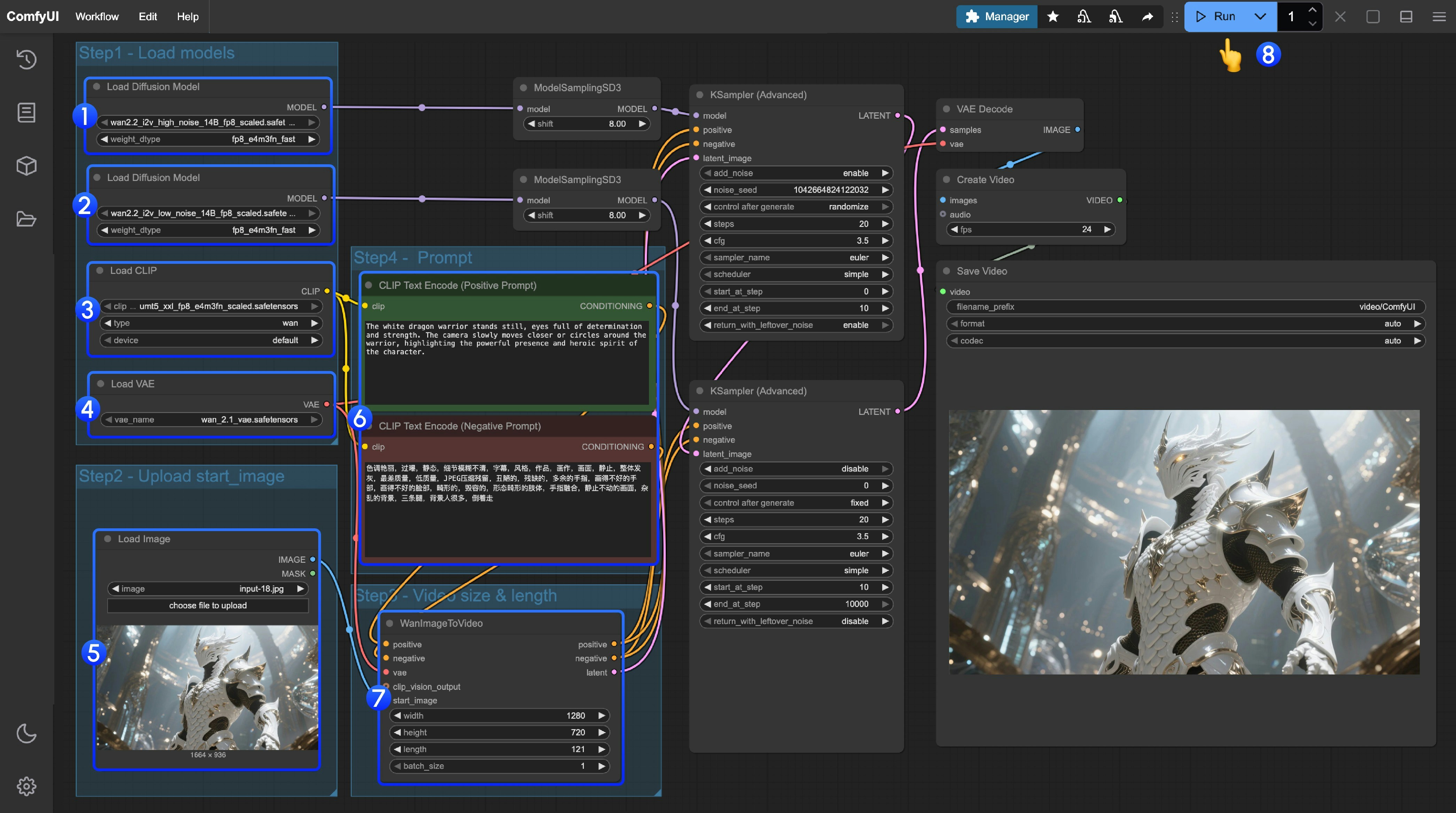
- 첫 번째
Load Diffusion Model노드가wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors모델을 로드하도록 설정하세요. - 두 번째
Load Diffusion Model노드가wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors모델을 로드하도록 설정하세요. Load CLIP노드가umt5_xxl_fp8_e4m3fn_scaled.safetensors모델을 로드하도록 설정하세요.Load VAE노드가wan_2.1_vae.safetensors모델을 로드하도록 설정하세요.Load Image노드에서 초기 프레임으로 사용할 이미지를 업로드하세요.- 프롬프트(긍정 및 부정)를 수정해야 한다면, 6단계의
CLIP Text Encoder노드에서 수정하세요. - (선택)
EmptyHunyuanLatentVideo에서 크기 설정과 전체 비디오 프레임 수(length)를 조정할 수 있습니다. Run버튼을 클릭하거나, 단축키Ctrl(cmd) + Enter를 사용해 비디오 생성을 실행하세요.
Wan2.2 14B FLF2V 워크플로 예시
첫 번째와 마지막 프레임 워크플로는 I2V 섹션과 동일한 모델 위치를 사용합니다.1. 워크플로 및 입력 자료 준비
아래 비디오 또는 JSON 워크플로를 다운로드해 ComfyUI에서 열어주세요.JSON 워크플로 다운로드
Comfy Cloud에서 실행
다음 이미지를 입력 자료로 다운로드하세요:

2. 단계 따라하기
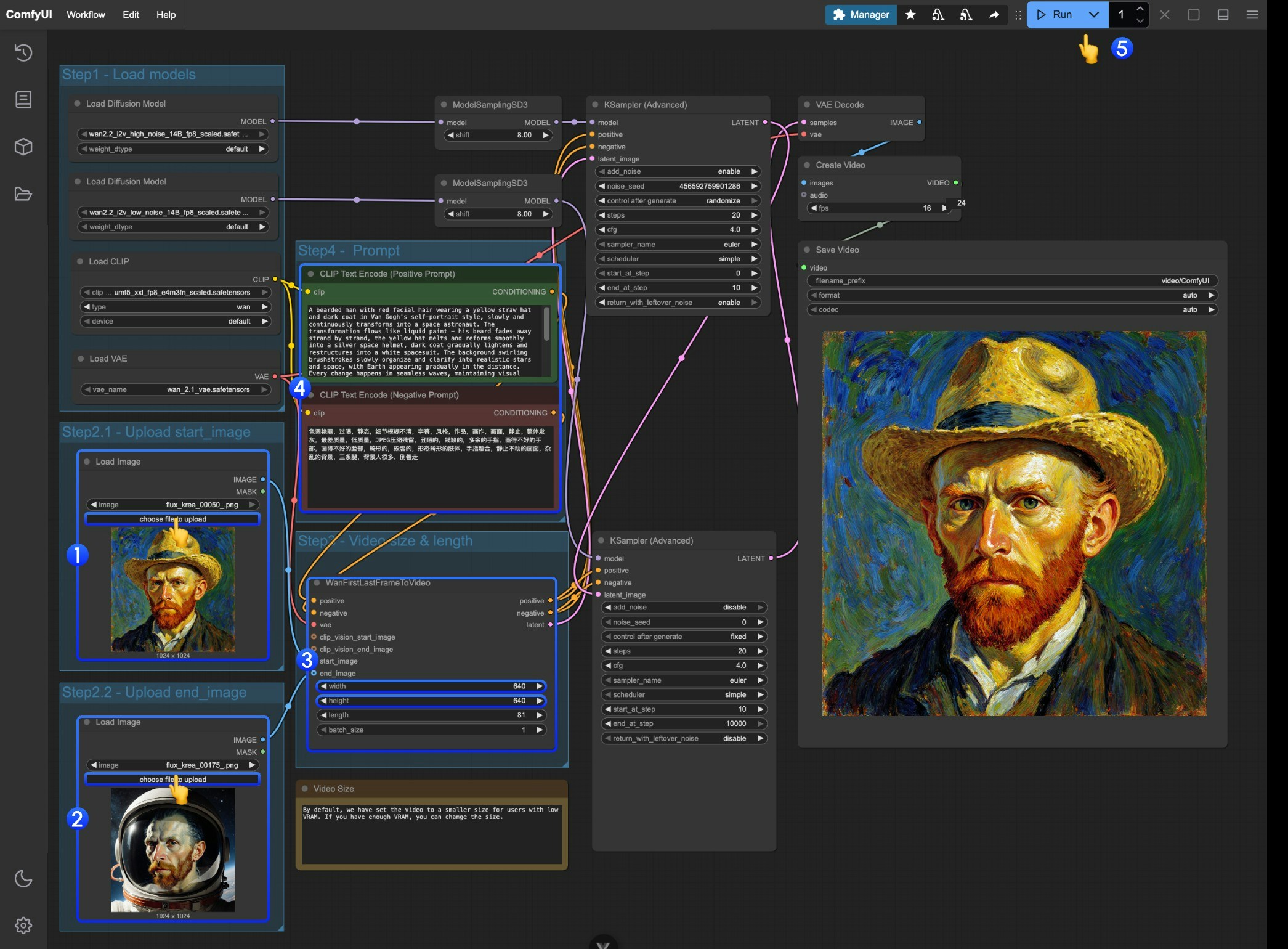
- 첫 번째
Load Image노드에서 시작 프레임으로 사용할 이미지를 업로드하세요. - 두 번째
Load Image노드에서 끝 프레임으로 사용할 이미지를 업로드하세요. WanFirstLastFrameToVideo노드에서 크기 설정을 조정하세요.- 기본적으로 비교적 작은 크기가 설정되어 있어 낮은 VRAM 사용자가 너무 많은 리소스를 소모하지 않도록 합니다.
- VRAM이 충분하다면 720P 정도의 해상도를 시도해볼 수 있습니다.
- 첫 번째와 마지막 프레임에 맞춰 적절한 프롬프트를 작성하세요.
Run버튼을 클릭하거나, 단축키Ctrl(cmd) + Enter를 사용해 비디오 생성을 실행하세요.