ACE-Step ComfyUI Text-to-Audio Generation Workflow Example
1. Download Workflow and Related Models
Click the button below to download the corresponding workflow file. Drag it into ComfyUI to load the workflow information. The workflow includes model download information.Download Json Format Workflow File
You can also manually download ace_step_v1_3.5b.safetensors and save it to theComfyUI/models/checkpoints folder
2. Complete the Workflow Step by Step
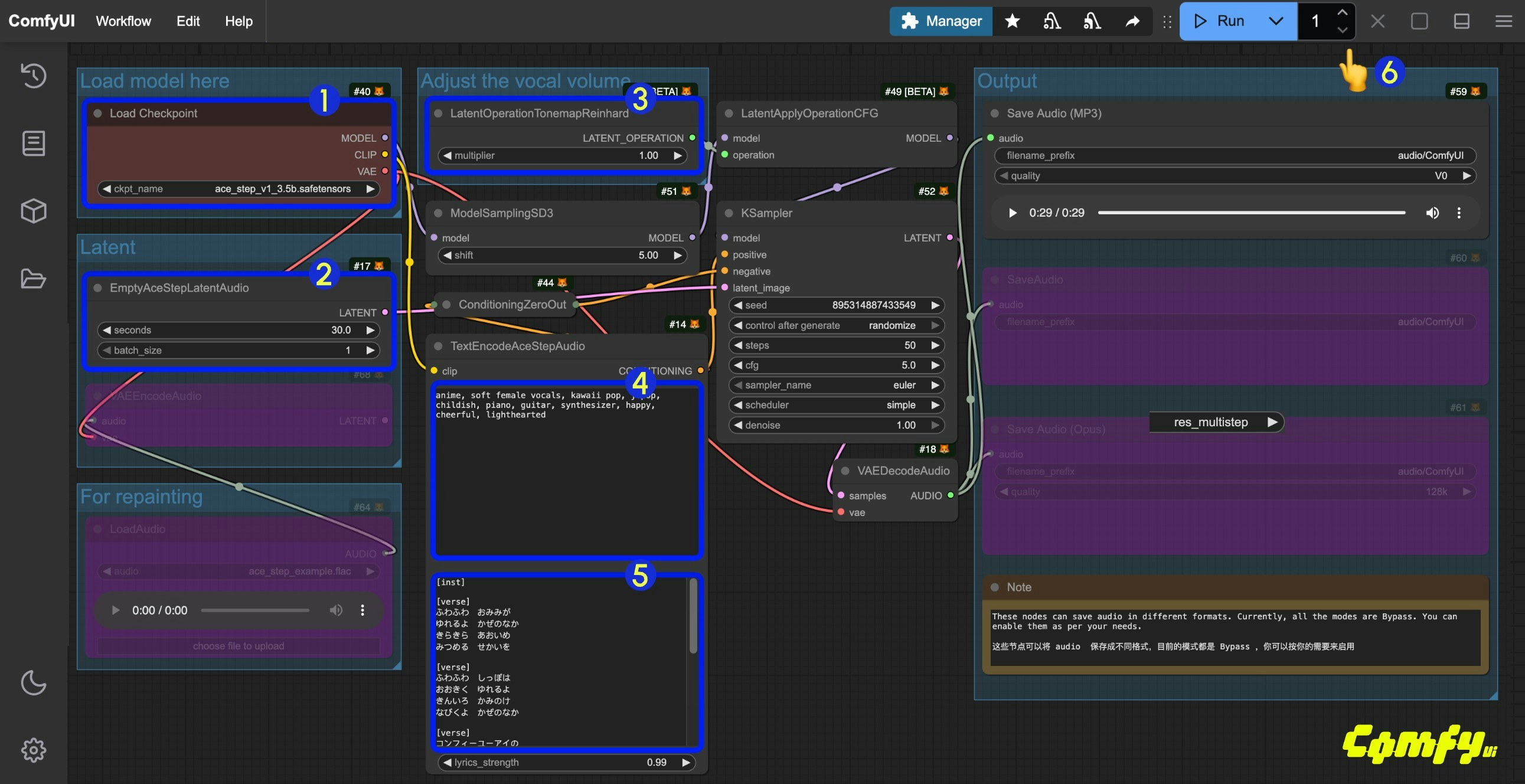
- Ensure the
Load Checkpointsnode has loaded theace_step_v1_3.5b.safetensorsmodel - (Optional) In the
EmptyAceStepLatentAudionode, you can set the duration of the music to be generated - (Optional) In the
LatentOperationTonemapReinhardnode, you can adjust themultiplierto control the volume of the vocals (higher numbers result in more prominent vocals) - (Optional) Input corresponding music styles etc. in the
tagsfield ofTextEncodeAceStepAudio - (Optional) Input corresponding lyrics in the
lyricsfield ofTextEncodeAceStepAudio - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute the audio generation - After the workflow completes,, you can preview the generated audio in the
Save Audionode. You can click to play and listen to it, and the audio will also be saved toComfyUI/output/audio(subdirectory determined by theSave Audionode).
ACE-Step ComfyUI Audio-to-Audio Workflow
Similar to image-to-image workflows, you can input a piece of music and use the workflow below to resample and generate music. You can also adjust the difference from the original audio by controlling thedenoise parameter in the Ksampler.
1. Download Workflow File
Click the button below to download the corresponding workflow file. Drag it into ComfyUI to load the workflow information.Download Json Format Workflow File
Download the following audio file as the input audio:Download Example Audio File for Input
2. Complete the Workflow Step by Step
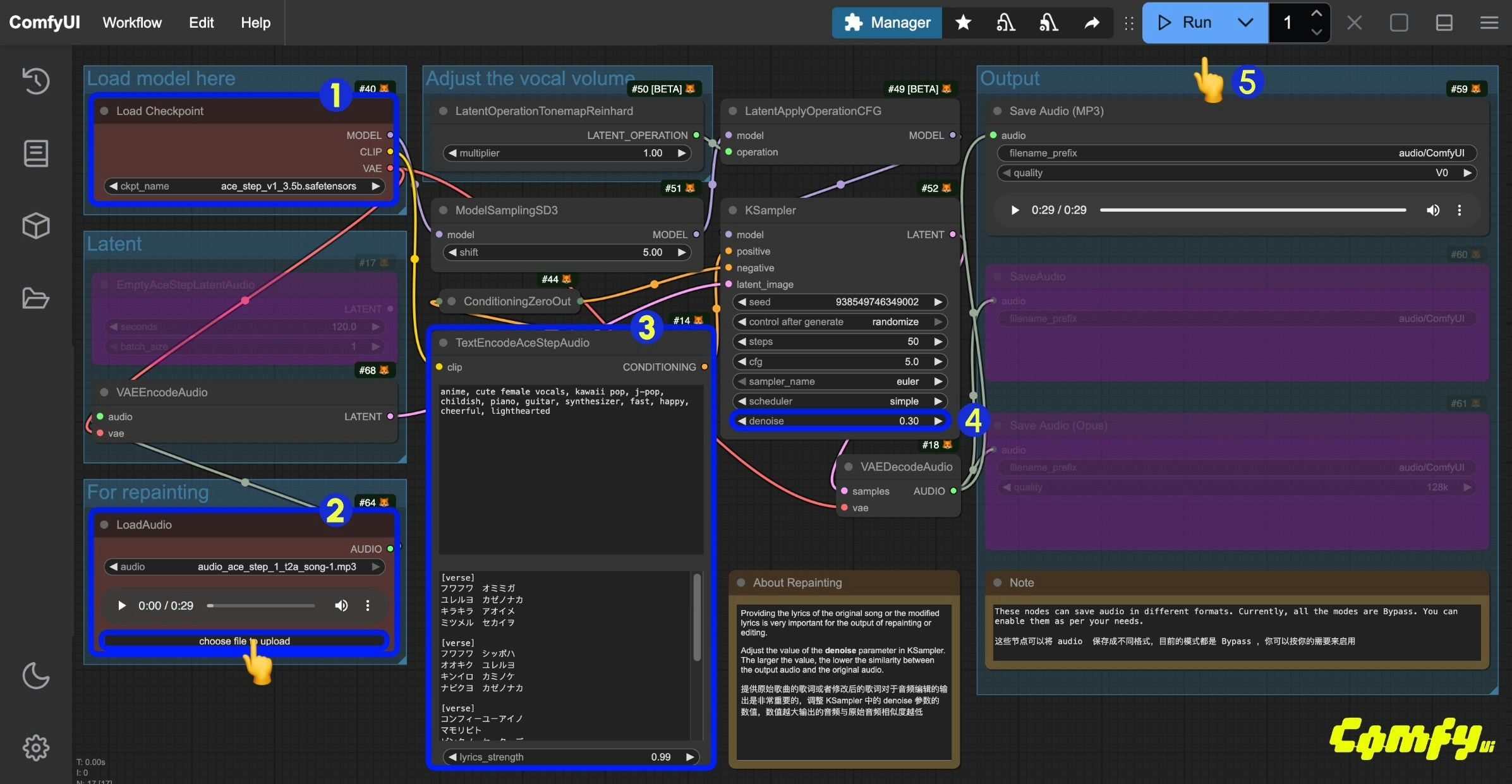
- Ensure the
Load Checkpointsnode has loaded theace_step_v1_3.5b.safetensorsmodel - Upload the provided audio file in the
LoadAudionode - (Optional) Input corresponding music styles and lyrics in the
tagsandlyricsfields ofTextEncodeAceStepAudio. Providing lyrics is very important for audio editing - (Optional) Modify the
denoiseparameter in theKsamplernode to adjust the noise added during sampling to control similarity with the original audio (smaller values result in more similarity to the original audio; setting it to1.00is approximately equivalent to having no audio input) - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute the audio generation - After the workflow completes, you can preview the generated audio in the
Save Audionode. You can click to play and listen to it, and the audio will also be saved toComfyUI/output/audio(subdirectory determined by theSave Audionode).
3. Additional Workflow Notes
- In the example workflow, you can change the
tagsinTextEncodeAceStepAudiofrommale voicetofemale voiceto generate female vocals. - You can also modify the
lyricsinTextEncodeAceStepAudioto change the lyrics and thus the generated audio. Refer to the examples on the ACE-Step project page for more details.
ACE-Step Prompt Guide
ACE currently uses two types of prompts:tags and lyrics.
tags: Mainly used to describe music styles, scenes, etc. Similar to prompts we use for other generations, they primarily describe the overall style and requirements of the audio, separated by English commaslyrics: Mainly used to describe lyrics, supporting lyric structure tags such as [verse], [chorus], and [bridge] to distinguish different parts of the lyrics. You can also input instrument names for purely instrumental music
tags and lyrics on the ACE-Step model homepage. You can refer to these examples to try corresponding prompts. This document’s prompt guide is organized based on the project to help you quickly try combinations to achieve your desired effect.
Tags (prompt)
Mainstream Music Styles
Use short tag combinations to generate specific music styles- electronic
- rock
- pop
- funk
- soul
- cyberpunk
- Acid jazz
- electro
- em (electronic music)
- soft electric drums
- melodic
Scene Types
Combine specific usage scenarios and atmospheres to generate music that matches the corresponding mood- background music for parties
- radio broadcasts
- workout playlists
Instrumental Elements
- saxophone
- jazz
- piano, violin
Vocal Types
- female voice
- male voice
- clean vocals
Professional Terms
Use some professional terms commonly used in music to precisely control music effects- 110 bpm (beats per minute is 110)
- fast tempo
- slow tempo
- loops
- fills
- acoustic guitar
- electric bass
Lyrics
Lyric Structure Tags
- [outro]
- [verse]
- [chorus]
- [bridge]
Multilingual Support
- ACE-Step V1 supports multiple languages. When used, ACE-Step converts different languages into English letters and then generates music.
- In ComfyUI, we haven’t fully implemented the conversion of all languages to English letters. Currently, only Japanese hiragana and katakana characters are implemented.
So if you need to use multiple languages for music generation, you need to first convert the corresponding language to English letters, and then input the language code abbreviation at the beginning of the
lyrics, such as Chinese[zh], Korean[ko], etc.
- English
- Chinese: [zh]
- Russian: [ru]
- Spanish: [es]
- Japanese: [ja]
- German: [de]
- French: [fr]
- Portuguese: [pt]
- Italian: [it]
- Korean: [ko]
The language tags above have not been fully tested at the time of writing this documentation. If any language tag is incorrect, please submit an issue to our documentation repository and we will make timely corrections.