テキストから音声への変換(Text-to-Audio)ワークフロー
テキストから音声への変換では、テキストプロンプトを用いて音声を生成します。生成したい音楽を具体的に記述する必要があります。JSON ワークフローをダウンロード
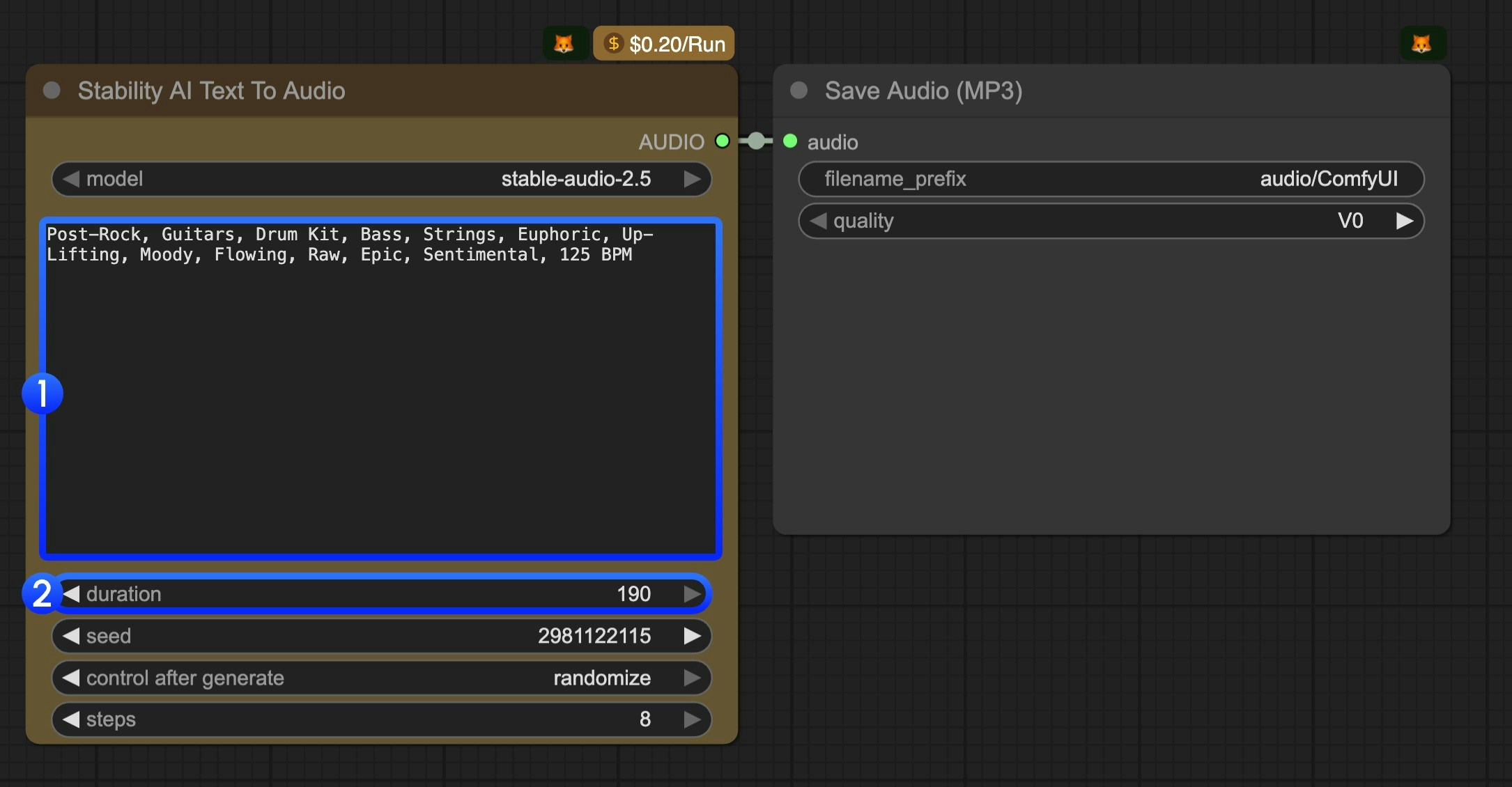
- テキストプロンプトを編集します。生成したい音楽を表すキーワードを用いて記述してください。
- (任意)
durationパラメーターを編集します。デフォルト値は190です。 Runボタンをクリックするか、ショートカットキーCtrl(Cmd)+ Enterを使用して音声生成を実行します。生成された音声はComfyUI/output/audioディレクトリに保存されます。
音声から音声への変換(Audio-to-Audio)ワークフロー
音声から音声への変換は、基本的に音楽の再サンプリングです。指定した音声から新しい音楽を生成したり、単にメロディーをハミングして入力し、モデルがその入力音声に基づいて新たな音楽を生成するといった使い方が可能です。JSON ワークフローをダウンロード
入力音声をダウンロード
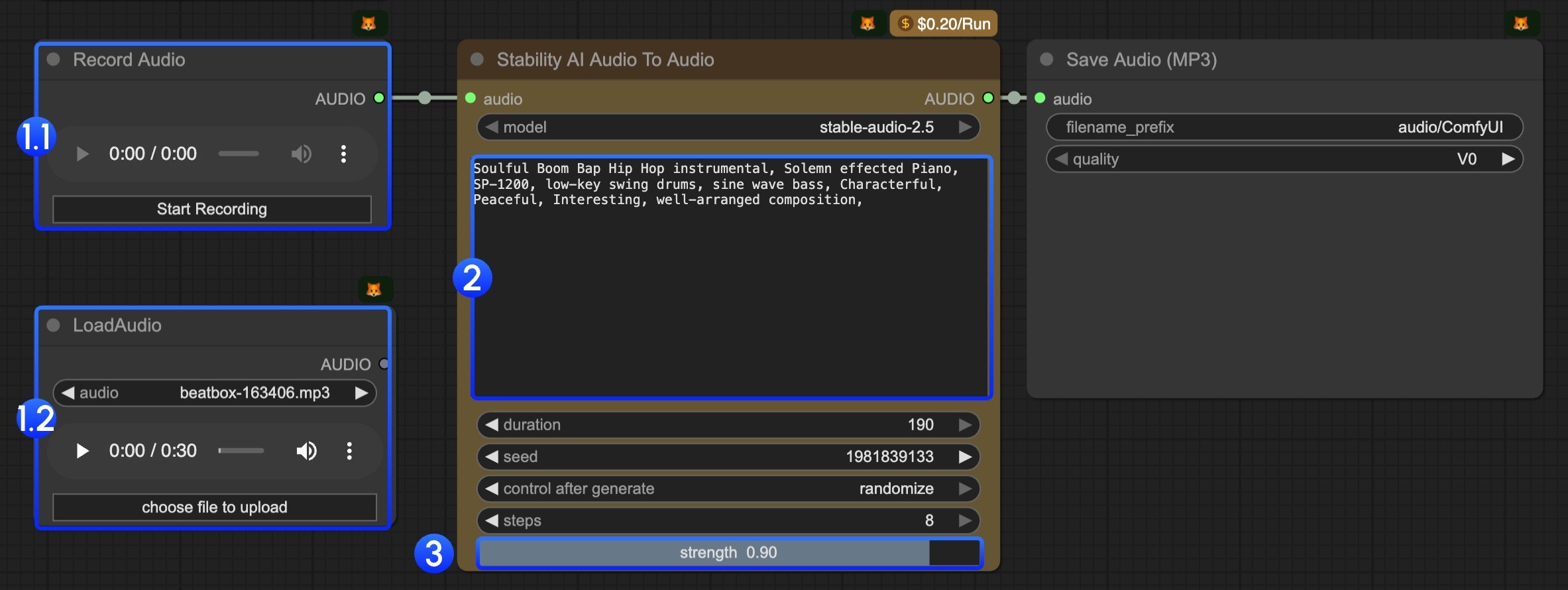
- このワークフローでは、編集対象の音声(最低6秒以上)を入力するための2つのノードを用意しています:
- 1.1
Record Audioノード:ハミングしたメロディーなど、ご自身の音楽アイデアを録音するためにご利用いただけます(最低6秒以上必要です)。 - 1.2
LoadAudioノード:このワークフローで使用する音声ファイルをアップロードするためにご利用いただけます。
- 1.1
- テキストプロンプトを編集します。生成したい音楽を表すキーワードを用いて記述してください。
strengthパラメーターは、元の音声との差異を制御するために使用されます。値が小さいほど、生成された音声は元の音声に近くなります。Runボタンをクリックするか、ショートカットキーCtrl(Cmd)+ Enterを使用して音声生成を実行します。生成された音声はComfyUI/output/audioディレクトリに保存されます。
音声修復(Audio Inpainting)ワークフロー
音声修復は、既存のトラックを完成または延長するために使用されます。たとえば、音楽の欠落部分を補完したり、音楽の再生時間を延長したりする場合に活用できます。 修復を開始および終了させる位置を設定する必要があります。JSON ワークフローをダウンロード
入力音声をダウンロード
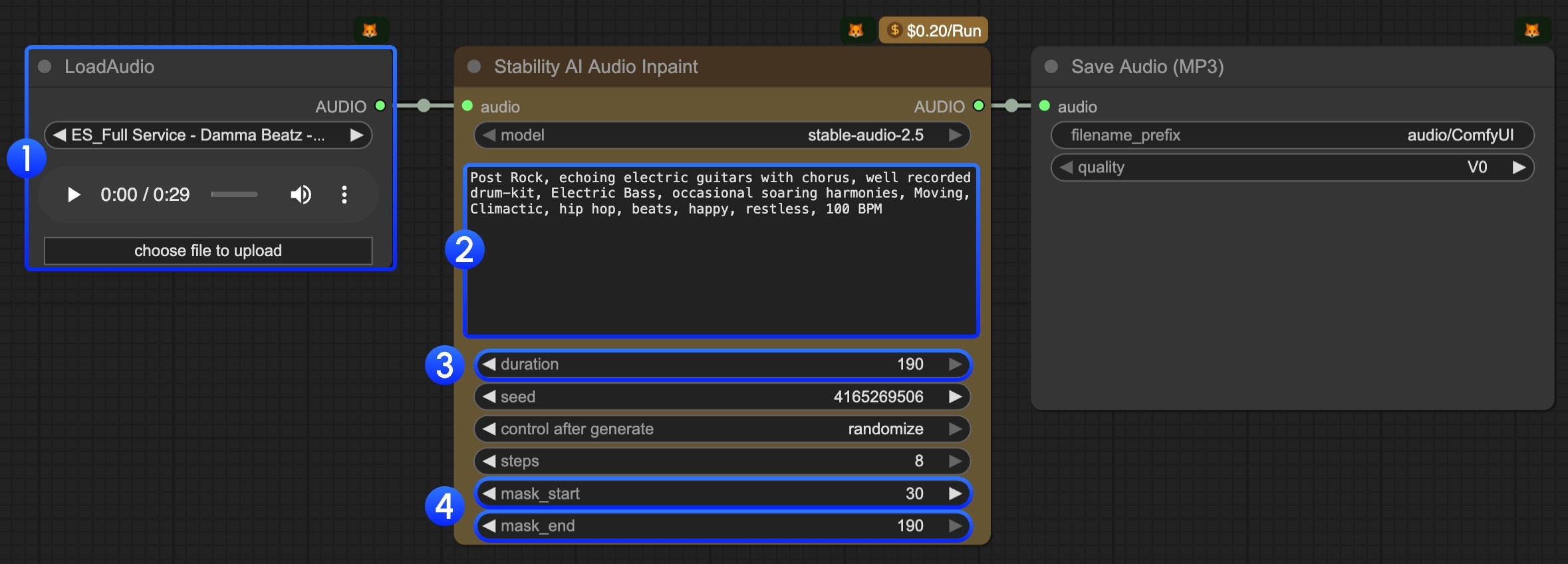
LoadAudioノードに音声ファイルをアップロードします。- テキストプロンプトを編集します。生成したい音楽を表すキーワードを用いて記述してください。
- (任意)
durationパラメーターを編集します。デフォルト値は190です。 - (重要)
mask_startおよびmask_endパラメーターを編集します。修復を開始および終了させる位置を設定する必要があります。 Runボタンをクリックするか、ショートカットキーCtrl(Cmd)+ Enterを使用して音声生成を実行します。生成された音声はComfyUI/output/audioディレクトリに保存されます。