关于 Wan2.1-Fun-InP
Wan-Fun InP 是阿里巴巴推出的开源视频生成模型,属于 Wan2.1-Fun 系列的一部分,专注于通过图像生成视频并实现首尾帧控制。
核心功能:
- 首尾帧控制:支持输入首帧和尾帧图像,生成中间过渡视频,提升视频连贯性与创意自由度。相比早期社区版本,阿里官方模型的生成效果更稳定且质量显著提升。
- 多分辨率支持:支持生成512×512、768×768、1024×1024等分辨率的视频,适配不同场景需求。
模型版本方面:
- 1.3B 轻量版:适合本地部署和快速推理,对显存要求较低
- 14B 高性能版:模型体积达 32GB+,效果更优但需高显存支持
下面是相关模型权重和代码仓库:
请确保你的 ComfyUI 已经更新。本指南里的工作流可以在 ComfyUI 的工作流模板中找到。如果找不到,可能是 ComfyUI 没有更新。如果加载工作流时有节点缺失,可能原因有:
- 你用的不是最新开发版(nightly)。
- 你用的是稳定版或桌面版(没有包含最新的更新)。
- 启动时有些节点导入失败。
- 桌面版是基于 ComfyUI 稳定版本构建的,它会在有新的桌面稳定版本发布时自动更新。
- Cloud 会在 ComfyUI 稳定版本发布后更新,我们会同步更新 Cloud。
所以,如果你发现本教程中有任何核心节点缺失,那是因为对应的节点支持还在开发中没有发布正式的稳定版,请等待下一个稳定版本发布。目前 ComfyUI 已原生支持了 Wan2.1 Fun InP 模型,在开始本篇教程前,请更新你的 ComfyUI 保证你的版本在这个提交版本之后 Wan2.1 Fun Control 工作流
下载下面的图片,并拖入 ComfyUI 中以加载对应的工作流

1. 工作流文件下载
2. 手动模型安装
如果对应的自动模型下载无效,请手动进行模型下载,并保存到对应的文件夹
下面的模型你可以在 Wan_2.1_ComfyUI_repackaged 和 Wan2.1-Fun 找到
Diffusion models 选择 1.3B 或 14B, 14B 的文件体积更大(32GB)但是对于运行显存要求也较高,
Text encoders 选择下面两个模型中的一个,fp16 精度体积较大对性能要求高
VAE
CLIP Vision
文件保存位置
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── wan2.1_fun_inp_1.3B_bf16.safetensors
│ ├── 📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └── 📂 vae/
│ │ └── wan_2.1_vae.safetensors
│ └── 📂 clip_vision/
│ └── clip_vision_h.safetensors
3. 按步骤完成工作流
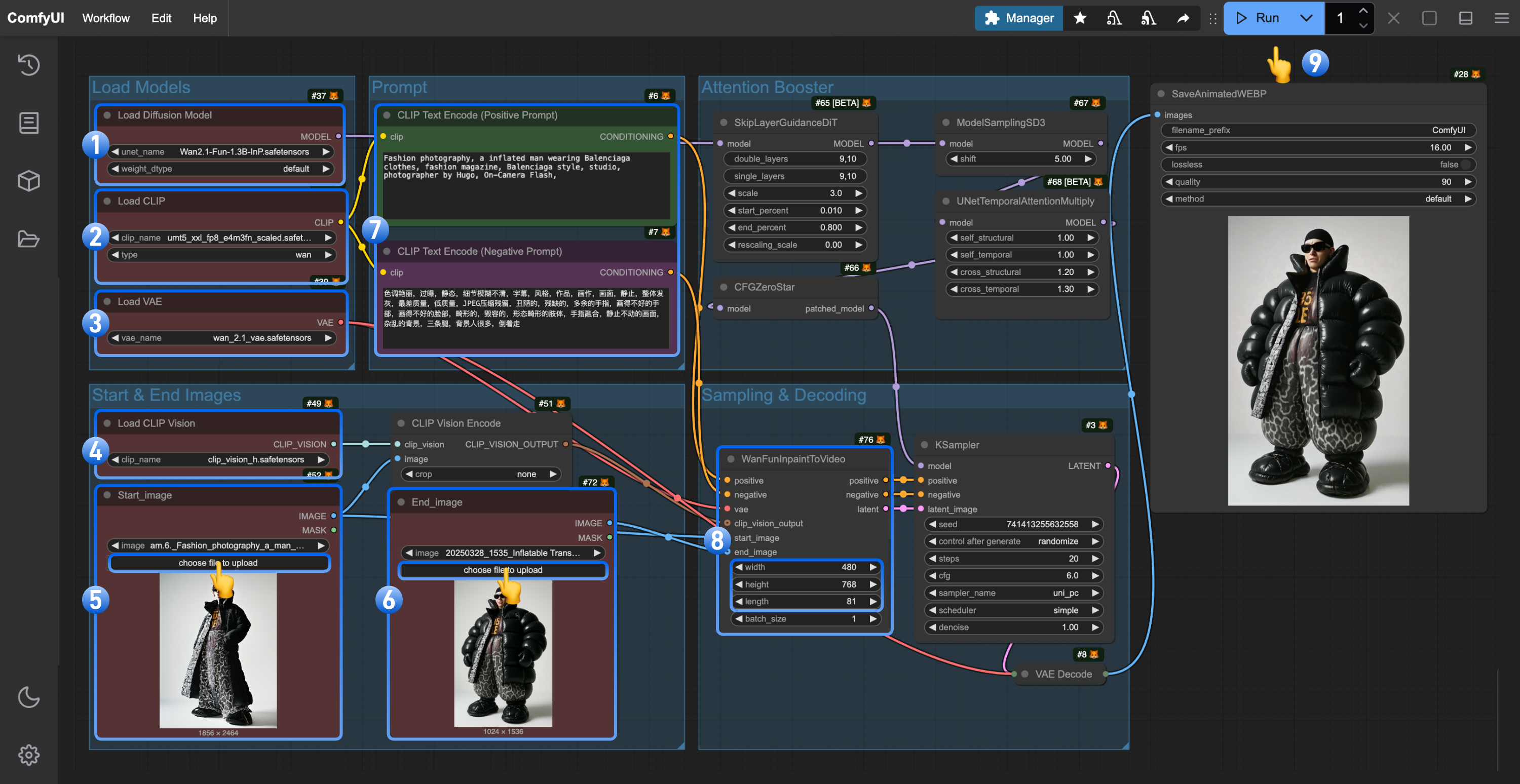
- 确保
Load Diffusion Model 节点加载了 wan2.1_fun_inp_1.3B_bf16.safetensors
- 确保
Load CLIP 节点加载了 umt5_xxl_fp8_e4m3fn_scaled.safetensors
- 确保
Load VAE 节点加载了 wan_2.1_vae.safetensors
- 确保
Load CLIP Vision 节点加载了 clip_vision_h.safetensors
- 在
Load Image 节点(已被重命名为Start_image) 上传起始帧
- 在第二个
Load Image 节点上传用于控制视频。注意: 目前这个节点还不支持 mp4 只能使用 Webp 视频
- (可选)修改 Prompt 使用中英文都可以
- (可选)在
WanFunInpaintToVideo 修改对应视频的尺寸,不要使用过大的尺寸
- 点击
Run 按钮,或者使用快捷键 Ctrl(cmd) + Enter(回车) 来执行视频生成
4. 工作流说明
请注意要使用正确的模型,因为 wan2.1_fun_inp_1.3B_bf16.safetensors 和 wan2.1_fun_control_1.3B_bf16.safetensors 都保存在同一文件夹,同时名称又极为相似,请确保使用了正确的模型。
- 在体验 Wan Fun InP 时,你可能需要频繁修改提示词,从而来确保对应画面的过渡的准确性
其它 Wan2.1 Fun Inp 或者视频相关自定义节点