Wan2.1 ComfyUI 原生(native)工作流示例
模型安装
本篇指南涉及的所有模型你都可以在这里找到, 下面是本篇示例中将会使用到的共用的模型,你可以提前进行下载: 从Text encoders 选择一个版本进行下载, VAE CLIP Vision 文件保存位置对于 diffusion 模型,我们在本篇示例中将使用 fp16 精度的模型,因为我们发现相对于 bf16 的版本 fp16 版本的效果更好,如果你需要其它精度的版本,请访问这里进行下载
Wan2.1 文生视频工作流
在开始工作流前请下载 wan2.1_t2v_1.3B_fp16.safetensors,并保存到ComfyUI/models/diffusion_models/ 目录下。
如果你需要其它的 t2v 精度版本,请访问这里进行下载
1. 工作流文件下载
下载下面的文件,并拖入 ComfyUI 以加载对应的工作流
2. 按流程完成工作流运行
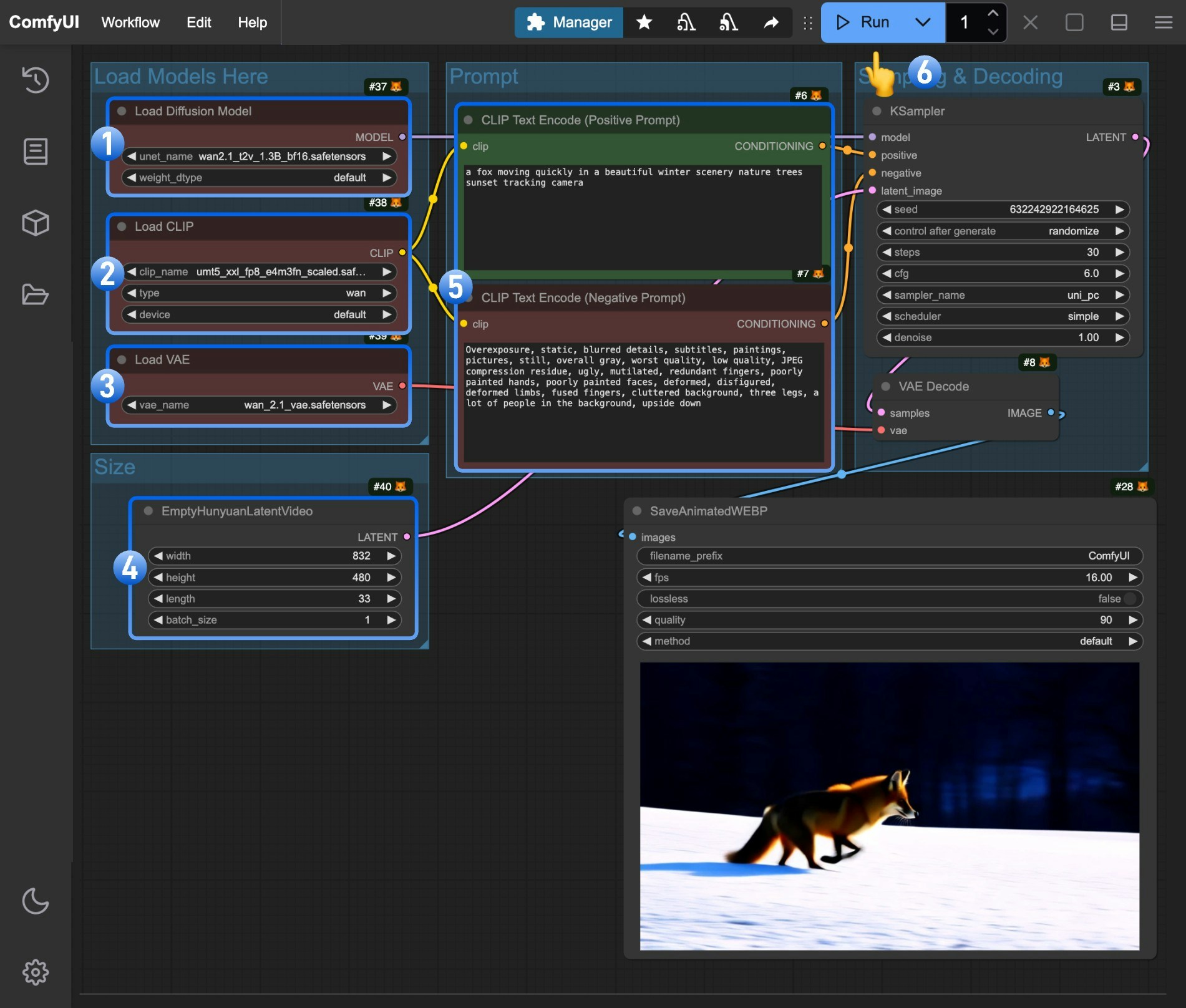
- 确保
Load Diffusion Model节点加载了wan2.1_t2v_1.3B_fp16.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - (可选)可以在
EmptyHunyuanLatentVideo节点设置了视频的尺寸,如果有需要你可以修改 - (可选)如果你需要修改提示词(正向及负向)请在序号
5的CLIP Text Encoder节点中进行修改 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
Wan2.1 图生视频工作流
由于 Wan Video 将 480P 和 720P 的模型分开 ,所以在本篇中我们将需要分别对两中清晰度的视频做出示例,除了对应模型不同之外,他们还有些许的参数差异480P 版本
1. 工作流及输入图片
下载下面的图片,并拖入 ComfyUI 中来加载对应的工作流 我们将使用下面的图片作为输入:
我们将使用下面的图片作为输入:

2. 模型下载
请下载wan2.1_i2v_480p_14B_fp16.safetensors,并保存到ComfyUI/models/diffusion_models/ 目录下
3. 按步骤完成工作流的运行
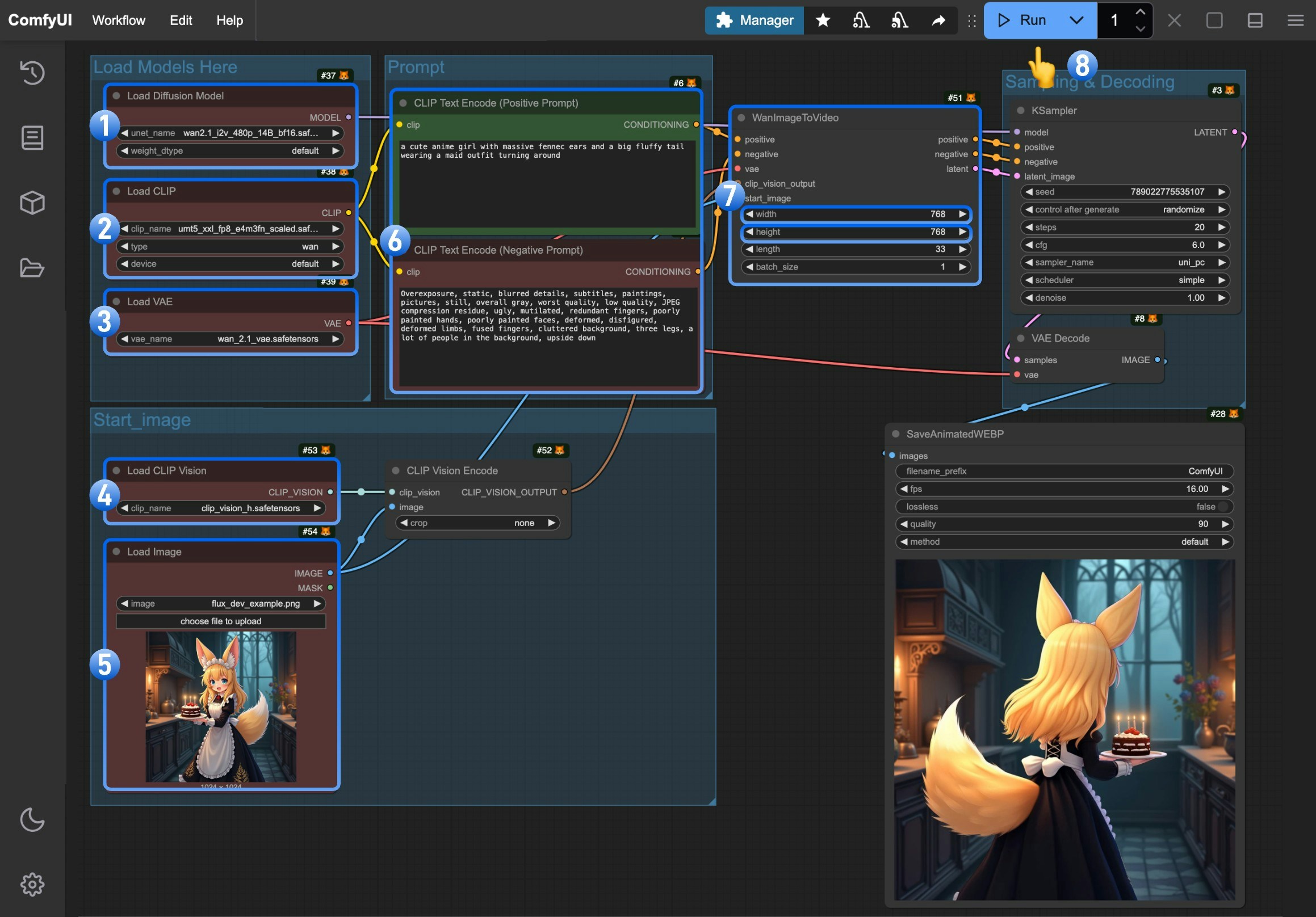
- 确保
Load Diffusion Model节点加载了wan2.1_i2v_480p_14B_fp16.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 确保
Load CLIP Vision节点加载了clip_vision_h.safetensors模型 - 在
Load Image节点中上传我们提供的输入图片 - (可选)在
CLIP Text Encoder节点中输入你想要生成的视频描述内容, - (可选)在
WanImageToVideo节点中设置了视频的尺寸,如果有需要你可以修改 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
720P 版本
1. 工作流及输入图片
下载下面的图片,并拖入 ComfyUI 中来加载对应的工作流 我们将使用下面的图片作为输入:
我们将使用下面的图片作为输入:

2. 模型下载
请下载wan2.1_i2v_720p_14B_fp16.safetensors,并保存到ComfyUI/models/diffusion_models/ 目录下
3. 按步骤完成工作流的运行
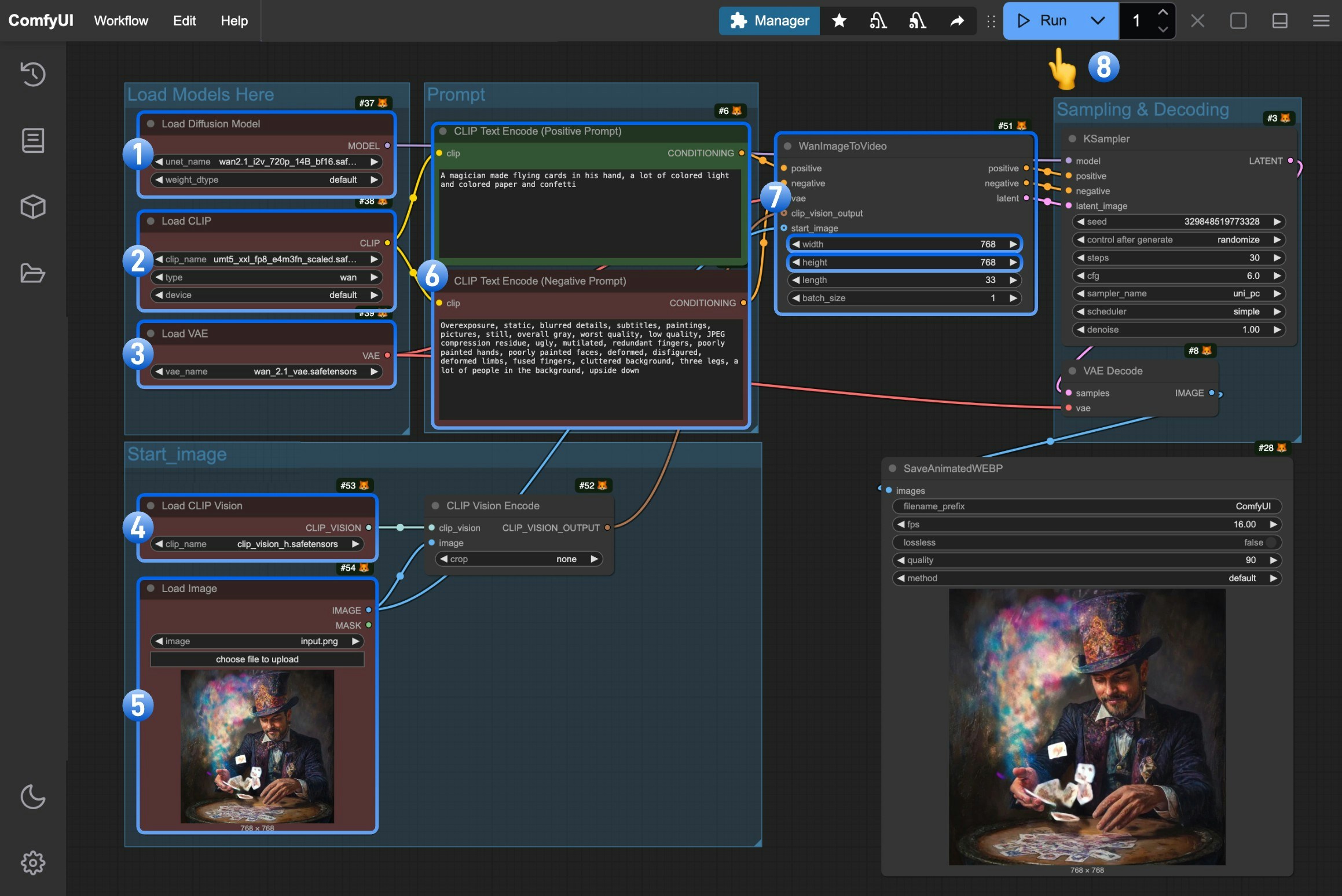
- 确保
Load Diffusion Model节点加载了wan2.1_i2v_720p_14B_fp16.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 确保
Load CLIP Vision节点加载了clip_vision_h.safetensors模型 - 在
Load Image节点中上传我们提供的输入图片 - (可选)在
CLIP Text Encoder节点中输入你想要生成的视频描述内容, - (可选)在
WanImageToVideo节点中设置了视频的尺寸,如果有需要你可以修改 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成