关于 VACE
VACE 14B 是阿里通义万相团队推出的开源视频编辑统一模型。该模型通过整合多任务能力、支持高分辨率处理及灵活的多模态输入机制,显著提升了视频创作的效率与质量。 该模型基于 Apache-2.0 协议开源,可用于个人或商业用途。 以下是其核心特性与技术亮点的综合分析:- 多模态输入:支持文本、图像、视频、遮罩、控制信号等多种输入形式
- 统一架构:单一模型支持多种任务,可自由组合功能
- 动作迁移:基于参考视频生成连贯动作
- 局部替换:通过遮罩替换视频中的特定区域
- 视频扩展:补全动作或扩展背景
- 背景替换:保留主体更换环境背景
相关模型权重和代码仓库:
模型下载及在工作流中的加载
由于本篇文档中涉及的几个工作流都使用同一套工作流模板,所以我们可以先完成模型下载及加载的信息介绍,然后通过 Bypass 不同的节点来启用/禁用不同的输入来实现不同的工作流。 在具体示例中对应的工作流信息中已经嵌入了模型下载信息,所以你也可以在下载具体示例的工作流时来完成模型下载。模型下载
diffusion_models wan2.1_vace_14B_fp16.safetensors wan2.1_vace_1.3B_fp16.safetensors VAE 从Text encoders 选择一个版本进行下载 文件保存位置模型加载
由于本指南涵盖的工作流中使用的模型一致,工作流也相同,仅通过 Bypass 不同节点来启用/禁用不同的输入,请参考以下图片,确保在不同的工作流中正确加载了相应的模型。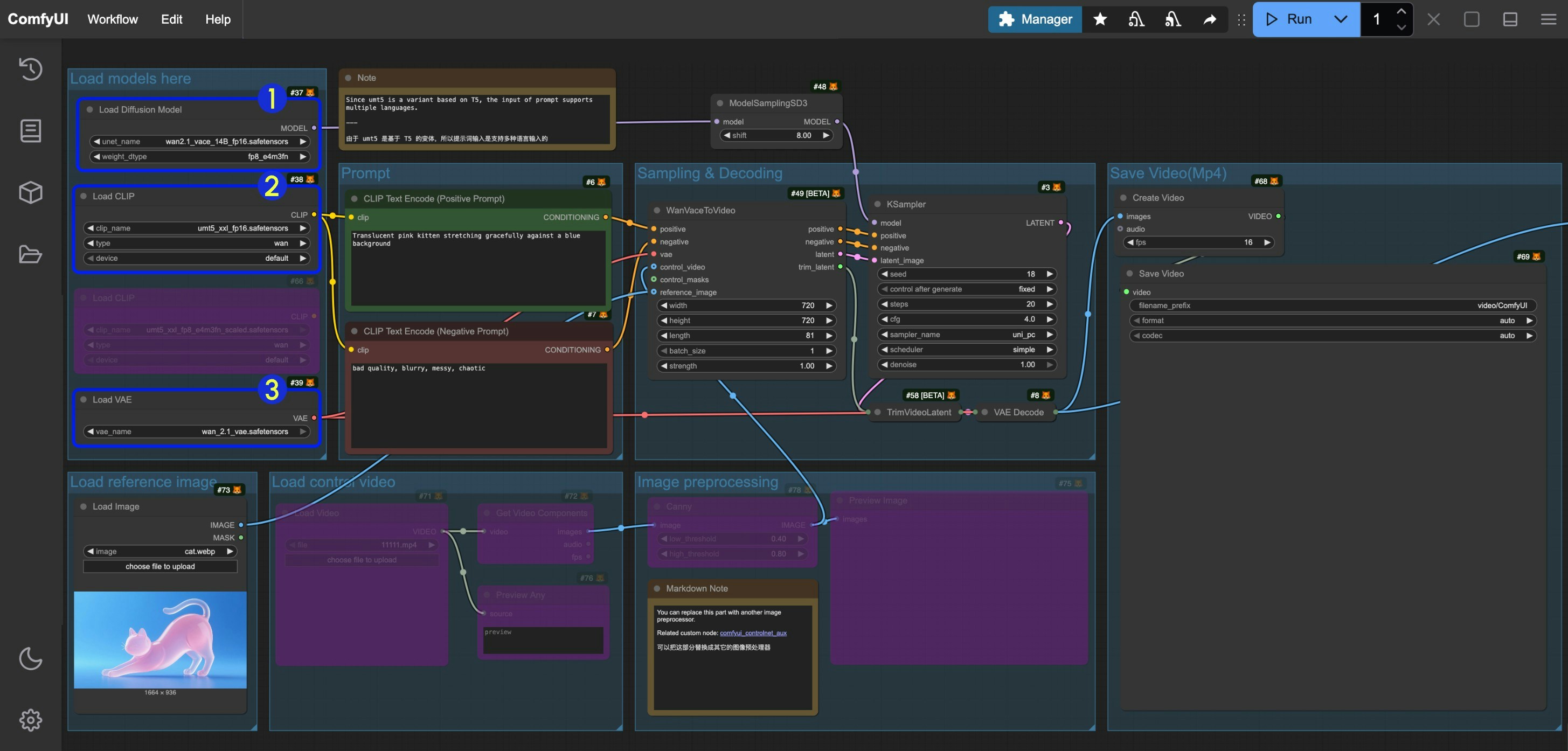
- 确保
Load Diffusion Model节点加载了wan2.1_vace_14B_fp16.safetensors - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors或者umt5_xxl_fp16.safetensors - 确保
Load VAE节点加载了wan_2.1_vae.safetensors
如何取消节点的 Bypass 状态
当一个节点被设置为 Bypass 状态时,通过该节点的数据将不受节点的影响,直接输出,下面是如何取消节点的 Bypass 状态的三种方法 我们通常在不需要一些节点时设置节点的 Bypass 状态,而不用将它们从节点中删除改变工作流。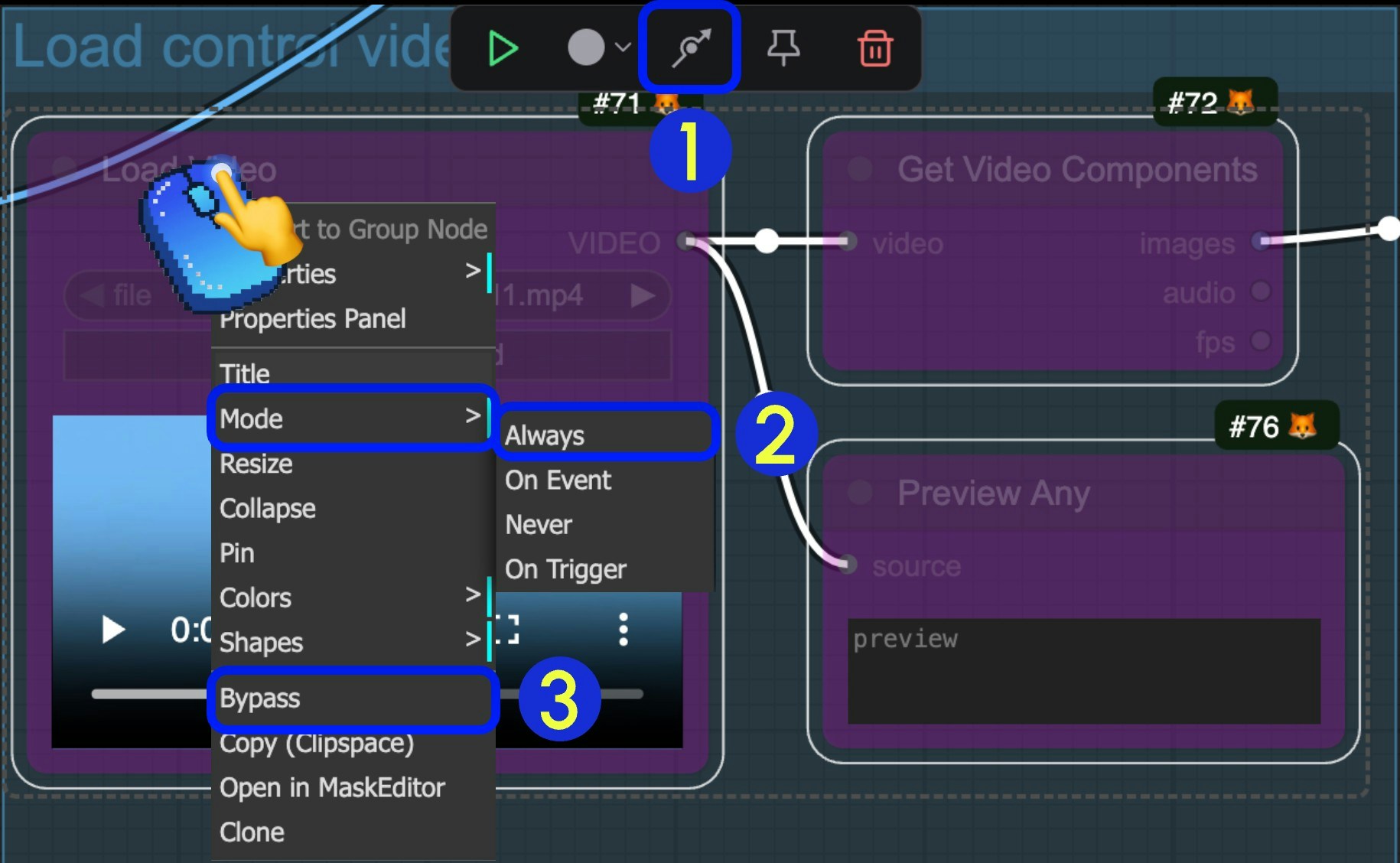
- 选中节点后,在选择工具箱中点击标识部分的箭头,即可快速切换节点的 Bypass 状态
- 选中节点后,鼠标右键点击节点,选择
模式(Mode)->总是(Always)切换到 Always 模式 - 选中节点后,鼠标右键点击节点,选择
绕过(Bypass)选项,切换 Bypass 状态
VACE 文生视频工作流
1. 工作流下载
下载下面视频,并拖入 ComfyUI 中,以加载对应的工作流2. 按步骤完成工作流的运行
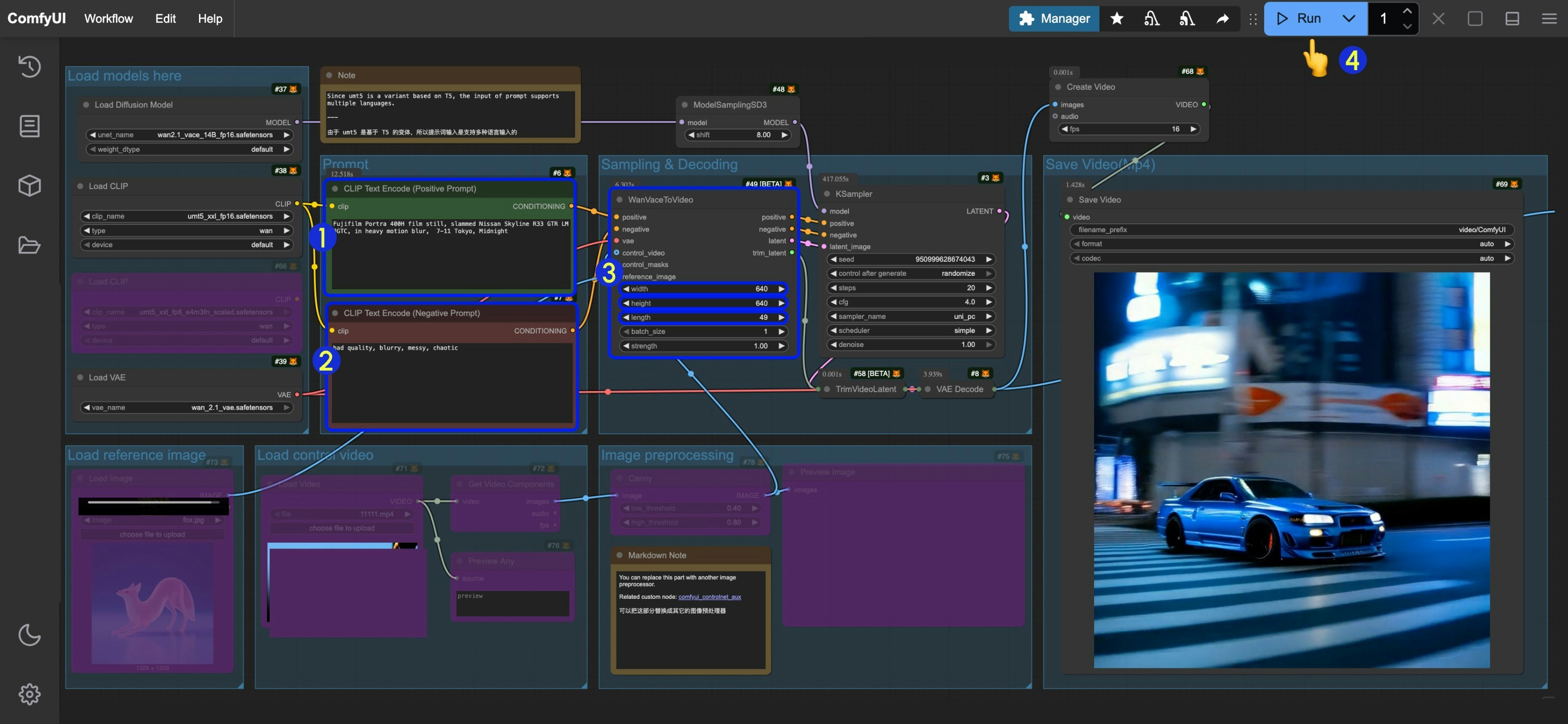
- 在
CLIP Text Encode (Positive Prompt)节点中输入正向提示词 - 在
CLIP Text Encode (Negative Prompt)节点中输入负向提示词 - 在
WanVaceToVideo设置对应图像的尺寸(首次运行建议设置 640*640 的分辨率),帧数(视频的时长) - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成 - 生成完成后对应的视频会自动保存到
ComfyUI/output/video目录下(子文件夹位置取决于save video节点设置)
VACE 图生视频工作流
你可以继续使用上面的工作流文件,只需要将 Load reference image 的Load image 节点的 Bypass 取消,并输入对应的图片,你也可以使用下面的图片,在这个文件里,我们已经完成了对应的参数设置。
1. 工作流下载
下载下面的视频,并拖入 ComfyUI 中,以加载对应的工作流 请下载下面图片作为输入图片
2. 按步骤完成工作流的运行
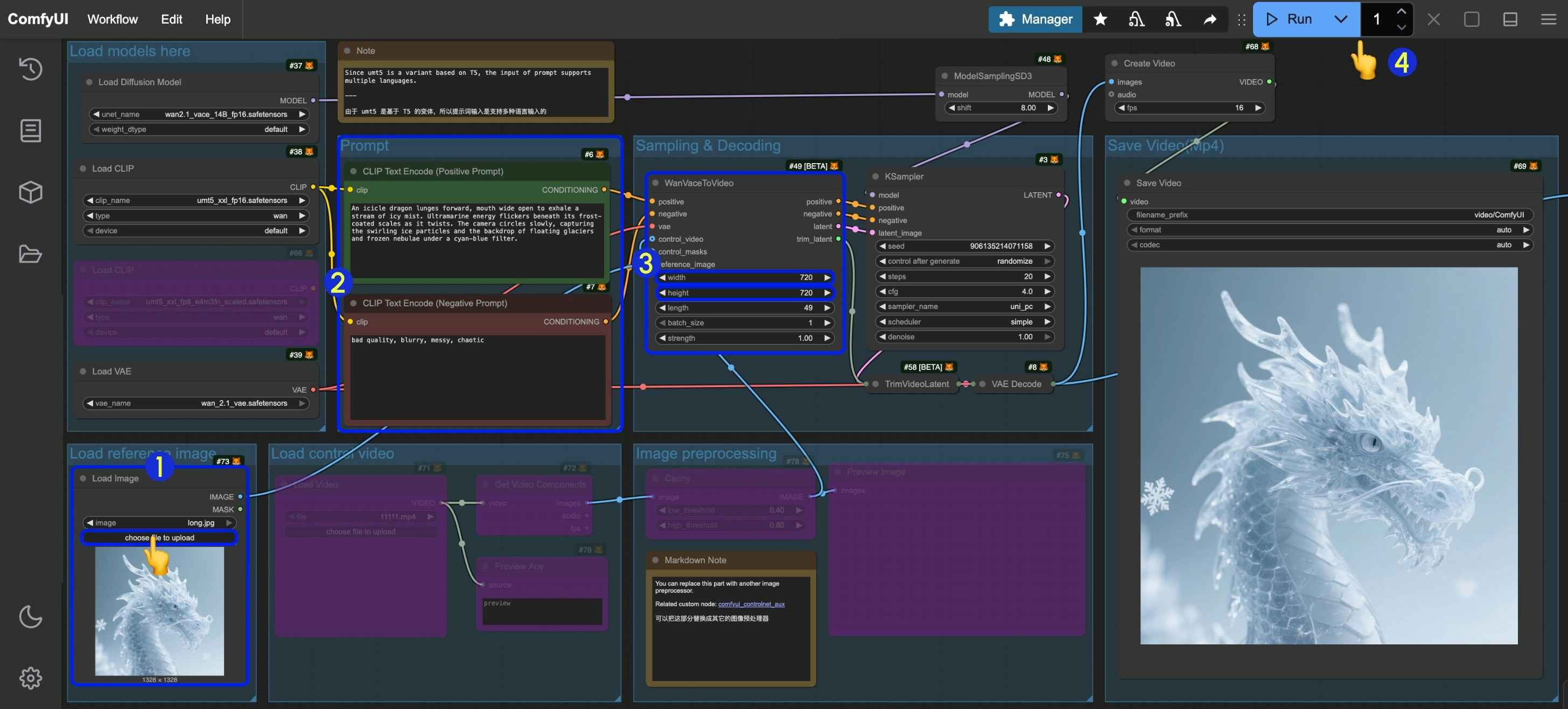
- 在
Load image节点中输入对应的图片 - 你可以像文生图工作流一样完成提示词的修改和编辑
- 在
WanVaceToVideo设置对应图像的尺寸(首次运行建议设置 640*640 的分辨率),帧数(视频的时长) - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成 - 生成完成后对应的视频会自动保存到
ComfyUI/output/video目录下(子文件夹位置取决于save video节点设置)
3. 工作流补充说明
VACE 还支持在一张图像中输入多个参考图像,来生成对应的视频,你可以在 VACE 的项目页中看到相关的示例VACE 视频到视频工作流
1. 工作流下载
下载下面的视频并拖入 ComfyUI 中,以加载对应的工作流 我们将使用下面的素材作为输入:-
用于参考图像的输入图片

- 下面的视频已经经过预处理,我们将用于控制视频的生成
- 下面的视频是原始视频,你可以下载下面的素材来使用类似 comfyui_controlnet_aux 这样的预处理节点来对图像进行预处理
2. 按步骤完成工作流的运行
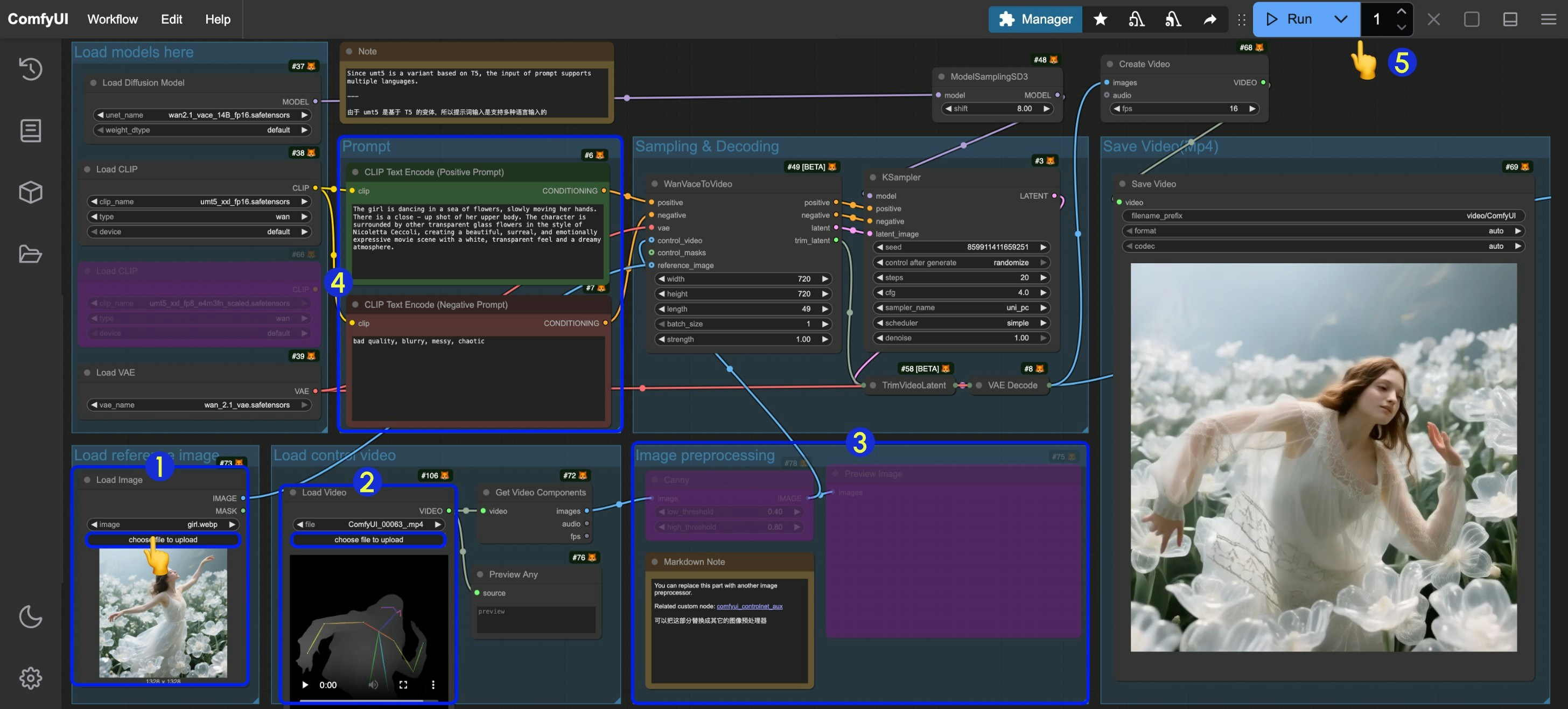
- 在
Load reference image中的Load Image节点输入参考图片 - 在
Load control video中的Load Video节点输入控制视频,由于提供的视频是经过预处理的,所以你不需要进行额外的处理 - 如果你需要自己针对原始视频进行预处理,可以修改
Image preprocessing分组,或者使用comfyui_controlnet_aux节点来完成对应的节点预处理 - 修改提示词
- 在
WanVaceToVideo设置对应图像的尺寸(首次运行建议设置 640*640 的分辨率),帧数(视频的时长) - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成 - 生成完成后对应的视频会自动保存到
ComfyUI/output/video目录下(子文件夹位置取决于save video节点设置)
VACE 视频 Outpainting 工作流
[待更新]VACE 首尾帧视频生成
[待更新] 要保证首尾帧生效,需要满足:- 对应视频
length设置需要满足length-1后能够被4整除 - 对应的
Batch_size设置需要满足Batch_size = length - 2
相关节点文档
请查阅下面的文档了解相关的节点WanVaceToVideo 节点文档
WanVaceToVideo 节点文档
TrimVideoLatent 节点文档
ComfyUI TrimVideoLatent 节点文档