主要特性
- 统一运动控制:支持物体、局部、摄像机等多种运动类型的轨迹控制。
- 交互式轨迹编辑器:可视化工具,用户可在图片上自由绘制、编辑运动轨迹。
- 兼容 Wan2.1:基于 Wan2.1 官方实现,环境和模型结构兼容。
- 丰富的可视化工具:支持输入轨迹、输出视频及轨迹可视化。
WAN ATI 轨迹控制工作流示例
1. 工作流下载
下载下面的视频并拖入 ComfyUI 中,以加载对应的工作流 我们将使用下面的素材作为输入:
2. 模型下载
如果你没有成功下载工作流中的模型文件,可以尝试使用下面的链接手动下载 Diffusion Model VAE Text encoders Chose one of following model clip_vision File save location3. 按步骤完成工作流的运行
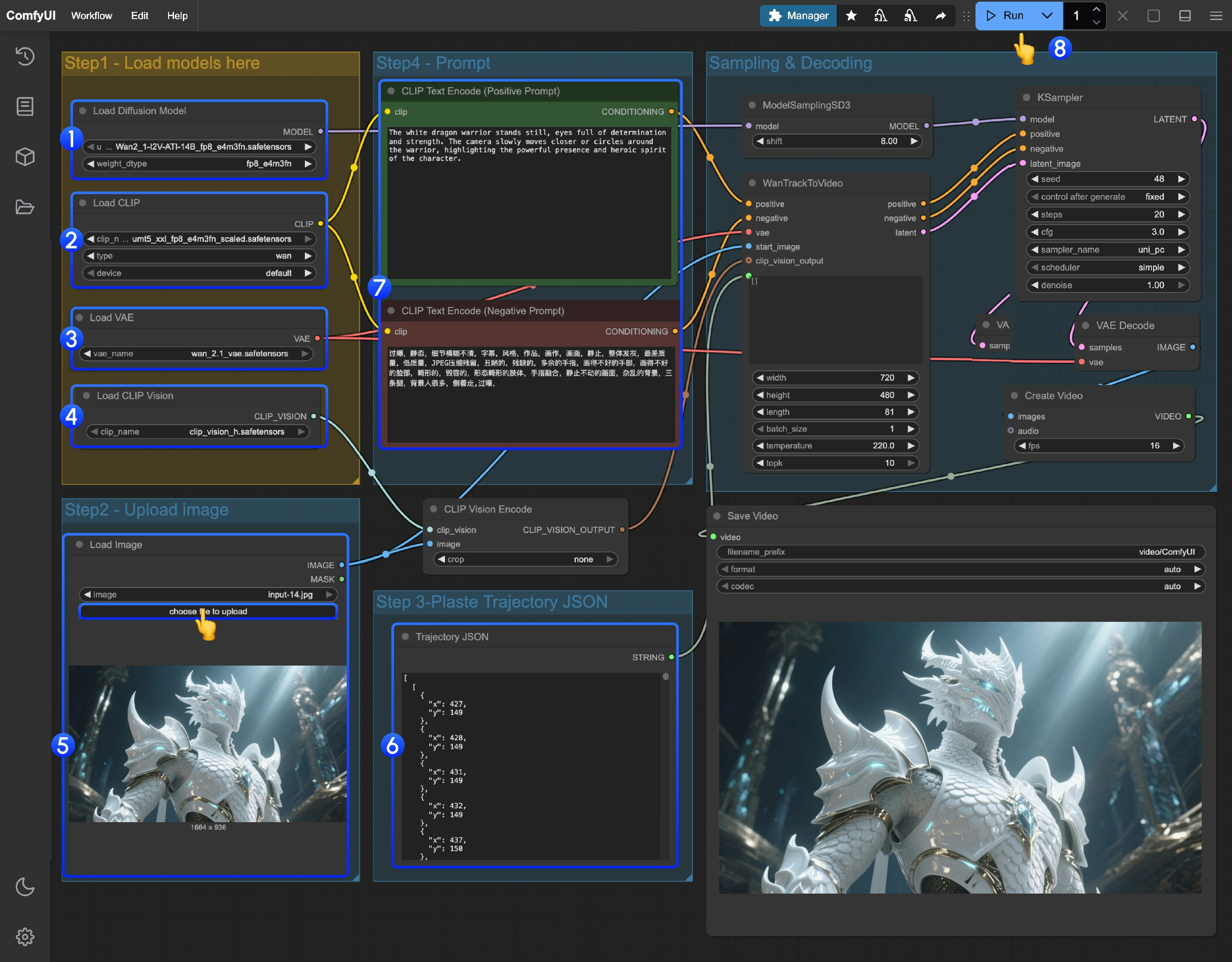
- 确保
Load Diffusion Model节点加载了Wan2_1-I2V-ATI-14B_fp8_e4m3fn.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 确保
Load CLIP Vision节点加载了clip_vision_h.safetensors模型 - 在
Load Image节点上传提供的输入图片 - 轨迹编辑: 目前 ComfyUI 中还未有对应的轨迹编辑器,你可以使用下面的链接来完成轨迹编辑
- 如果你需要修改提示词(正向及负向)请在序号
5的CLIP Text Encoder节点中进行修改 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成