参照画像が指定された場合、その画像が動画生成の初期参照として使用されます。また、制御動画およびマスクを活用することで生成プロセスを制御し、期待通りの結果を得やすくなります。
パラメーター説明
必須パラメーター
| パラメーター | 型 | デフォルト値 | 範囲 | 説明 |
|---|---|---|---|---|
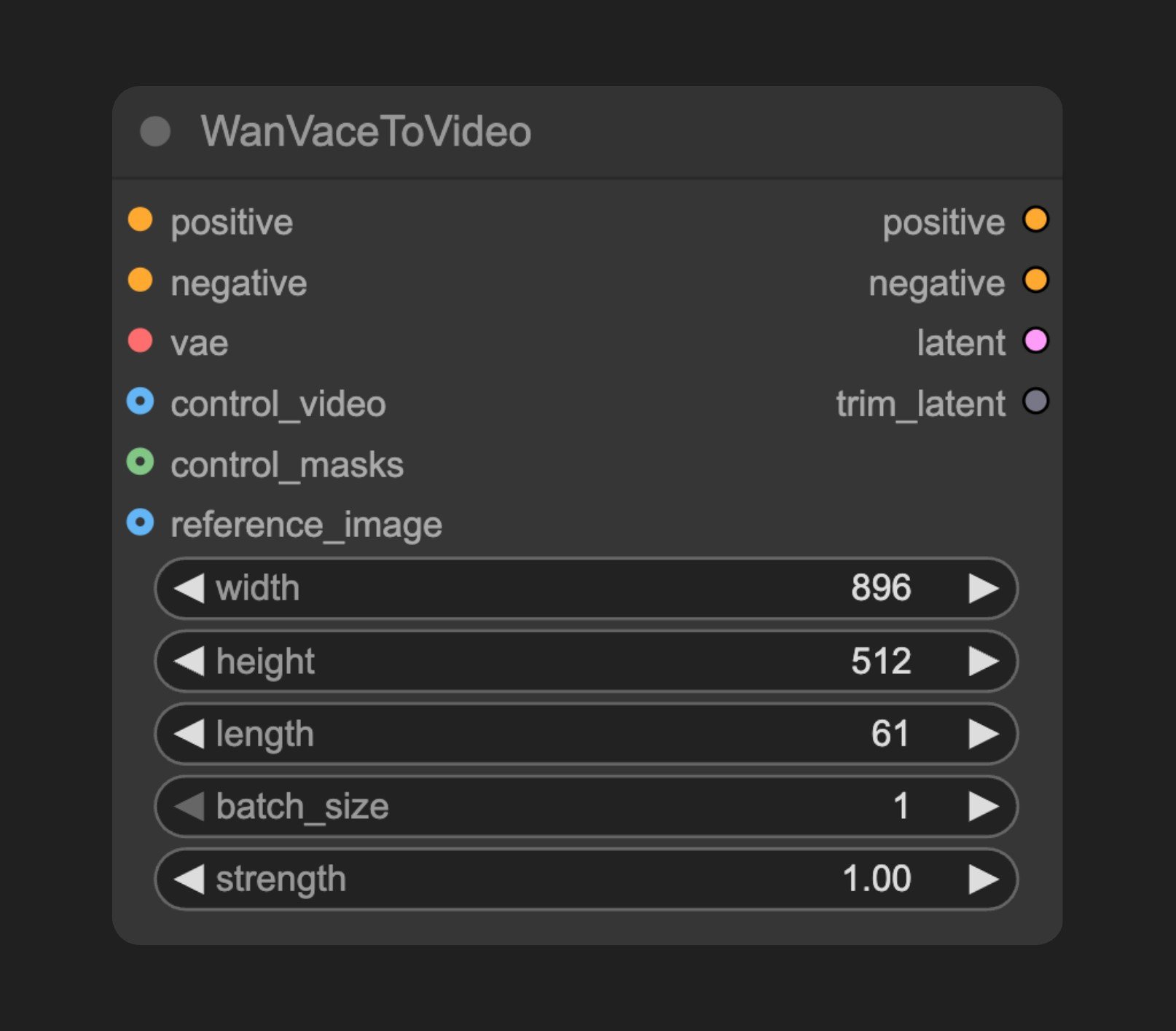
| positive | CONDITIONING | - | - | ポジティブプロンプト条件 |
| negative | CONDITIONING | - | - | ネガティブプロンプト条件 |
| vae | VAE | - | - | エンコード/デコード用の VAE モデル |
| width | INT | 832 | 16–MAX_RESOLUTION | 動画の幅(ステップサイズ:16) |
| height | INT | 480 | 16–MAX_RESOLUTION | 動画の高さ(ステップサイズ:16) |
| length | INT | 81 | 1–MAX_RESOLUTION | 動画のフレーム数(ステップサイズ:4) |
| batch_size | INT | 1 | 1–4096 | バッチサイズ |
| strength | FLOAT | 1.0 | 0.0–1000.0 | 条件の強さ(ステップサイズ:0.01) |
オプションパラメーター
| パラメーター | 型 | 説明 |
|---|---|---|
| control_video | IMAGE | 生成プロセスを制御するための制御動画 |
| control_masks | MASK | 制御対象となる領域を定義する制御マスク |
| reference_image | IMAGE | 動画生成の開始点または参照として使用する画像(単一画像) |
出力パラメーター
| パラメーター | 型 | 説明 |
|---|---|---|
| positive | CONDITIONING | 処理済みのポジティブプロンプト条件 |
| negative | CONDITIONING | 処理済みのネガティブプロンプト条件 |
| latent | LATENT | 生成された動画の潜在表現 |
| trim_latent | INT | 潜在表現をトリミングするためのパラメーター(デフォルト値:0)。参照画像が指定された場合、この値は参照画像の潜在空間における形状サイズに設定されます。これは、後続ノードが生成された潜在表現から参照画像由来のコンテンツをどれだけ削除すべきかを示すものであり、最終的な動画出力において参照画像の影響を適切に制御するために必要です。 |
ソースコード
[ソースコード更新日時: 2025-05-15]class WanVaceToVideo:
@classmethod
def INPUT_TYPES(s):
return {"required": {"positive": ("CONDITIONING", ),
"negative": ("CONDITIONING", ),
"vae": ("VAE", ),
"width": ("INT", {"default": 832, "min": 16, "max": nodes.MAX_RESOLUTION, "step": 16}),
"height": ("INT", {"default": 480, "min": 16, "max": nodes.MAX_RESOLUTION, "step": 16}),
"length": ("INT", {"default": 81, "min": 1, "max": nodes.MAX_RESOLUTION, "step": 4}),
"batch_size": ("INT", {"default": 1, "min": 1, "max": 4096}),
"strength": ("FLOAT", {"default": 1.0, "min": 0.0, "max": 1000.0, "step": 0.01}),
},
"optional": {"control_video": ("IMAGE", ),
"control_masks": ("MASK", ),
"reference_image": ("IMAGE", ),
}}
RETURN_TYPES = ("CONDITIONING", "CONDITIONING", "LATENT", "INT")
RETURN_NAMES = ("positive", "negative", "latent", "trim_latent")
FUNCTION = "encode"
CATEGORY = "conditioning/video_models"
EXPERIMENTAL = True
def encode(self, positive, negative, vae, width, height, length, batch_size, strength, control_video=None, control_masks=None, reference_image=None):
latent_length = ((length - 1) // 4) + 1
if control_video is not None:
control_video = comfy.utils.common_upscale(control_video[:length].movedim(-1, 1), width, height, "bilinear", "center").movedim(1, -1)
if control_video.shape[0] < length:
control_video = torch.nn.functional.pad(control_video, (0, 0, 0, 0, 0, 0, 0, length - control_video.shape[0]), value=0.5)
else:
control_video = torch.ones((length, height, width, 3)) * 0.5
if reference_image is not None:
reference_image = comfy.utils.common_upscale(reference_image[:1].movedim(-1, 1), width, height, "bilinear", "center").movedim(1, -1)
reference_image = vae.encode(reference_image[:, :, :, :3])
reference_image = torch.cat([reference_image, comfy.latent_formats.Wan21().process_out(torch.zeros_like(reference_image))], dim=1)
if control_masks is None:
mask = torch.ones((length, height, width, 1))
else:
mask = control_masks
if mask.ndim == 3:
mask = mask.unsqueeze(1)
mask = comfy.utils.common_upscale(mask[:length], width, height, "bilinear", "center").movedim(1, -1)
if mask.shape[0] < length:
mask = torch.nn.functional.pad(mask, (0, 0, 0, 0, 0, 0, 0, length - mask.shape[0]), value=1.0)
control_video = control_video - 0.5
inactive = (control_video * (1 - mask)) + 0.5
reactive = (control_video * mask) + 0.5
inactive = vae.encode(inactive[:, :, :, :3])
reactive = vae.encode(reactive[:, :, :, :3])
control_video_latent = torch.cat((inactive, reactive), dim=1)
if reference_image is not None:
control_video_latent = torch.cat((reference_image, control_video_latent), dim=2)
vae_stride = 8
height_mask = height // vae_stride
width_mask = width // vae_stride
mask = mask.view(length, height_mask, vae_stride, width_mask, vae_stride)
mask = mask.permute(2, 4, 0, 1, 3)
mask = mask.reshape(vae_stride * vae_stride, length, height_mask, width_mask)
mask = torch.nn.functional.interpolate(mask.unsqueeze(0), size=(latent_length, height_mask, width_mask), mode='nearest-exact').squeeze(0)
trim_latent = 0
if reference_image is not None:
mask_pad = torch.zeros_like(mask[:, :reference_image.shape[2], :, :])
mask = torch.cat((mask_pad, mask), dim=1)
latent_length += reference_image.shape[2]
trim_latent = reference_image.shape[2]
mask = mask.unsqueeze(0)
positive = node_helpers.conditioning_set_values(positive, {"vace_frames": control_video_latent, "vace_mask": mask, "vace_strength": strength})
negative = node_helpers.conditioning_set_values(negative, {"vace_frames": control_video_latent, "vace_mask": mask, "vace_strength": strength})
latent = torch.zeros([batch_size, 16, latent_length, height // 8, width // 8], device=comfy.model_management.intermediate_device())
out_latent = {}
out_latent["samples"] = latent
return (positive, negative, out_latent, trim_latent)